ポインタと文字列処理
C言語でのポインター
#include <stdio.h>
int main() {
int x = 123 ; // px [ 〇 ]
int* px ; // px はポインタ ↓
px = &x ; // x の変数の番地を px に代入 x [ 123 ]
*px = 321 ; // px の指し示す場所に 321 を代入
printf( "%d\n" , x ) ; // 321 を出力
return 0 ;
}
値渡し(pass by value)
// 値渡しのプログラム
void foo( int x ) { // x は局所変数(仮引数は呼出時に
// 対応する実引数で初期化される。
x++ ;
printf( "%d¥n" , x ) ;
}
int main() {
int a = 123 ;
foo( a ) ; // 124
// 処理後も main::a は 123 のまま。
foo( a ) ; // 124
return 0 ;
}
このプログラムでは、aの値は変化せずに、124,124 が表示される。
でも、プログラムによっては、124,125 と変化して欲しい場合もある。
どのように記述すべきだろうか?
// 大域変数を使う場合
int x ;
void foo() {
x++ ;
printf( "%d¥n" , x ) ;
}
int main() {
x = 123 ;
foo() ; // 124
foo() ; // 125
return 0 ;
}
しかし、このプログラムは大域変数を使うために、間違いを引き起こしやすい。
// 大域変数が原因で予想外の挙動をしめす簡単な例
int i ;
void foo() {
for( i = 0 ; i < 2 ; i++ )
printf( "A" ) ;
}
int main() {
for( i = 0 ; i < 3 ; i++ ) // このプログラムでは、AA AA AA と
foo() ; // 表示されない。
return 0 ;
}
ポインタ渡し(pass by pointer)
C言語で引数を通して、呼び出し側の値を変化して欲しい場合は、変更して欲しい変数のアドレスを渡し、関数側では、ポインタ変数を使って受け取った変数のアドレスの示す場所の値を操作する。
// ポインタ渡しのプログラム
void foo( int* p ) { // p はポインタ
(*p)++ ;
printf( "%d¥n" , *p ) ;
}
int main() {
int a = 123 ;
foo( &a ) ; // 124
// 処理後 main::a は 124 に増えている。
foo( &a ) ; // 124
return 0 ; // さらに125と増える
}
ポインタを利用して引数に副作用を与える方法は、ポインタを正しく理解していないプログラマーでは、危険な操作となる。C++では、ポインタ渡しを極力使わないようにするために、参照渡しを利用する。ただし、ポインタ渡しも参照渡しも、機械語レベルでは同じ処理にすぎない。
参照渡し(pass by reference)
// ポインタ渡しのプログラム void foo( int& x ) { // xは参照 x++ ; printf( "%d¥n" , x ) ; } int main() { int a = 123 ; foo( a ) ; // 124 // 処理後 main::a は 124 に増えている。 foo( a ) ; // 124 return 0 ; // さらに125と増える。 }
ポインタの加算と配列アドレス
ポインタに整数値を加えることは、アクセスする場所が、指定された分だけ後ろにずれることを意味する。
// ポインタ加算の例
int a[ 5 ] = { 11 , 22 , 33 , 44 , 55 } ;
void main() {
int* p ;
// p∇
p = &a[2] ; // a[] : 11,22,33,44,55
// -2 +0 +1
printf( "%d¥n" , *p ) ; // 33 p[0]
printf( "%d¥n" , *(p+1) ) ; // 44 p[1]
printf( "%d¥n" , *(p-2) ) ; // 11 p[-2]
p = a ; // p∇
printf( "%d¥n" , *p ) ; // a[] : 11,22,33,44,55
p++ ; // → p∇
printf( "%d¥n" , *p ) ; // a[] : 11,22,33,44,55
p += 2 ; // → → p∇
printf( "%d¥n" , *p ) ; // a[] : 11,22,33,44,55
}
ここで、注意すべき点は、ポインタの加算した場所の参照と、配列の参照は同じ意味となる。
*(p + 整数式) と p[ 整数式 ] は同じ意味 (参照”悪趣味なプログラム”)
特に配列 a[] の a だけを記述すると、配列の先頭を意味することに注意。
ポインタと文字列処理
#include <stdio.h>
void my_tolower( char d[] , char s[] ) {
for( int i = 0 ; s[i] != '\0' ; i++ )
if ( 'A' <= s[i] && s[i] <= 'Z' )
d[i] = s[i] - 'A' + 'a' ;
else
d[i] = s[i] ;
}
int main(void){
char str[ 20 ] ;
my_tolower( str , "AaBcDeF Hoge" ) ;
printf( "%s\n" , str ) ;
return 0 ;
}
間違ったプログラム
C言語の面倒な点は、データがどのように格納されるのかを考えないと正しく動かない所であろう。
下記のプログラムの問題点がわかるだろうか?
#include <stdio.h>
// 前述の my_tolower と同じ
void my_tolower( char d[] , char s[] ) {
for( int i = 0 ; s[i] != '\0' ; i++ )
if ( 'A' <= s[i] && s[i] <= 'Z' )
d[i] = s[i] - 'A' + 'a' ;
else
d[i] = s[i] ;
}
// 引数に副作用のある my_tolower
char* my_tolower_1( char s[] ) {
for( int i = 0 ; s[i] != '\0' ; i++ )
if ( 'A' <= s[i] && s[i] <= 'Z' )
s[i] = s[i] - 'A' + 'a' ;
else
s[i] = s[i] ;
return s ;
}
// 局所変数のメモリを帰してはダメ
char* my_tolower_2( char s[] ) {
char str[ 20 ] ;
for( int i = 0 ; s[i] != '\0' ; i++ )
if ( 'A' <= s[i] && s[i] <= 'Z' )
str[i] = s[i] - 'A' + 'a' ;
else
str[i] = s[i] ;
// printf( "in my_tolower_2 : %s\n" , str ) ;
return str ;
}
int main(void) {
char str[ 20 ] = "Hoge" ; ;
// case-1
char* ptr ;
my_tolower( ptr , "Piyo" ) ; // Illegal instruction (core dumped)
// case-2
printf( "%s\n" , my_tolower_1( str ) ) ;
printf( "%s\n" , my_tolower_1( "Fuga" ) ) ; // 小文字にならない
// csse-3
printf( "%s\n" , my_tolower_2( "foo" ) ) ; // ゴミが表示される
return 0 ;
}
ポインタインクリメントと式
C言語では、ポインタを動かしながら処理を行う場合に以下のようなプログラムもよくでてくる。
// string copy 配列のイメージで記載
void strcpy( char d[] , char s[] ) {
int i ;
for( i = 0 ; s[ i ] != '\0' ; i++ )
d[ i ] = s[ i ] ;
d[ i ] = '¥0' ;
}
int main() {
char a[] = "abcde" ;
char b[ 10 ] ;
strcpy( b , a ) ;
printf( "%s\n" , b ) ;
return 0 ;
}
しかし、この strcpy は、ポインタを使って書くと以下のように書ける。
// string copy ポインタのイメージで記載
void strcpy( char* p , char* q ) {
while( *q != '\0' ) {
*p = *q ;
p++ ;
q++ ;
}
*p = '\0' ;
}
// ポインタ加算と代入を一度に書く
void strcpy( char* p , char* q ) {
while( *q != '\0' )
*p++ = *q++ ; // *(p++) = *(q++)
}
// ポインタ加算と代入と'¥0'判定を一度に書く
void strcpy( char* p , char* q ) {
while( (*p++ = *q++) != '\0' ) // while( *p++ = *q++ ) ; でも良い
;
}
値渡しと参照渡しとポインター
Javaでの引数に対する副作用
Javaでのプログラムにおいて、下記のように関数に引数でデータが渡された場合、呼び出し元の変数が変化する/変化しないの違いが分かるであろうか?
