ここまでの授業では、配列(データ検索は、登録順保存ならO(N)、2分探索ならO(log N)となる、2分探索ができるのは配列がランダムアクセスができるからこそ)、単純リスト(データ検索(シーケンシャルアクセスしかできないのでO(N)となる)、2分探索木( O(log N) ) といった手法を説明してきた。しかし、もっと高速なデータ検索はできないのであろうか?
究極のシンプルなやり方(メモリの無駄)
最も簡単なアルゴリズムは、電話番号から名前を求めるようなデータベースであれば、電話番号自身を配列添え字番号とする方法がある。しかしながら、この方法は大量のメモリを必要とする。
// メモリ無駄遣いな超高速方法
struct PhoneName {
int phone ;
char name[ 20 ] ;
} ;
// 電話番号は6桁とする。
struct PhoneName table[ 1000000 ] ; // 携帯電話番号ならどーなる!?!?
// 配列に電話番号と名前を保存
void entry( int phone , char* name ) {
table[ phone ].phone = phone ;
strcpy( table[ phone ].name , name ) ;
}
// 電話番号から名前を調べる
char* search( int phone ) {
return table[ phone ].name ;
}
しかし、50人程度のデータであれば、電話番号の末尾2桁を取り出した場合、同じ数値の人がいることは少ないであろう。であれば、電話番号の末尾2桁の値を配列の添え字番号として、データを保存すれば、配列サイズは100件となり、メモリの無駄を減らすことができる。
ハッシュ法
先に述べたように、データの一部を取り出して、それを配列の添え字番号として保存することで、高速にデータを読み書きできるようにするアルゴリズムはハッシュ法と呼ばれる。データを格納する表をハッシュ表、データの一部を取り出した添え字番号はハッシュ値、ハッシュ値を得るための関数がハッシュ関数と呼ばれる。
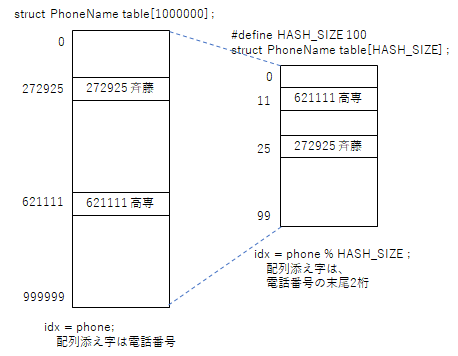
// ハッシュ衝突を考えないハッシュ法
#define HASH_SIZE 100 ;
struct PhoneName table[ HASH_SIZE ] ;
// ハッシュ関数
int hash_func( int phone ) {
return phone % HASH_SIZE ;
}
// 配列に電話番号と名前を保存
void entry( int phone , name ) {
int idx = hash_func( phone ) ;
table[ idx ].phone = phone ;
strcpy( table[ idx ].name , name ) ;
}
// 電話番号から名前を調べる
char* search( int phone ) {
int idx = hash_func( phone ) ;
return table[ idx ].name ;
}
ただし、上記のプログラムでは、電話番号の末尾2桁が偶然他の人と同じになることを考慮していない。
例えば、データ件数が100件あれば、同じ値の人も出てくるであろう。このように、異なるデータなのに同じハッシュ値が求まることを、ハッシュ衝突と呼ぶ。
ハッシュ関数に求められる特性
ハッシュ関数は、できる限り同じような値が求まるものは、ハッシュ衝突が多発するので、避けなければならない。例えば、6桁の電話番号の先頭2桁であれば、電話番号の局番であり、同じ学校の人でデータを覚えたら、同じ地域の人でハッシュ衝突が発生してしまう。また、ハッシュ値を計算するのに、配列の空き場所を一つ一つ探すような方式では、データ件数に比例した時間がかかり、高速なアルゴリズムとは言えない。このことから、ハッシュ関数には以下のような特徴が必要となる。
- 同じハッシュ値が発生しづらい(一見してデタラメのように見える値)
- 簡単な計算で求まること。
- 同じデータに対し常に、同じハッシュ値が求まること。
ここで改めて、異なるデータでも同じハッシュ値が求まった場合、どうすれば良いのだろうか?
