前回の授業では、共有のあるデータ構造では、データの解放などで問題が発生することを示し、その解決法として参照カウンタ法などを紹介した。今日は、参照カウンタ法の問題を示した上で、ガベージコレクタなどの説明を行う。
共有のあるデータの取扱の問題
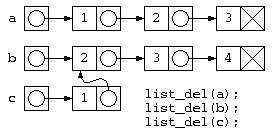
前回の講義を再掲となるが、リスト構造で集合計算おこなう場合の和集合を求める処理を考える。
struct List* join( struct List* a , struct List* b )
{ struct List* ans = b ;
for( ; a != NULL ; a = a->next )
if ( !find( ans , a->data ) )
ans = cons( a->data , ans ) ;
return ans ;
}
void list_del( struct List* p )
{ // ダメなプログラムの例
while( p != NULL ) { // for( ; p != NULL ; p = p->next )
struct List* d = p ; // free( p ) ;
p = p->next ;
free( d ) ;
}
}
void main() {
// リストの生成
struct List* a = cons( 1 , cons( 2 , cons( 3 , NULL ) ) ) ;
struct List* b = cons( 2 , cons( 3 , cons( 4 , NULL ) ) ) ;
struct List* c = join( a , b ) ; // c = { 1, 1, 2, 3 }
// ~~~~~~~ ここは b
// a,b,cを使った処理
// 処理が終わったのでa,b,cを捨てる
list_del( c ) ;
list_del( b ) ;
list_del( a ) ; // list_del(c)ですでに消えている
} // このためメモリー参照エラー発生
このようなプログラムでは、下の図のようなデータ構造が生成されるが、処理が終わってリスト廃棄を行おうとすると、bの先のデータは廃棄済みなのに、list_del(c)の実行時に、その領域を触ろうとして異常が発生する。
参照カウンタ法
上記の問題は、b の先のリストが c の一部とデータを共有しているために発生する。この解決方法として簡単な方法では、参照カウンタ法が用いられる。
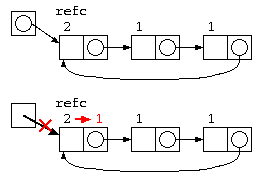
参照カウンタ法では、データを参照するポインタの数をデータと共に保存する。
- データの中にポインタ数を覚える参照カウンタを設け、データを生成した時に1とする。
- 処理の中で共有が発生すると、参照カウンタをカウントアップする。
- データを捨てる際には、参照カウンタをカウントダウンし、0になったら本当にそのデータを消す。
struct List {
int refc ; // 参照カウンタ
int data ; // データ
struct List* next ; // 次のポインタ
} ;
void list_del( strcut List* p ) { // 再帰で全廃棄
if ( p != NULL
&& --(p->refc) <= 0 ) { // 参照カウンタを減らし
list_del( p->next ) ; // 0ならば本当に消す
free( p ) ;
}
}
ただし、参照カウンタ法は、循環リストではカウンタが0にならないので、取扱いが苦手。
ガベージコレクタ
では、循環リストの発生するようなデータで、共有が発生するような場合には、どのようにデータを管理すれば良いだろうか?