import java.util.*;
class A {
private int a ;
public A( int x ) { a = x ; }
public void set( int x ) { a = x ; }
public int get() { return a ; }
}
public class Main {
public static void foo( int x , Integer y , String s , int z[] , A a ) {
x = 12345 ; // プリミティブな引数の書き換え
y = 23456 ; // イミュータブルな引数の書き換え
s = "hoge" ;
z[0] = 34567 ; // 参照で渡されたオブジェクトの書き換え
a.set( 45678 ) ;
}
public static void main(String[] args) throws Exception {
int mx = 11111 ; // プリミティブなデータ
Integer my = 22222 ; // イミュータブルなオブジェクト
String ms = "aaa" ;
int mz[] = { 33333 } ; // それ以外のオブジェクト
A ma = new A( 44444 ) ;
foo( mx , my , ms , mz , ma ) ;
System.out.println( "mx="+mx+",my="+my+",ms="+ms+",mz[0]="+mz[0]+",ma="+ma.get() );
}
}
上記のプログラムでは、foo() の第1引数 mx は、プリミティブ型なので関数の引数に渡される際には、コピーが生成されて渡されるため、呼び出し元の変数 mx の値は変化していない。
Javaでは、プリミティブ型以外のデータは、ヒープ領域に実体が保存され、そのデータの場所(ポインタ)によって管理される。
しかし、Integer型のオブジェクト my や、String型のオブジェクト ms は、参照(データの場所)が渡されるが、イミュータブルな(変更できない)オブジェクトなので、値の代入が発生すると新しいオブジェクトが生成され、そのアドレスが参照を保存している変数(ポインタ)に代入される。このため、呼び出し元の my や ms は値が変化しない。
これに対し、配列 mz や クラスオブジェクト ma は、オブジェクトの中身を関数 foo で値を変更すると、呼び出し元の変数の内容が変更される。こういった関数やメソッドの呼び出しによって、呼び出し元の値が変化することは「副作用」と呼ばれる。
こういった参照のメカニズムは、データの管理の仕方を正しく理解する必要があることから、もっと原始的な C 言語にて理解を目指す。
C言語の基礎
#include <stdio.h>
int main() {
int n ;
scanf( "%d" , &n ) ; // 標準入力から整数をnに保存
int m = 1 ;
for( int i = 1 ; i <= n ; i++ )
m *= i ;
printf( "%d! = %d\n" , n , m ) ; //
return 0 ;
}
printf の最初の引数は、表示する際のフォーマットであり、%d の部分には対応する引数の値に置き換えて表示される。
型 | 基数 | 型 | 表示方式 long int %ld | 10進数 %d | double %lf | 固定小数点表示 %f 12.34 int %d | 16進数 %x | float %f | 指数小数点表示 %e 1.234e+1 short int %hd | 8進数 %o | | 固定/指数自動 %g char %c | | printf( "%5.2f" , 1.2345 ) ; □1.23 char[], char* %s | |
// Compile by C++
#include <stdio.h>
int main(void) {
long int x = 123456789L ;
int y = 1234567 ;
short int z = 32767 ;
printf( "%ld %d %hd\n" , x , y , z ) ;
// 123456789 1234567 32767
printf( "%d %x %o\n" , 0x1000 , 32767 , 32767 ) ;
// 4096 7fff 77777
double p = 123.45678L ;
float q = 12.345 ;
printf( "%lf %f\n" , p , q ) ;
// 123.456780 12.345000
printf( "(%lf) (%8.3lf) (%le)\n" , p , p , p ) ;
// (123.456780) ( 123.457) (1.234568e+02)
char c = 0x41 ;
char s[] = "ABCDE" ;
char t[] = { 0x41 , 0x42 , 0x43 , 0x0 } ; // C言語の文字列の末尾には'\0'が必要
printf( "(%c) (%s) (%s)\n" , c , s , t ) ;
// (A) (ABCDE) (ABC)
return 0 ;
}
C言語でのポインター
#include <stdio.h>
int main() {
int x = 123 ; // px [ 〇 ]
int* px ; // px はポインタ ↓
px = &x ; // x の変数の番地を px に代入 x [ 123 ]
*px = 321 ; // px の指し示す場所に 321 を代入
printf( "%d\n" , x ) ; // 321 を出力
return 0 ;
}
ポインタの加算と配列アドレス
ポインタに整数値を加えることは、アクセスする場所が、指定された分だけ後ろにずれることを意味する。
// ポインタ加算の例
int a[ 5 ] = { 11 , 22 , 33 , 44 , 55 } ;
void main() {
int* p ;
// p∇
p = &a[2] ; // a[] : 11,22,33,44,55
// -2 +0 +1
printf( "%d¥n" , *p ) ; // 33 p[0]
printf( "%d¥n" , *(p+1) ) ; // 44 p[1]
printf( "%d¥n" , *(p-2) ) ; // 11 p[-2]
p = a ; // p∇
printf( "%d¥n" , *p ) ; // a[] : 11,22,33,44,55
p++ ; // → p∇
printf( "%d¥n" , *p ) ; // a[] : 11,22,33,44,55
p += 2 ; // → → p∇
printf( "%d¥n" , *p ) ; // a[] : 11,22,33,44,55
}
ここで、注意すべき点は、ポインタの加算した場所の参照と、配列の参照は同じ意味となる。
*(p + 整数式) と p[ 整数式 ] は同じ意味 (参照”悪趣味なプログラム”)
特に配列 a[] の a だけを記述すると、配列の先頭を意味することに注意。
ポインタインクリメントと式
C言語では、ポインタを動かしながら処理を行う場合に以下のようなプログラムもよくでてくる。
// string copy 配列のイメージで記載
void strcpy( char d[] , char s[] ) {
int i ;
for( i = 0 ; s[ i ] != '\0' ; i++ )
d[ i ] = s[ i ] ;
d[ i ] = '¥0' ;
}
int main() {
char a[] = "abcde" ;
char b[ 10 ] ;
strcpy( b , a ) ;
printf( "%s\n" , b ) ;
return 0 ;
}
しかし、この strcpy は、ポインタを使って書くと以下のように書ける。
// string copy ポインタのイメージで記載
void strcpy( char* p , char* q ) {
while( *q != '\0' ) {
*p = *q ;
p++ ;
q++ ;
}
*p = '\0' ;
}
// ポインタ加算と代入を一度に書く
void strcpy( char* p , char* q ) {
while( *q != '\0' )
*p++ = *q++ ; // *(p++) = *(q++)
}
// ポインタ加算と代入と'¥0'判定を一度に書く
void strcpy( char* p , char* q ) {
while( (*p++ = *q++) != '\0' ) // while( *p++ = *q++ ) ; でも良い
;
}
再帰呼び出しと処理時間の見積もり
前回の講義で説明できなかった、オーダーの問題の解説
練習問題
の処理時間を要するアルゴリズム(データ件数が変わっても処理時間は一定)を、オーダー記法で書くとどうなるか?また、このような処理時間となるアルゴリズムの例を答えよ。
- ある処理のデータ数Nに対する処理時間が、
であった場合、オーダー記法で書くとどうなるか?
の処理時間を要するアルゴリズムを、オーダー記法で書くとどうなるか?
(ヒント: ロピタルの定理)
- 1は、O(1)。
- 誤答の例:O(0)と書いちゃうと、T(N)=Tα×0=0になってしまう。
- 事例は、電話番号を、巨大配列の”電話番号”番目の場所に記憶するといった方法。(これはハッシュ法で改めて講義予定)
- 2は、N→∞において、N2 ≪ 2Nなので、O(2N) 。厳密に回答するなら、練習問題3と同様の証明が必要。
- 3の解説
再帰呼び出しの基本
次に、再帰呼び出しを含むような処理の処理時間見積もりについて解説をおこなう。そのまえに、再帰呼出しと簡単な処理の例を説明する。
再帰関数は、自分自身の処理の中に「問題を小さくした」自分自身の呼び出しを含む関数。プログラムには問題が最小となった時の処理があることで、再帰の繰り返しが止まる。
// 階乗 (末尾再帰)
int fact( int x ) {
if ( x <= 1 )
return 1 ;
else
return x * fact( x-1 ) ;
}
// ピラミッド体積 (末尾再帰)
int pyra( int x ) {
if ( x <= 1 )
return 1 ;
else
return x*x + pyra( x-1 ) ;
}
// フィボナッチ数列 (非末尾再帰)
int fib( int x ) {
if ( x <= 2 )
return 1 ;
else
return fib( x-1 ) + fib( x-2 ) ;
}
階乗 fact(N) を求める処理は、以下の様に再帰が進む。(N=5の場合)

また、フィボナッチ数列 fib(N) を求める処理は以下の様に再帰が進む。(N=5の場合)

再帰呼び出しの処理時間
次に、この再帰処理の処理時間を説明する。 最初のfact(),pyra()については、 x=1の時は、関数呼び出し,x<=1,return といった一定の処理時間を要し、T(1)=Ta で表せる。 x>1の時は、関数呼び出し,x<=1,*,x-1,returnの処理(Tb)に加え、x-1の値で再帰を実行する処理時間T(N-1)がかかる。 このことから、 T(N)=Tb=T(N-1)で表せる。
} 再帰方程式
このような、式の定義自体を再帰を使って表した式は再帰方程式(漸化式)と呼ばれる。これを以下のような代入の繰り返しによって解けば、一般式 が得られる。
T(1)=Ta
T(2)=Tb+T(1)=Tb+Ta
T(3)=Tb+T(2)=2×Tb+Ta
:
T(N)=Tb+T(N-1)=Tb + (N-2)×Tb+Ta
一般的に、再帰呼び出しプログラムは(考え方に慣れれば)分かりやすくプログラムが書けるが、プログラムを実行する時には、局所変数や関数の戻り先を覚える必要があり、深い再帰ではメモリ使用量が多くなる。
ただし、fact() や pyra() のような関数は、プログラムの末端で再帰が行われている。(fib()は、再帰の一方が末尾ではない)
このような再帰は、末尾再帰(tail recursion) と呼ばれ、関数呼び出しの return を、再帰処理の先頭への goto 文に書き換えるといった最適化が可能である。言い換えるならば、末尾再帰の処理は繰り返し処理に書き換えが可能である。このため、末尾再帰の処理をループにすれば再帰のメモリ使用量の問題を克服できる。
再帰を含む一般的なプログラム例
ここまでのfact()やpyra()のような処理の再帰方程式は、再帰の度にNの値が1減るものばかりであった。もう少し一般的な再帰呼び出しのプログラムを、再帰方程式で表現し、処理時間を分析してみよう。
以下のプログラムを実行したらどんな値になるであろうか?それを踏まえ、処理時間はどのように表現できるであろうか?