ハッシュ法を簡単なイメージで説明すると、100個の椅子(ハッシュ表)が用意されていて、1クラスの学生が自分の電話番号の末尾2桁(ハッシュ関数)の場所(ハッシュ値)に座るようなもの。自分のイスに座ろうとしたら、同じハッシュ値の人が先に座っていたら、どこに座るべきだろうか?
オープンアドレス法
先の椅子取りゲームの例え話であれば、先に座っている人がいた場合、最も簡単な椅子に座る方法は、隣が空いているか確認して空いていたらそこに座ればいい。
これをプログラムにしてみると、以下のようになる。このハッシュ法は、求まったアドレスの場所にこだわらない方式でオープンアドレス法と呼ばれる。
// オープンアドレス法
// table[] は大域変数で0で初期化されているものとする。
// 配列に電話番号と名前を保存
void entry( int phone , name ) {
int idx = hash_func( phone ) ;
while( table[ idx ].phone != 0 )
idx = (idx + 1) % HASH_SIZE ; // ひとつ後ろの席
} // idx++ でないのは何故?
table[ idx ].phone = phone ;
strcpy( table[ idx ].name , name ) ;
}
// 電話番号から名前を調べる
char* search( int phone ) {
int idx = hash_func( phone ) ;
while( table[ idx ].phone != 0 ) {
if ( table[ idx ].phone == phone )
return table[ idx ].name ;
idx = (idx + 1) % HASH_SIZE ; // ひとつ後ろの席
} // idx++ でないのは何故?
return NULL ; // 見つからなかった
}
注意:このプログラムは、ハッシュ表すべてにデータが埋まった場合、無限ループとなるので、実際にはもう少し改良が必要である。
この実装方法であれば、ハッシュ表にデータが少ない場合は、ハッシュ値を計算すれば終わり。よって、処理時間のオーダはO(1)となる。しかし、ハッシュ表がほぼ埋まっている状態だと、残りわずかな空き場所を探すようなもの。
文字列のハッシュ値
ここまでで説明した事例は、電話番号をキーとするものであり、余りを求めるだけといったような簡単な計算で、ハッシュ値が求められた。しかし、一般的には文字列といったような名前から、ハッシュ値が欲しいことが普通だろう。
ハッシュ値は、簡単な計算で、見た目デタラメな値が求まればいい。 (ただしく言えば、ハッシュ値の出現確率が極力一様であること)。一見規則性が解らない値として、文字であれば文字コードが考えられる。複数の文字で、これらの文字コードを加えるなどの計算をすれば、 偏りの少ない値を取り出すことができる。
int hash_func( char s[] ) {
int sum = 0 ;
for( int i = 0 ; s[i] != '¥0' ; i++ ) {
sum = sum + s[i] ;
}
return sum % SIZE ;
}
文字列順で異なる値となるように
前述のハッシュ関数は、”ABC”さんと”CBA”さんでは、同じハッシュ値が求まってしまう。文字列順で異なる値が求まるように改良してみる。
int hash_func( char s[] ) {
int sum = 0 ;
for( int i = 0 ; s[i] != '¥0' ; i++ ) {
sum = sum*2 + s[i] ;
// sum = (sum * 小さい素数 + s[i]) % 大きい素数 ;
}
return sum % SIZE ;
}
理解度確認
毎年、冬休み期間中の自主的な理解度確認として、CBT を用いた理解度確認を行っています。今年も実施しますので、下記のシステムにログインし情報構造論では「ソフトウェア」(50分) を受講して下さい。
- https://cbt.kosen-ac.jp/
- 認証には、MS-365 のアカウントとパスワードでログインしてください。