前回の授業で時間切れだったので、再度掲載してから、次のメモリーの使用効率について説明し、必要に応じてメモリを確保するための方法を考える。
ポインタインクリメントと式
C言語では、ポインタを動かしながら処理を行う場合に以下のようなプログラムもよくでてくる。
// string copy 配列のイメージで記載
void strcpy( char d[] , char s[] ) {
int i ;
for( i = 0 ; s[ i ] != '\0' ; i++ )
d[ i ] = s[ i ] ;
d[ i ] = '\0' ;
}
int main() {
char a[] = "abcde" ;
char b[ 10 ] ;
strcpy( b , a ) ;
printf( "%s\n" , b ) ;
return 0 ;
}
しかし、この strcpy は、ポインタを使って書くと以下のように書ける。
// string copy ポインタのイメージで記載
void strcpy( char* p , char* q ) {
while( *q != '\0' ) {
*p = *q ;
p++ ;
q++ ;
}
*p = '\0' ;
}
// ポインタ加算と代入を一度に書く
void strcpy( char* p , char* q ) {
while( *q != '\0' )
*p++ = *q++ ; // *(p++) = *(q++)
*p = '\0' ;
}
// ポインタ加算と代入と'¥0'判定を一度に書く
void strcpy( char* p , char* q ) {
while( (*p++ = *q++) != '\0' ) // while( *p++ = *q++ ) ; でも良い
;
}
インクリメント演算子
C言語での++ や — といった演算子は、変数の前に書く場合と後ろに書く場合で挙動が異なる。
前置記法の “++i” は、i の値を使う前に +1 加算が行われ、”i++” は、iの値を使った後に、 +1 が行われる。
int main() { int i = 11 ; printf( "%d\n" , ++i ) ; // i = i + 1 ; // printf( "%d\n" , i ) ; と同じ // 12 が表示される printf( "%d\n" , i++ ) ; // printf( "%d\n" , i ) ; // i = i + 1 ; と同じ // 12 が表示され、i の値は13 return 0 ; }
構造体とポインタ
構造体を関数に渡して処理を行う例を示す。
struct Person {
char name[ 10 ] ;
int age ;
} ;
struct Person table[3] = {
{ "t-saitoh" , 55 } ,
{ "tomoko" , 44 } ,
{ "mitsuki" , 19 } ,
} ;
void print_Person( struct Person* p ) {
printf( "%s %d\n" ,
(*p).name , // * と . では . の方が優先順位が高い
// p->name と簡単に書ける。
p->age ) ; // (*p).age の簡単な書き方
}
void main() {
for( int i = 0 ; i < 3 ; i++ ) {
print_Person( &(table[i]) ) ;
// print_Person( table + i ) ; でも良い
}
}
配列宣言でサイズは定数
C言語では、配列宣言を行う時は、配列サイズに変数を使うことはできない。
こういった話をすると「C# とか C++ とか JavaScript とか使えば、配列のサイズなんて考える必要ないから、そんなこと考えなくてもいいじゃん…」って思うかもしれないけど、こういった新しい言語では、この後の授業で説明するリスト構造やらハッシュといった機能を使っていて、それをどう扱っているのか知らずに、処理速度が遅い原因を見逃してしまうかもしれない。
void foo( int size ) {
int array[ size ] ; // エラー
for( int i = 0 ; i < size ; i++ )
array[ i ] = i*i ;
}
void main() {
foo( 3 ) ; // 最近のC(C99)では、こういったプログラムも
foo( 4 ) ; // 裏で後述のalloca()を使って動いたりする。(^_^;
}
メモリ利用の効率
配列サイズには、定数式しか使えないので、1クラスの名前のデータを覚えるなら、以下のような宣言が一般的であろう。
#define MEMBER_SIZE 50 #define NAME_LENGTH 20 char name[ MEMBER_SIZE ][ NAME_LENGTH ] ;
しかしながら、クラスに寿限無とか銀魂の「ビチグソ丸」のような名前の人がいたら、20文字では足りない。(C言語の普通の配列宣言では、”t-saitoh”くんは配列サイズ9byte、”寿限無”くんは配列220byte といった使い方はできない) また、クラスの人数も、巨大大学の学生全員を覚えたいとい話であれば、 10000人分を用意する必要がある。 ただし、10000人の”寿限無”ありを考慮して、5Mbyte の配列を準備したのに、与えられたデータ量が100件で終わってしまうなら、その際のメモリの利用効率は極めて低い。
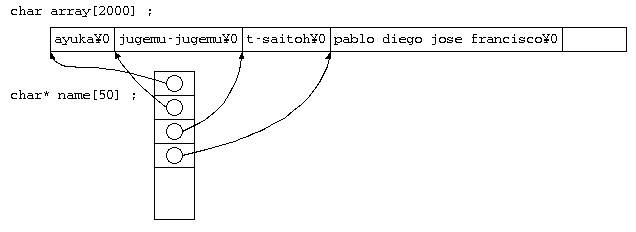