// 分割統治法による配列合計
#include <stdio.h>
int sum( int a[] , int L , int R ) { // 非末尾再帰
// L : 左端のデータ
// R : 右端のデータが入っているの場所+1
if ( R - L == 1 ) {
return a[ L ] ;
} else {
int M = (L + R) / 2 ;
return sum( a , L , M ) + sum( a , M , R ) ;
}
}
int main() {
int array[ 8 ] = {
// L=0 1 2 3 4 5 6 7 R=8
3 , 6 , 9 , 1 , 8 , 2 , 4 , 5 ,
} ;
printf( "%d¥n" , sum( array , 0 , 8 ) ) ;
return 0 ;
}
// 分割統治法による配列合計
import java.util.*;
public class Main {
static int sum( int a[] , int L , int R ) { // 非末尾再帰
// L : 左端のデータ
// R : 右端のデータが入っているの場所+1
if ( R - L == 1 ) {
return a[ L ] ;
} else {
int M = (L + R) / 2 ;
return sum( a , L , M ) + sum( a , M , R ) ;
}
}
public static void main(String[] args) throws Exception {
int array[] = {
// L=0 1 2 3 4 5 6 7 R=8
3 , 6 , 9 , 1 , 8 , 2 , 4 , 5 ,
} ;
System.out.println( sum( array , 0 , array.length ) );
}
}
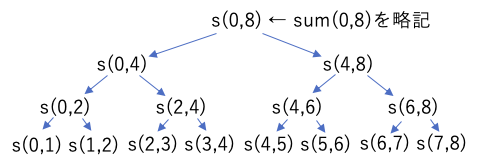
このプログラムでは、配列の合計を計算しているが、引数の L,R は、合計範囲の 左端(左端のデータのある場所)・右端(右端のデータのある場所+1)を表している。そして、再帰のたびに2つに分割して解いている。
このような、処理を(この例では半分に)分割し、分割したそれぞれを再帰で計算し、その処理結果を組み合わせて最終的な結果を求めるような処理方法を、分割統治法と呼ぶ。
このプログラムでは、対象となるデータ件数(R-L)をNとおいた場合、実行される命令からsum()の処理時間Ts(N)は次の再帰方程式で表せる。
← Tβ + (L〜M)の処理時間 + (M〜R)の処理時間
これを代入の繰り返しで解いていくと、
ということで、このプログラムの処理時間は、 で表せる。
ハノイの塔
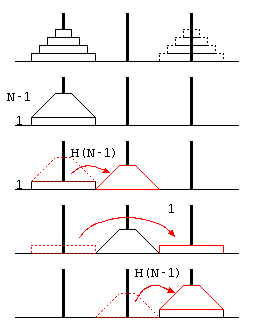 ここまでは、簡単な再帰呼び出しのプログラムを例にして再帰方程式などの説明を行った。次に「ハノイの塔」の処理時間を例題に、プログラムの処理時間について分析を行う。
ここまでは、簡単な再帰呼び出しのプログラムを例にして再帰方程式などの説明を行った。次に「ハノイの塔」の処理時間を例題に、プログラムの処理時間について分析を行う。
ハノイの塔は、3本の塔にN枚のディスクを積み、(1)1回の移動ではディスクを1枚しか動かせない、(2)ディスクの上により大きいディスクを積まない…という条件で、山積みのディスクを目的の山に移動させるパズル。
一般解の予想
ハノイの塔の移動回数を とした場合、 少ない枚数での回数の考察から、 以下の一般式で表せることが予想できる。
… ①
この予想が常に正しいことを証明するために、ハノイの塔の処理を、 最も下のディスク1枚への操作と、その上の(N-1)枚のディスクへの操作に分けて考える。
再帰方程式
上記右の図より、N枚の移動をするためには、上に重なるN-1枚を移動させる必要があるので、
… ②
… ③
ということが言える。(これがハノイの塔の移動回数の再帰方程式)
ディスクが枚の時、予想①が正しいのは明らか①,②。
ディスクが 枚で、予想が正しいと仮定すると、
枚では、
… ③より
… ①を代入
… ①の
の場合
となり、 枚でも、予想が正しいことが証明された。 よって数学的帰納法により、1枚以上で予想が常に成り立つことが証明できた。
また、ハノイの塔の処理時間は、で表せる。
繰り返し処理と処理時間の見積もり
単純サーチの処理時間
ここで、プログラムの実行時間を細かく分析してみる。
// ((case-1))
// 単純サーチ O(N)
#include <stdio.h>
int main() {
int a[ 10 ] = {
12 , 64 , 35 , 29 , 59 , 9 , 83 , 73 , 21 , 61
} ;
int N = 10 ; // 実際のデータ数(Nとする)
int key = 21 ; // 探すデータ
for( int i = 0 ; i < N ; i++ )
if ( a[i] == key )
break ;
return 0 ;
}
import java.util.*;
public class Main {
public static void main(String[] args) throws Exception {
// Your code here!
int a[] = {
12 , 64 , 35 , 29 , 59 , 9 , 83 , 73 , 21 , 61
} ;
int N = a.length ;
int key = 21 ;
for( int i = 0 ; i < N ; i++ )
if( a[i] == key )
break ;
}
}
例えばこの 単純サーチをフローチャートで表せば、以下のように表せるだろう。フローチャートの各部の実行回数は、途中で見つかる場合があるので、最小の場合・最大の場合を考え平均をとってみる。また、その1つ1つの処理は、コンピュータで機械語で動くわけだから、処理時間を要する。この時間を ,
,
,
とする。
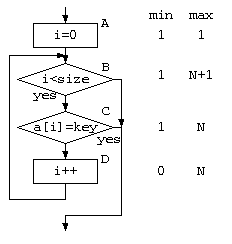
この検索処理全体の時間 を考えると、平均時間とすれば、以下のように表せるだろう。
ここで例題
この単純サーチのプログラムを動かしてみたら、N=1000で、5μ秒かかったとする。では、N=10000であれば、何秒かかるだろうか?