最も簡単な方法は、「処理が終わっても使い終わったメモリを返却しない」方法である。ただし、このままでは、メモリを使い切ってしまう。
そこで、廃棄処理をしないまま、ゴミだらけになってしまったメモリ空間を再利用するのが、ガベージコレクタである。
ガベージコレクタは、貸し出すメモリ空間が無くなった時に起動され、
- すべてのメモリ空間に、「不要」の目印をつける。(mark処理)
- 変数に代入されているデータが参照している先のデータは「使用中」の目印をつける。(mark処理)
- その後、「不要」の目印がついている領域は、だれも使っていないので回収する。(sweep処理)
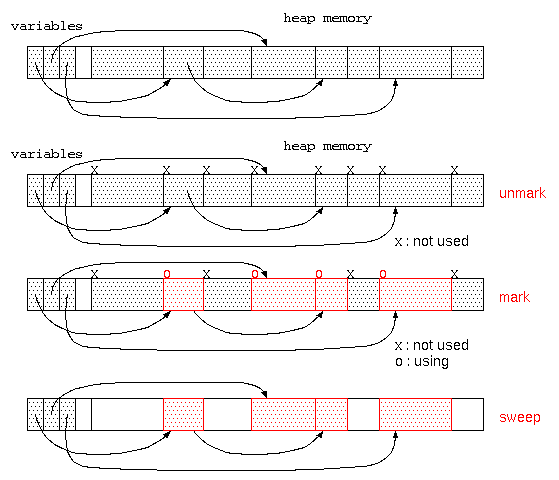
この方式は、マークアンドスイープ法と呼ばれる。ただし、このようなガベージコレクタが動く場合は、他の処理ができず処理が中断されるので、コンピュータの操作性という点では問題となる。
最近のプログラミング言語では、参照カウンタとガベージコレクタを取り混ぜた方式でメモリ管理をする機能が組み込まれている。このようなシステムでは、局所変数のような関数に入った時点で生成され関数終了ですぐに不要となる領域は、参照カウンタで管理し、大域変数のような長期間保管するデータはガベージコレクタで管理される。
大量のメモリ空間で、メモリが枯渇したタイミングでガベージコレクタを実行すると、長い待ち時間となることから、ユーザインタフェースの待ち時間に、ガベージコレクタを少しづつ動かすなどの方式もとることもある。
ガベージコレクタが利用できる場合、メモリ管理を気にする必要はなくなってくる。しかし、初心者が何も気にせずプログラムを書くと、使われないままのメモリがガベージコレクタの起動まで放置され、場合によっては想定外のタイミングでのメモリ不足による処理速度低下の原因となる場合もある。手慣れたプログラマーであれば、素早くメモリを返却するために、使われなくなった変数には積極的に null を代入するなどのテクニックを使う。
プログラム言語とメモリ管理機能
一般的に、C言語というとポインタの概念を理解できないと使えなかったり、メモリ管理をきちんとできなければ危険な言語という点で初心者向きではないと言われている。
C言語は、元々 BCPL や B言語を改良してできたプログラム言語であった。これに、オブジェクト指向の機能を加えた C++ が作られた。C++ という言語の名前は、B言語→C言語と発展したので、D言語(現在はまさにD言語は存在するけど)と名付けようという意見もあったが、C++ を開発したビャーネ・ストロヴストルップは、ガベージコレクタのようなメモリ管理機能が無いことから、D言語を名乗るには不十分ということで、C言語を発展させたものという意味でC++と名付けている。
こういった中で、C++をベースとしたガベージコレクタなどを実装した言語としては、Java が挙げられる。オブジェクト指向をベースとしたマルチスレッドやガベージコレクタに加え、仮想マシンによる実行で様々なOS(やブラウザ)で動かすことができる。
最近注目されている言語の1つとして、C言語の苦手であった「メモリ安全性」や実行効率を考えて開発されたものに Rust が挙げられる。メモリ管理や効率などの性能から、最近では Linux の開発言語に Rust を部分的に導入されている。
C言語でデータが保存される領域は大きく以下の3つに分類される。
- 静的データ領域(大域変数領域)
- スタック領域(局所変数)
- ヒープ領域(malloc(),free()で管理される領域)
2,3は、処理の途中で領域が作られ不要になったら消える領域であり動的メモリ領域という。
局所変数とスタック
局所変数は、関数に入った時に作られるメモリ領域であり、関数の処理を抜けると自動的に開放されるデータ領域である。
関数の中で関数が呼び出されると、スタックに戻り番地情報を保存し、関数に移動する。最初の処理で局所変数領域が確保され、関数を終えると局所変数は開放される。
この局所変数の確保と開放は、最後に確保された領域を最初に開放される(Last In First Out)ことから、スタック上に保存される。
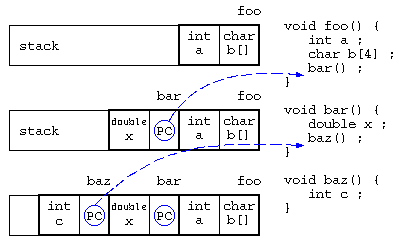
baz()の中で、「*((&c)+8) = 123 ;」を実行したら、bar()のxを書き換えられるかも…(実際の関数呼び出し時に保存される情報はもう少し複雑:コールスタック/Wikipedia)
こういった変数の並び順を悪用し、情報の読み書きを防ぐために、局所変数の保存場所の順序を入れ替えたり、メモリのアドレス空間配置のランダム化などが行われたりする。