このため、最も簡単な方法は、以下のように巨大な文字配列に先頭から名前を入れていき、 文字ポインタ配列に、各名前の先頭の場所を入れる方式であれば、 途中に寿限無がいたとしても、問題はない。
char array[2000] = "ayuka¥0mitsuki¥0t-saitoh¥0tomoko¥0....." ; char *name[ 50 ] = { array+0 , array+6 , array+14 , array+23 , ... } ;
この方式であれば、2000byte + 4byte(32bitポインタ)×50 のメモリがあれば、 無駄なメモリ空間も必要最低限とすることができる。
参考:
寿限無(文字数:全角103文字)
さる御方、ビチグソ丸(文字数:全角210文字)
引用Wikipedia



大きな配列を少しづつ貸し出す処理
上に示したデータの覚え方を、データが出現する度に保存するのであれば、以下のようなコードになるだろう。
// 巨大な配列
char str[ 10000 ] ;
// 使用領域の末尾(初期値は巨大配列の先頭)
char* sp = str ;
// 文字列を保存する関数
char* entry( char* s ) {
char* ret = sp ;
strcpy( sp , s ) ;
sp += strlen( s ) + 1 ;
return ret ;
}
int main() {
char* names[ 10 ] ;
names[ 0 ] = entry( "saitoh" ) ;
names[ 1 ] = entry( "jugemu-jugemu-gokono-surikire..." ) ;
return 0 ;
}
// str[] s a i t o h ¥0 t o m o k o ¥0
// ↑ ↑
// names[0] names[1]
このプログラムでは、貸し出す度に、sp のポインタを後ろに移動していく。しかし、名前を覚えておく必要がなくなった場合、その場所はどうすればいいだろうか?
スタック
この貸し出す度に、末尾の場所をずらす方式にスタックがある。
int stack[ 100 ] ;
int* sp = stack ;
void push( int x ) {
*sp = x ; // 1行で書くなら
sp++ ; // *sp++ = x ;
}
int pop() {
sp-- ;
return *sp ; // return *(--sp) ;
}
int main() {
push( 1 ) ;
push( 2 ) ;
push( 3 ) ;
printf( "%d¥n" , pop() ) ;
printf( "%d¥n" , pop() ) ;
printf( "%d¥n" , pop() ) ;
return 0 ;
}
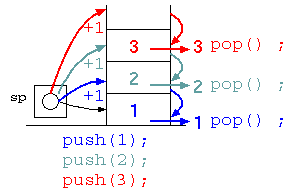
スタックは、最後に保存したデータを最初に取り出せる(Last In First Out)から、LIFO とも呼ばれる。
このデータ管理方法は、最後に呼び出した関数が最初に終了することから、関数の戻り番地の保存や、最後に確保した局所変数が最初に不要となることから、局所変数の管理に利用されている。
alloca() 関数
局所変数と同じスタック上に、一時的にデータを保存する配列を作り、関数が終わると不要になる場合には、alloca() 関数が便利である。alloca の引数には、必要なメモリの byte 数を指定する。
100個の整数データを保存するのであれば、int が 32bit の 4byte であれば 400byte を指定する。ただし、int 型は16bitコンピュータなら2byteかもしれないし、64bitコンピュータなら、8byte かもしれないので、確保するバイト数を計算する際には sizeof() 演算子を使い、100 * sizeof( int ) と書くべきである。
#include <alloca.h>
void foo( int size ) {
// 本当なら int p[ size ] ; と宣言したい。
int* p ;
// size件のint型配列を作る
p = (int*)alloca( sizeof( int ) * size ) ;
// 確保した配列に値を保存
for( int i = 0 ; i < size ; i++ )
p[ i ] = i*i ;
// 確保した値を使う
for( int i = 0 ; i < size ; i++ )
printf( "%d\n" , p[ i ] ) ;
}
void main() {
foo( 3 ) ;
foo( 4 ) ;
}
alloca() は、指定された byte 数のデータ領域の先頭ポインタを返すが、その領域を 文字を保存するために使うか、int を保存するために使うかは alloca() では解らない。alloca() の返り値は、使う用途に応じて型キャストが必要である。文字を保存するなら、(char*)alloca(…) 、 intを保存するなら (int*)alloca(…) のように使う。
ただし、関数内で alloca で確保したメモリは、その関数が終了すると、その領域は使えなくなる。このため、最後に alloca で確保したメモリが、最初に不要となる…ような使い方でしか使えない。
必要に応じてメモリを確保して、その領域が不要となる順序が「最後に確保したものから不要になる」という順序でなかったら、メモリはどのように管理すればいいだろうか?こういった場合のために、C 言語では malloc() 関数と free() 関数によるヒープメモリ領域がある。次の講義ではこの malloc, free について解説を行う。