感のいい学生であれば、直感的に 50μ秒 と答えるだろうが、では、Tβ,Tα は何秒だったのだろうか? 上記のT(N)=Tα+N ✕ Tβ に当てはめると、N=1000,T(N)=5μ秒の条件では、連立方程式は解けない。
ここで一番のポイントは、データ処理では N が小さな値の場合(データ件数が少ない状態)はあまり考えない。N が巨大な値であれば、Tαは、1000Tβに比べれば微々たる値という点である。よって
で考えれば良い。これであれば、T(1000)=5μ秒=Tβ×1000 よって、Tβ=5n秒となる。この結果、T(10000)=Tβ×10000=50μ秒 となる。
2分探索法と処理時間
次に、単純サーチよりは、速く・プログラムとしては難しくなった方法として、2分探索法の処理時間を考える。データはあらかじめ昇順に並べておくことで、一度の比較で対象件数を減らすことで高速に探すことができる。
下記プログラムを読む場合の注意点:
- Lは、探索範囲の一番左端のデータのある場所。
- Rは、探索範囲の一番右端のデータのある場所 + 1
// ((case-2))
// 2分探索法 O(log N)
#include <stdio.h>
int main() {
int a[] = {
9 , 12 , 21 , 29 , 35 , 59 , 61 , 64 , 73 , 83
} ;
int L = 0 ; // L : 左端のデータの場所
int R = 10 ; // R : 右端のデータの場所+1
while( L != R ) {
int M = (L + R) / 2 ;
if ( a[M] == key )
break ;
else if ( a[M] < key )
L = M + 1 ;
else
R = M ;
}
return 0 ;
}
import java.util.*;
public class Main {
public static void main(String[] args) throws Exception {
int a[] = {
9 , 12 , 21 , 29 , 35 , 59 , 61 , 64 , 73 , 83
} ;
int L = 0 ; // L : 左端のデータの場所
int R = a.length ; // R : 右端のデータの場所+1
int key = 73 ;
while( L != R ) {
int M = (L + R) / 2 ;
if ( a[M] == key )
break ;
else if ( a[M] < key )
L = M + 1 ;
else
R = M ;
}
}
}
このプログラムでは、1回のループ毎に対象となるデータ件数は、となる。説明を簡単にするために1回毎にN/2件となると考えれば、M回ループ後は、
件となる。データ件数が1件になれば、データは必ず見つかることから、以下の式が成り立つ。
…両辺のlogをとる
2分探索は、繰り返し処理であるから、処理時間は、
… (Mはループ回数)
ここで、本来なら log の底は2であるが、後の見積もりの例では、問題に応じて底変換の公式 ()で係数が出てくるが、これはTβに含めて考えればいい。
単純なソート(選択法)の処理時間
次に、並べ替え処理の処理時間について考える。
単純な並べ替えアルゴリズムとしてはバブルソートなどもあるが、2重ループの内側のループ回数がデータによって変わるので、選択法で考える。
// ((case-3))
// 選択法 O(N^2)
#include <stdio.h>
int main() {
int a[] = {
12 , 64 , 35 , 29 , 59 , 9 , 83 , 73 , 21 , 61
} ;
int size = 10 ;
for( int i = 0 ; i < size - 1 ; i++ ) {
int tmp ;
// i..size-1 の範囲で一番大きいデータの場所を探す
int m = i ;
for( int j = i + 1 ; j < size ; j++ ) {
if ( a[j] > a[m] )
m = j ;
}
// 一番大きいデータを先頭に移動
tmp = a[i] ;
a[i] = a[m] ;
a[m] = tmp ;
}
return 0 ;
}
import java.util.*;
public class Main {
public static void main(String[] args) throws Exception {
int a[] = {
12 , 64 , 35 , 29 , 59 , 9 , 83 , 73 , 21 , 61
} ;
int size = a.length ;
for( int i = 0 ; i < size - 1 ; i++ ) {
int tmp ;
int m = i ;
for( int j = i + 1 ; j < size ; j++ ) {
if ( a[j] > a[m] )
m = j ;
}
tmp = a[i] ;
a[i] = a[m] ;
a[m] = tmp ;
}
}
}
このプログラムの処理時間T(N)は…
… i=0の時
… i=1の時
:
… i=N-1の時
…(参考 数列の和の公式)
となる。
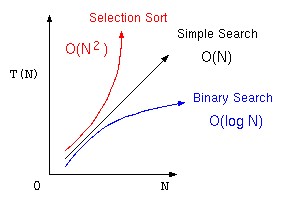
オーダー記法
ここまでのアルゴリズムをまとめると以下の表のようになる。ここで処理時間に大きく影響する部分は、最後の項の部分であり、特にその項の係数は、コンピュータの処理性能に影響を受けるが、アルゴリズムの優劣を考える場合は、それぞれ、
の部分の方が重要である。
| 単純サーチ | |
| 2分探索法 | |
| 最大選択法 |
そこで、アルゴリズムの優劣を議論する場合は、この処理時間の見積もりに最も影響する項で、コンピュータの性能によって決まる係数を除いた部分を抽出した式で表現する。これをオーダー記法と言う。
| 単純サーチ | オーダーNのアルゴリズム | |
| 2分探索法 | オーダー log N のアルゴリズム | |
| 最大選択法 | オーダー N2 のアルゴリズム |
練習問題
- ある処理のデータ数Nに対する処理時間が、
- コンピュータで2分探索法で、データ100件で10[μsec]かかったとする。
データ10000件なら何[sec]かかるか?
(ヒント: 底変換の公式)
(ヒント: ロピタルの定理)
- 2と4の解説
- 1は、N→∞において、N2 ≪ 2Nなので、O(2N) 。厳密に回答するなら、練習問題4と同様の証明が必要。
- 3は、O(1)。
- 誤答の例:O(0)と書いちゃうと、T(N)=Tα×0=0になってしまう。
- 事例は、電話番号を、巨大配列の”電話番号”番目の場所に記憶するといった方法。(これはハッシュ法で改めて講義予定)
2023年度 情報構造論 講義録
- 情報構造論ガイダンス2023
- 繰り返し処理と処理時間の見積もり
- 再帰呼び出しと処理時間の見積もり
- ポインタ処理
- ポインタとメモリの使用効率
- malloc()とfree()
- 様々なデータの覚え方のレポート課題
- fgetsではみ出たら
- リスト構造の導入
- リスト処理
- リストへの追加処理
- スタックと待ち行列
- 集合とリスト処理
- ランダムアクセス・シーケンシャルアクセスから双方向リスト
- 双方向リストとdeque
- 2分探索木
- AVL木と2分ヒープ
- 意思決定木と演算子
- 2分木による構文木とデータベースとB木
- コンパイラと正規表現とBNF記法
- ハッシュ法
- チェイン法と共有のあるデータの問題
- 参照カウンタの問題とガベージコレクタ
- 関数ポインタ
授業アンケート 2023 後期
情報工学演習(2EI)
84.3 ポイントと高い評価であった。プログラミングコンテストを用いた演習内容の発表では、こちらが想定してた難易度の高い問題について説明したものが少なく、来年度は制約などを設けたいと思った。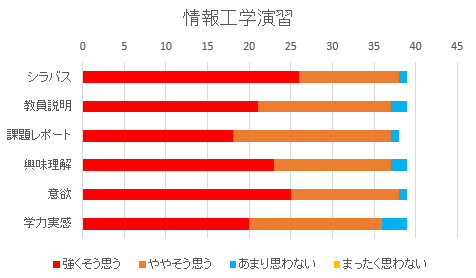
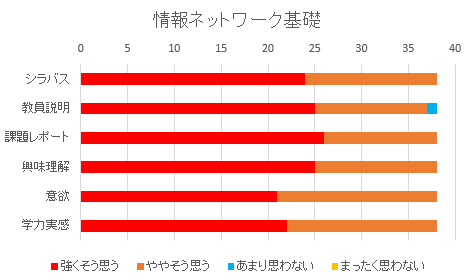
情報ネットワーク基礎(3EI)
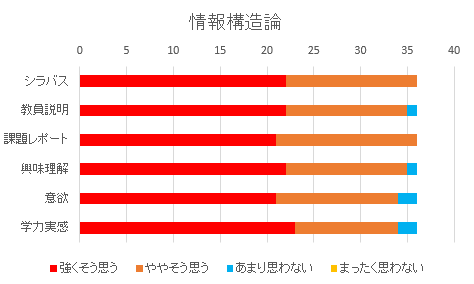
情報構造論(4EI)
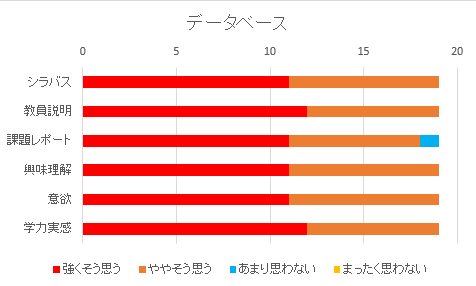
データベース(5EI)
関数ポインタ
関数ポインタとコールバック関数
JavaScript のプログラムで、以下のようなコーディングがよく使われる。このプログラムでは、3と4を加えた結果が出てくるが、関数の引数の中に関数宣言で使われるfunctionキーワードが出てきているが、この意味を正しく理解しているだろうか?
このような (function()…)は、無名関数と呼ばれている。(=>を使った書き方はアロー関数と呼ばれている) これは「関数を引数として渡す機能」と、「一度しか使わないような関数にいちいち名前を付けないで関数を使うための機能」であり、このような機能は、関数を引数で渡す機能はC言語では関数ポインタと呼ばれたり、新しいプログラム言語では一般的にラムダ式などと呼ばれる。
// JavaScriptの無名関数の例 3+4=7 を表示
console.log( (function( x , y ) {
return x + y ;
})( 3 , 4 ) ) ; // 無名関数
console.log( ((x,y) => {
return x + y ;
})( 3 , 4 ) ) ; // アロー関数
C言語の関数ポインタの仕組みを理解するために、以下のプログラムを示す。
int add( int x , int y ) {
return x + y ;
}
int mul( int x , int y ) {
return x * y ;
}
void main() {
int (*f)( int , int ) ; // fは2つのintを引数とする関数へのポインタ
f = add ; // f = add( ... ) ; ではないことに注意
printf( "%d¥n" , (*f)( 3 , 4 ) ) ; // 3+4=7
// f( 3 , 4 ) と書いてもいい
f = mul ;
printf( "%d¥n" , (*f)( 3 , 4 ) ) ; // 3*4=12
}
このプログラムでは、関数ポインタの変数 f を定義している。「 int (*f)( int , int ) ; 」 は、“int型の引数を2つ持つ、返り値がint型の関数”へのポインタであり、「 f = add ; 」では、f に加算する関数addを覚えている。add に実引数を渡す()がないことに注目。C言語であれば、関数ポインタ変数 f には、関数 add の機械語の先頭番地が代入される。
そして、「 (*f)( 3 , 4 ) ; 」により、実引数を3,4にて f の指し示す add を呼び出し、7 が答えとして求まる。
こういう、関数に「自分で作った関数ポインタ」を渡し、その相手側の関数の中で自分で作った関数を呼び出してもらうテクニックは、コールバックとも呼ばれる。コールバック関数を使うC言語の関数で分かり易い物は、クイックソートを行う qsort() 関数だろう。qsort 関数は、引数にデータを比較するための関数を渡すことで、様々な型のデータの並び替えができる。
#include <stdio.h>
#include <stdlib.h>
// 整数を比較するコールバック関数
int cmp_int( int* a , int* b ) {
return *a - *b ;
}
// 実数を比較するコールバック関数
int cmp_double( double* a , double* b ) {
double ans = *a - *b ;
if ( ans == 0.0 )
return 0 ;
else if ( ans > 0.0 )
return 1 ;
else
return -1 ;
}
// ソート対象の配列
int array_int[ 5 ] = { 123 , 23 , 45 , 11 , 53 } ;
double array_double[ 4 ] = { 1.23 , 12.3 , 32.1 , 3.21 } ;
void main() {
// 整数配列をソート
qsort( array_int , 5 , sizeof( int ) ,
(int(*)(const void*,const void*))cmp_int ) ;
// ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~この分かりにくい型キャストが必要なのがC言語の面倒な所
for( int i = 0 ; i < 5 ; i++ )
printf( "%d\n" , array_int[ i ] ) ;
// 実数配列をソート
qsort( array_double , 4 , sizeof( double ) ,
(int(*)(const void*,const void*))cmp_double ) ;
// ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
for( int i = 0 ; i < 5 ; i++ )
printf( "%f\n" , array_double[ i ] ) ;
}
無名関数
コールバック関数を使っていると、データを比較するだけの関数とか簡単な短い処理が使われることが多い。こういった処理を実際に使われる処理と離れた別の場所に記述すると、プログラムが読みづらくなる。この場合には、その場で関数の名前を持たない関数(無名関数)を使用する。(C++の無名関数機能は、最近のC++の文法なのでテストには出さない)
void main() {
int (*f)( int , int ) ; // fは2つのintを引数とする関数へのポインタ
f = []( int x , int y ) { return x + y ; } ; // add を無名関数化
printf( "%d¥n" , (*f)( 3 , 4 ) ) ; // 3+4=7
// mul を無名関数にしてすぐに呼び出す3*4=12
printf( "%d¥n" , []( int x , int y ) { return x * y ; }( 3 , 4 ) ) ;
// メモ:C++11では、ラムダ式=関数オブジェクト
// C++14以降は、変数キャプチャなどの機能が追加されている。
}
C++の変数キャプチャとJavaScriptのクロージャ
JavaScript のクロージャ
JavaScriptにおいて、関数オブジェクトの中で、その周囲(レキシカル環境)の局所変数を参照できる機能をクロージャと呼ぶ。クロージャを使うことでグローバルな変数や関数の多用を押さえ、カプセル化ができることから、保守性が高まる。
// JavaScriptにおけるクロージャ function foo() { let a = 12 ; // 局所変数 console.log( (function( x , y ) { return a + x + y ; // 無名関数の外側の局所変数aを参照できる })( 3 , 4 ) ) ; } foo() ;C++の変数キャプチャ
C++でも無名関数などでクロージャと同様の処理を書くことができるようにするために変数キャプチャという機能がC++14以降で使うことができる。
// C++のラムダ関数における変数キャプチャ void main() { int a = 12 ; printf( "%d\n" , [a]( int x , int y ) { // 変数キャプチャ[a]の部分 return a + x + y ; // 局所変数aをラムダ関数内で参照できる。 }( 3 , 4 ) ) ; return 0 ; }
参照カウンタの問題とガベージコレクタ
前回の授業では、共有のあるデータ構造では、データの解放などで問題が発生することを示し、その解決法として参照カウンタ法などを紹介した。今日は、参照カウンタ法の問題を示した上で、ガベージコレクタなどの説明を行う。
共有のあるデータの取扱の問題
前回の講義を再掲となるが、リスト構造で集合計算おこなう場合の和集合を求める処理を考える。
struct List* join( struct List* a , struct List* b )
{ struct List* ans = b ;
for( ; a != NULL ; a = a->next )
if ( !find( ans , a->data ) )
ans = cons( a->data , ans ) ;
return ans ;
}
void list_del( struct List* p )
{ // ダメなプログラムの例
while( p != NULL ) { // for( ; p != NULL ; p = p->next )
struct List* d = p ; // free( p ) ;
p = p->next ;
free( d ) ;
}
}
void main() {
// リストの生成
struct List* a = cons( 1 , cons( 2 , cons( 3 , NULL ) ) ) ;
struct List* b = cons( 2 , cons( 3 , cons( 4 , NULL ) ) ) ;
struct List* c = join( a , b ) ; // c = { 1, 1, 2, 3 }
// ~~~~~~~ ここは b
// a,b,cを使った処理
// 処理が終わったのでa,b,cを捨てる
list_del( c ) ;
list_del( b ) ;
list_del( a ) ; // list_del(c)ですでに消えている
} // このためメモリー参照エラー発生
このようなプログラムでは、下の図のようなデータ構造が生成されるが、処理が終わってリスト廃棄を行おうとすると、bの先のデータは廃棄済みなのに、list_del(c)の実行時に、その領域を触ろうとして異常が発生する。
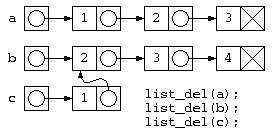
参照カウンタ法
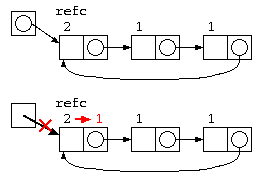
上記の問題は、b の先のリストが c の一部とデータを共有しているために発生する。この解決方法として簡単な方法では、参照カウンタ法が用いられる。
参照カウンタ法では、データを参照するポインタの数をデータと共に保存する。
- データの中にポインタ数を覚える参照カウンタを設け、データを生成した時に1とする。
- 処理の中で共有が発生すると、参照カウンタをカウントアップする。
- データを捨てる際には、参照カウンタをカウントダウンし、0になったら本当にそのデータを消す。
struct List {
int refc ; // 参照カウンタ
int data ; // データ
struct List* next ; // 次のポインタ
} ;
void list_del( strcut List* p ) { // 再帰で全廃棄
if ( p != NULL
&& --(p->refc) <= 0 ) { // 参照カウンタを減らし
list_del( p->next ) ; // 0ならば本当に消す
free( p ) ;
}
}
ただし、参照カウンタ法は、循環リストではカウンタが0にならないので、取扱いが苦手。
ガベージコレクタ
では、循環リストの発生するようなデータで、共有が発生するような場合には、どのようにデータを管理すれば良いだろうか?
最も簡単な方法は、「処理が終わっても使い終わったメモリを返却しない」方法である。ただし、このままでは、メモリを使い切ってしまう。
そこで、廃棄処理をしないまま、ゴミだらけになってしまったメモリ空間を再利用するのが、ガベージコレクタである。
ガベージコレクタは、貸し出すメモリ空間が無くなった時に起動され、
- すべてのメモリ空間に、「不要」の目印をつける。(mark処理)
- 変数に代入されているデータが参照している先のデータは「使用中」の目印をつける。(mark処理)
- その後、「不要」の目印がついている領域は、だれも使っていないので回収する。(sweep処理)
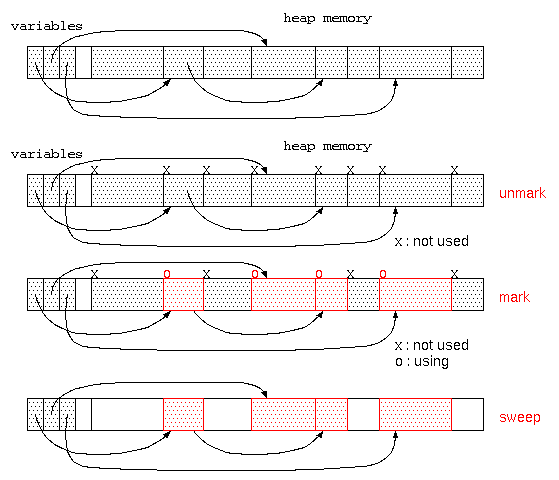
この方式は、マークアンドスイープ法と呼ばれる。ただし、このようなガベージコレクタが動く場合は、他の処理ができず処理が中断されるので、コンピュータの操作性という点では問題となる。
最近のプログラミング言語では、参照カウンタとガベージコレクタを取り混ぜた方式でメモリ管理をする機能が組み込まれている。このようなシステムでは、局所変数のような関数に入った時点で生成され関数終了ですぐに不要となる領域は、参照カウンタで管理し、大域変数のような長期間保管するデータはガベージコレクタで管理される。
大量のメモリ空間で、メモリが枯渇したタイミングでガベージコレクタを実行すると、長い待ち時間となることから、ユーザインタフェースの待ち時間に、ガベージコレクタを少しづつ動かすなどの方式もとることもある。
ガベージコレクタが利用できる場合、メモリ管理を気にする必要はなくなってくる。しかし、初心者が何も気にせずプログラムを書くと、使われないままのメモリがガベージコレクタの起動まで放置され、場合によっては想定外のタイミングでのメモリ不足による処理速度低下の原因となる場合もある。手慣れたプログラマーであれば、素早くメモリを返却するために、使われなくなった変数には積極的に null を代入するなどのテクニックを使う。
プログラム言語とメモリ管理機能
一般的に、C言語というとポインタの概念を理解できないと使えなかったり、メモリ管理をきちんとできなければ危険な言語という点で初心者向きではないと言われている。
C言語は、元々 BCPL や B言語を改良してできたプログラム言語であった。これに、オブジェクト指向の機能を加えた C++ が作られた。C++ という言語の名前は、B言語→C言語と発展したので、D言語(現在はまさにD言語は存在するけど)と名付けようという意見もあったが、C++ を開発したビャーネ・ストロヴストルップは、ガベージコレクタのようなメモリ管理機能が無いことから、D言語を名乗るには不十分ということで、C言語を発展させたものという意味でC++と名付けている。
こういった中で、C++をベースとしたガベージコレクタなどを実装した言語としては、Java が挙げられる。オブジェクト指向をベースとしたマルチスレッドやガベージコレクタに加え、仮想マシンによる実行で様々なOS(やブラウザ)で動かすことができる。
最近注目されている言語の1つとして、C言語の苦手であった「メモリ安全性」や実行効率を考えて開発されたものに Rust が挙げられる。メモリ管理や効率などの性能から、最近では Linux の開発言語に Rust を部分的に導入されている。
C言語でデータが保存される領域は大きく以下の3つに分類される。
- 静的データ領域(大域変数領域)
- スタック領域(局所変数)
- ヒープ領域(malloc(),free()で管理される領域)
2,3は、処理の途中で領域が作られ不要になったら消える領域であり動的メモリ領域という。
局所変数とスタック
局所変数は、関数に入った時に作られるメモリ領域であり、関数の処理を抜けると自動的に開放されるデータ領域である。
関数の中で関数が呼び出されると、スタックに戻り番地情報を保存し、関数に移動する。最初の処理で局所変数領域が確保され、関数を終えると局所変数は開放される。
この局所変数の確保と開放は、最後に確保された領域を最初に開放される(Last In First Out)ことから、スタック上に保存される。
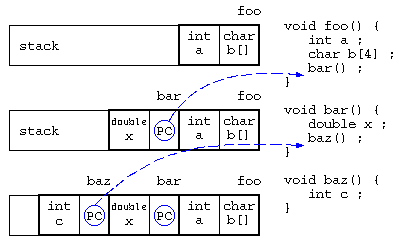
baz()の中で、「*((&c)+8) = 123 ;」を実行したら、bar()のxを書き換えられるかも…(実際の関数呼び出し時に保存される情報はもう少し複雑:コールスタック/Wikipedia)
こういった変数の並び順を悪用し、情報の読み書きを防ぐために、局所変数の保存場所の順序を入れ替えたり、メモリのアドレス空間配置のランダム化などが行われたりする。
チェイン法と共有のあるデータの問題
前回の授業で説明したハッシュ法は、データから簡単な計算(ハッシュ関数)で求まるハッシュ値をデータの記憶場所とする。しかし、異なるデータでも同じハッシュ値が求まった場合、どうすれば良いか?
ハッシュ法を簡単なイメージで説明すると、100個の椅子(ハッシュ表)が用意されていて、1クラスの学生が自分の電話番号の末尾2桁(ハッシュ関数)の場所(ハッシュ値)に座るようなもの。自分のイスに座ろうとしたら、同じハッシュ値の人が先に座っていたら、どこに座るべきだろうか?
オープンアドレス法
先の椅子取りゲームの例え話であれば、先に座っている人がいた場合、最も簡単な椅子に座る方法は、隣が空いているか確認して空いていたらそこに座ればいい。
これをプログラムにしてみると、以下のようになる。このハッシュ法は、求まったアドレスの場所にこだわらない方式でオープンアドレス法と呼ばれる。
// オープンアドレス法
// table[] は大域変数で0で初期化されているものとする。
// 配列に電話番号と名前を保存
void entry( int phone , name ) {
int idx = hash_func( phone ) ;
while( table[ idx ].phone != 0 )
idx = (idx + 1) % HASH_SIZE ; // ひとつ後ろの席
} // idx++ でないのは何故?
table[ idx ].phone = phone ;
strcpy( table[ idx ].name , name ) ;
}
// 電話番号から名前を調べる
char* search( int phone ) {
int idx = hash_func( phone ) ;
while( table[ idx ].phone != 0 ) {
if ( table[ idx ].phone == phone )
return table[ idx ].name ;
idx = (idx + 1) % HASH_SIZE ; // ひとつ後ろの席
} // idx++ でないのは何故?
return NULL ; // 見つからなかった
}
注意:このプログラムは、ハッシュ表すべてにデータが埋まった場合、無限ループとなるので、実際にはもう少し改良が必要である。
この実装方法であれば、ハッシュ表にデータが少ない場合は、ハッシュ値を計算すれば終わり。よって、処理時間のオーダはO(1)となる。しかし、ハッシュ表がほぼ埋まっている状態だと、残りわずかな空き場所を探すようなもの。
チェイン法
前に述べたオープンアドレス法は、ハッシュ衝突が発生した場合、別のハッシュ値を求めそこに格納する。配列で実装した場合であれば、ハッシュ表のサイズ以上の データ件数を保存することはできない。
チェイン法は、同じハッシュ値のデータをグループ化して保存する方法。 同じハッシュ値のデータは、リスト構造とするのが一般的。ハッシュ値を求めたら、そのリスト構造の中からひとつづつ目的のデータを探す処理となる。
この処理にかかる時間は、データ件数が少なければ、O(1) となる。しかし、ハッシュ表のサイズよりかなり多いデータ件数が保存されているのであれば、ハッシュ表の先に平均「N/ハッシュ表サイズ」件のデータがリスト構造で並んでいることになるので、O(N) となってしまう。
#define SIZE 100
int hash_func( int ph ) {
return ph % SIZE ;
}
struct PhoneNameList {
int phone ;
char name[ 20 ] ;
struct PhoneNameList* next ;
} ;
struct PhoneNameList* hash[ SIZE ] ; // NULLで初期化
struct PhoneNameList* cons( int ph ,
char* nm ,
struct PhoneNameList* nx ) {
struct PhoneNameList* ans ;
ans = (struct PhoneNameList*)malloc(
sizeof( struct PhoneNameList ) ) ;
if ( ans != NULL ) {
ans->phone = ph ;
strcpy( ans->name , nm ) ;
ans->next = nx ;
}
return ans ;
}
void entry( int phone , char* name ) {
int idx = hash_func( phone ) ;
hash[ idx ] = cons( phone , name , hash[ idx ] ) ;
}
char* search( int phone ) {
int idx = hash_func( phone ) ;
struct PhoneNameList* p ;
for( p = hash[ idx ] ; p != NULL ; p = p->next ) {
if ( p->phone == phone )
return p->name ;
}
return NULL ;
}
これまでの授業の中では、データを効率よく扱うためのデータ構造について議論をしてきた。これまでのプログラムの中では、データ構造のために動的メモリ(特にヒープメモリ)を多用してきた。ヒープメモリでは、malloc() 関数により指定サイズのメモリ空間を借りて、処理が終わったら free() 関数によって返却をしてきた。この返却を忘れたままプログラムを連続して動かそうとすると、返却されなかったメモリが使われない状態(メモリリーク)となり、メモリ領域不足から他のプログラムの動作に悪影響を及ぼす。
メモリリークを防ぐためには、malloc() で借りたら、free() で返すを実践すればいいのだが、複雑なデータ構造になってくると、こういった処理が困難となる。そこで、ヒープメモリの問題点について以下に説明する。
共有のあるデータの取扱の問題
リスト構造で集合計算の和集合を求める処理を考える。
// 集合和を求める処理
struct List* join( struct List* a , struct List* b )
{ struct List* ans = b ;
for( ; a != NULL ; a = a->next )
if ( !find( ans , a->data ) )
ans = cons( a->data , ans ) ;
return ans ;
}
void list_del( struct List* p )
{ // ダメなプログラムの例
while( p != NULL ) { // for( ; p != NULL ; p = p->next )
struct List* d = p ; // free( p ) ;
p = p->next ;
free( d ) ;
}
}
void main() {
// リストの生成
struct List* a = cons( 1 , cons( 2 , cons( 3 , NULL ) ) ) ;
struct List* b = cons( 2 , cons( 3 , cons( 4 , NULL ) ) ) ;
struct List* c = join( a , b ) ; // c = { 1, 2, 3, 4 }
// ~~~~~~~ ここは b
// a,b,cを使った処理
// 処理が終わったのでa,b,cを捨てる
list_del( a ) ;
list_del( b ) ;
list_del( c ) ; // list_del(b)ですでに消えている
} // このためメモリー参照エラー発生
このようなプログラムでは、c=join(a,b) ; が終わると下の図のようなデータ構造となる。しかし処理が終わってリスト廃棄list_del(a), list_del(b), listdel(c)を行おうとすると、bの先のデータは廃棄済みなのに、list_del(c)の実行時に、その領域を触ろうとして異常が発生する。
実体をコピーする方法
こういった共有の問題の一つの解決法としては、共有が発生しないように実体を別にコピーする方法もある。しかし、この方法はメモリがムダになる場合もあるし、List内のデータを修正した時に、実体をコピーした部分でも修正が反映されてほしい場合に問題となる。
// 実体をコピーする(簡潔に書きたいので再帰を使う) struct List* copy( struct List* p ) { if ( p != NULL ) return cons( p->data , copy( p->next ) ) ; else return NULL ; } // 共有が無い集合和を求める処理 struct List* join( struct List* a , struct List* b ) { struct List* ans = copy( b ) ; // ~~~~~~~~~実体をコピー for( ; a != NULL ; a = a->next ) if ( !find( ans , a->data ) ) ans = cons( a->data , ans ) ; return ans ; }
参照カウンタ法
上記の問題は、b の先のリストが c の一部とデータを共有しているために発生する。この解決方法として簡単な方法では、参照カウンタ法が用いられる。
参照カウンタ法では、データを参照するポインタの数をデータと共に保存する。
- データの中にポインタ数を覚える参照カウンタを設け、データを生成した時に1とする。
- 処理の中で共有が発生すると、参照カウンタをカウントアップする。
- データを捨てる際には、参照カウンタをカウントダウンし、0になったら本当にそのデータを消す。
struct List {
int refc ; // 参照カウンタ
int data ; // データ
struct List* next ; // 次のポインタ
} ;
struct List* cons( int x , struct List* p ) {
struct List* n = (struct List*)malloc( sizeof( struct List* ) ) ;
if ( n != NULL ) {
n->refc = 1 ; // 初期状態は参照カウンタ=1
n->data = x ;
n->next = p ;
}
return n ;
}
struct List* copy( struct List* p ) {
p->refc++ ; // 共有が発生したら参照カウンタを増やす。
return p ;
}
// 集合和を求める処理
struct List* join( struct List* a , struct List* b )
{
struct List* ans = copy( b ) ;
// ~~~~~~~~~共有が発生するのでrefc++
for( ; a != NULL ; a = a->next )
if ( !find( ans , a->data ) )
ans = cons( a->data , ans ) ;
return ans ;
}
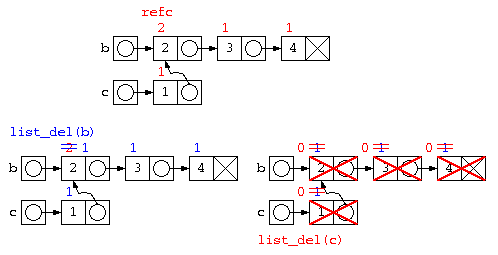
void list_del( strcut List* p ) { // 再帰で全廃棄
if ( p != NULL
&& --(p->refc) <= 0 ) { // 参照カウンタを減らし
// ~~~~~~~~~~~
list_del( p->next ) ; // 0ならば本当に消す
free( p ) ;
}
}
int main() { // リストの生成
struct List* a = cons( 1 , cons( 2 , cons( 3 , NULL ) ) ) ;
struct List* b = cons( 2 , cons( 3 , cons( 4 , NULL ) ) ) ;
struct List* c = join( a , b ) ;
// a,b,cを使った処理
// 処理が終わったのでa,b,cを捨てる
list_del( a ) ; // aの要素は全部refc=1なので普通に消えていく
list_del( b ) ; // bは、joinの中のcopy時にrefc=2なので、
// この段階では、refc=2 から refc=1 になるだけ
list_del( c ) ; // ここで全部消える。
}
unix i-nodeで使われている参照カウンタ
unixのファイルシステムの基本的構造 i-node では、1つのファイルを別の名前で参照するハードリンクという機能がある。このため、ファイルの実体には参照カウンタが付けられている。unix では、ファイルを生成する時に参照カウンタを1にする。ハードリンクを生成すると参照カウンタをカウントアップ”+1″する。ファイルを消す場合は、基本的に参照カウンタのカウントダウン”-1″が行われ、参照カウンタが”0″になるとファイルの実体を消去する。
以下に、unix 環境で 参照カウンタがどのように使われているのか、コマンドで説明していく。
$ echo a > a.txt
$ ls -al *.txt
-rw-r--r-- 1 t-saitoh t-saitoh 2 12月 21 10:07 a.txt
~~~ # ここが参照カウンタの値
$ ln a.txt b.txt # ハードリンクでコピーを作る
$ ls -al *.txt
-rw-r--r-- 2 t-saitoh t-saitoh 2 12月 21 10:07 a.txt
-rw-r--r-- 2 t-saitoh t-saitoh 2 12月 21 10:07 b.txt
~~~ # 参照カウンタが増えているのが分かる
$ rm a.txt # 元ファイルを消す
$ ls -al *.txt
-rw-r--r-- 1 t-saitoh t-saitoh 2 12月 21 10:07 b.txt
~~~ # 参照カウンタが減っている
$ ln -s b.txt c.txt # シンボリックリンクでコピーを作る
$ ls -al *.txt
-rw-r--r-- 1 t-saitoh t-saitoh 2 12月 21 10:07 b.txt
lrwxrwxrwx 1 t-saitoh t-saitoh 5 12月 21 10:10 c.txt -> b.txt
$ rm b.txt # 元ファイルを消す
$ ls -al *.txt
lrwxrwxrwx 1 t-saitoh t-saitoh 5 12月 21 10:10 c.txt -> b.txt
$ cat c.txt # c.txt は存在するけどその先の実体 b.txt は存在しない
cat: c.txt: そのようなファイルやディレクトリはありません
ハッシュ法
ここまでの授業では、配列(データ検索は、登録順保存ならO(N)、2分探索ならO(log N)となる、2分探索ができるのは配列がランダムアクセスができるからこそ)、単純リスト(データ検索(シーケンシャルアクセスしかできないのでO(N)となる)、2分探索木( O(log N) ) といった手法を説明してきた。しかし、もっと高速なデータ検索はできないのであろうか?
究極のシンプルなやり方(メモリの無駄)
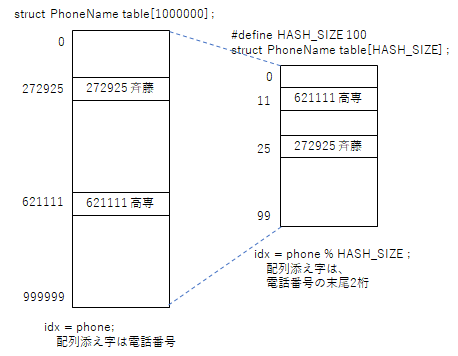
最も簡単なアルゴリズムは、電話番号から名前を求めるようなデータベースであれば、電話番号自身を配列添え字番号とする方法がある。しかしながら、この方法は大量のメモリを必要とする。
// メモリ無駄遣いな超高速方法
struct PhoneName {
int phone ;
char name[ 20 ] ;
} ;
// 電話番号は6桁とする。
struct PhoneName table[ 1000000 ] ; // 携帯電話番号ならどーなる!?!?
// 配列に電話番号と名前を保存
void entry( int phone , char* name ) {
table[ phone ].phone = phone ;
strcpy( table[ phone ].name , name ) ;
}
// 電話番号から名前を調べる
char* search( int phone ) {
return table[ phone ].name ;
}
しかし、50人程度のデータであれば、電話番号の末尾2桁を取り出した場合、同じ数値の人がいることは少ないであろう。であれば、電話番号の末尾2桁の値を配列の添え字番号として、データを保存すれば、配列サイズは100件となり、メモリの無駄を減らすことができる。
ハッシュ法
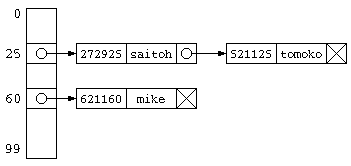
先に述べたように、データの一部を取り出して、それを配列の添え字番号として保存することで、高速にデータを読み書きできるようにするアルゴリズムはハッシュ法と呼ばれる。データを格納する表をハッシュ表、データの一部を取り出した添え字番号はハッシュ値、ハッシュ値を得るための関数がハッシュ関数と呼ばれる。
// ハッシュ衝突を考えないハッシュ法
#define HASH_SIZE 100 ;
struct PhoneName table[ HASH_SIZE ] ;
// ハッシュ関数
int hash_func( int phone ) {
return phone % HASH_SIZE ;
}
// 配列に電話番号と名前を保存
void entry( int phone , name ) {
int idx = hash_func( phone ) ;
table[ idx ].phone = phone ;
strcpy( table[ idx ].name , name ) ;
}
// 電話番号から名前を調べる
char* search( int phone ) {
int idx = hash_func( phone ) ;
return table[ idx ].name ;
}
ただし、上記のプログラムでは、電話番号の末尾2桁が偶然他の人と同じになることを考慮していない。
例えば、データ件数が100件あれば、同じ値の人も出てくるであろう。このように、異なるデータなのに同じハッシュ値が求まることを、ハッシュ衝突と呼ぶ。
ハッシュ関数に求められる特性
ハッシュ関数は、できる限り同じような値が求まるものは、ハッシュ衝突が多発するので、避けなければならない。例えば、6桁の電話番号の先頭2桁であれば、電話番号の局番であり、同じ学校の人でデータを覚えたら、同じ地域の人でハッシュ衝突が発生してしまう。また、ハッシュ値を計算するのに、配列の空き場所を一つ一つ探すような方式では、データ件数に比例した時間がかかり、高速なアルゴリズムとは言えない。このことから、ハッシュ関数には以下のような特徴が必要となる。
- 同じハッシュ値が発生しづらい(一見してデタラメのように見える値)
- 簡単な計算で求まること。
- 同じデータに対し常に、同じハッシュ値が求まること。
ここで改めて、異なるデータでも同じハッシュ値が求まった場合、どうすれば良いのだろうか?
ハッシュ法を簡単なイメージで説明すると、100個の椅子(ハッシュ表)が用意されていて、1クラスの学生が自分の電話番号の末尾2桁(ハッシュ関数)の場所(ハッシュ値)に座るようなもの。自分のイスに座ろうとしたら、同じハッシュ値の人が先に座っていたら、どこに座るべきだろうか?
オープンアドレス法
先の椅子取りゲームの例え話であれば、先に座っている人がいた場合、最も簡単な椅子に座る方法は、隣が空いているか確認して空いていたらそこに座ればいい。
これをプログラムにしてみると、以下のようになる。このハッシュ法は、求まったアドレスの場所にこだわらない方式でオープンアドレス法と呼ばれる。
// オープンアドレス法
// table[] は大域変数で0で初期化されているものとする。
// 配列に電話番号と名前を保存
void entry( int phone , name ) {
int idx = hash_func( phone ) ;
while( table[ idx ].phone != 0 )
idx = (idx + 1) % HASH_SIZE ; // ひとつ後ろの席
} // idx++ でないのは何故?
table[ idx ].phone = phone ;
strcpy( table[ idx ].name , name ) ;
}
// 電話番号から名前を調べる
char* search( int phone ) {
int idx = hash_func( phone ) ;
while( table[ idx ].phone != 0 ) {
if ( table[ idx ].phone == phone )
return table[ idx ].name ;
idx = (idx + 1) % HASH_SIZE ; // ひとつ後ろの席
} // idx++ でないのは何故?
return NULL ; // 見つからなかった
}
注意:このプログラムは、ハッシュ表すべてにデータが埋まった場合、無限ループとなるので、実際にはもう少し改良が必要である。
この実装方法であれば、ハッシュ表にデータが少ない場合は、ハッシュ値を計算すれば終わり。よって、処理時間のオーダはO(1)となる。しかし、ハッシュ表がほぼ埋まっている状態だと、残りわずかな空き場所を探すようなもの。
文字列のハッシュ値
ここまでで説明した事例は、電話番号をキーとするものであり、余りを求めるだけといったような簡単な計算で、ハッシュ値が求められた。しかし、一般的には文字列といったような名前から、ハッシュ値が欲しいことが普通だろう。
ハッシュ値は、簡単な計算で、見た目デタラメな値が求まればいい。 (ただしく言えば、ハッシュ値の出現確率が極力一様であること)。一見規則性が解らない値として、文字であれば文字コードが考えられる。複数の文字で、これらの文字コードを加えるなどの計算をすれば、 偏りの少ない値を取り出すことができる。
int hash_func( char s[] ) {
int sum = 0 ;
for( int i = 0 ; s[i] != '¥0' ; i++ ) {
sum = sum + s[i] ;
}
return sum % SIZE ;
}
文字列順で異なる値となるように
前述のハッシュ関数は、”ABC”さんと”CBA”さんでは、同じハッシュ値が求まってしまう。文字列順で異なる値が求まるように改良してみる。
int hash_func( char s[] ) {
int sum = 0 ;
for( int i = 0 ; s[i] != '¥0' ; i++ ) {
sum = sum*2 + s[i] ;
// sum = (sum * 小さい素数 + s[i]) % 大きい素数 ;
}
return sum % SIZE ;
}
理解度確認
毎年、冬休み期間中の自主的な理解度確認として、CBT を用いた理解度確認を行っています。今年も実施しますので、下記のシステムにログインし情報構造論では「ソフトウェア」(50分) を受講して下さい。
- https://cbt.kosen-ac.jp/
- 認証には、MS-365 のアカウントとパスワードでログインしてください。