前回の malloc() + free() の資料で、様々なデータ構造の覚え方の例やメモリイメージを説明し、前期中間のレポート課題を示す。
malloc+freeの振り返り
// 文字列(可変長)の保存
char str[] = "ABCDE" ;
char* pc ;
pc = (char*)malloc( strlen( str ) + 1 ) ;
if ( pc != NULL ) { // ↑正確に書くと sizeof( char ) * (strlen(str)+1)
strcpy( pc , str ) ;
////////////////////
// pcを使った処理
////////////////////
free( pc ) ;
}
//
// 可変長の配列の保存
int data[] = { 11 , 22 , 33 } ;
int* pi ;
pi = (int*)malloc( sizeof( int ) * 3 ) ;
if ( pi != NULL ) {
for( int i = 0 ; i < 3 ; i++ )
pi[ i ] = data[ i ] ;
////////////////////
// piを使った処理
////////////////////
free( pi ) ;
}
//
// 1件の構造体の保存
struct Person {
char name[ 10 ] ;
int age ;
} ;
struct Person* pPsn ;
pPsn = (struct Person*)malloc( sizeof( struct Person ) ) ;
if ( pPsn != NULL ) {
strcpy( pPsn->name , "t-saitoh" ) ;
pPsn->age = 55 ;
////////////////////
// pPsnを使った処理
////////////////////
free( pPsn ) ;
}
安全な1行1件のデータ入力
C言語では、scanf などの関数は、バッファオーバーフローなどの危険性があるため、以下のような処理を使うことが多い。fgets は、指定されたファイルから1行分のデータを読み込む。sscanf は、文字列のなかから、scanf() と同じようなフォーマット指定でデータを読み込む。
fgets は、これ以上の入力データが無い場合には、NULL を返す。
(Windowsであれば、キー入力でCtrl+Z を入力、macOSやLinuxであれば、Ctrl+Dを入力で終了)
sscanf() は、読み込めたデータ件数を返す。
int main() {
char buff[ 1024 ] ;
for( int i = 0 ; i < 3 ; i++ ) {
if ( fgets( buff , sizeof( buff ) , stdin ) != NULL ) {
char name[ 1024 ] ;
int age ;
if ( sscanf( buff , "%s%d" , name , &age ) == 2 ) {
// 名前と年齢の2つのデータが正しく読み込めたとき
...
}
}
}
return 0 ;
}
様々なデータの覚え方
配列サイズ固定・名前が固定長
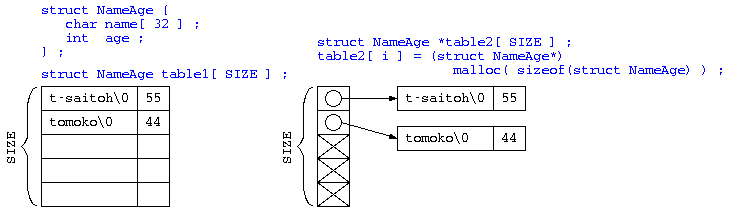
例えば、このデータ構造であれば、table1[] の場合、長い名前にある程度対応できるように nameの配列を100byteにしたりすると、データ件数が少ない場合には、メモリの無駄も多い。
そこで、実際に入力された存在するデータだけをポインタで覚える方法 table2[] という保存方法も考えられる。
// 固定長データのプログラム
#define SIZE 50
// 名前(固定長)と年齢の構造体
struct NameAge {
char name[ 32 ] ;
int age ;
} ;
struct NameAge table1[ SIZE ] ;
int size1 = 0 ;
void entry1( char s[] , int a ) {
strcpy( table1[ size1 ].name , s ) ;
table1[ size1 ].age = a ;
size1++ ;
}
// ポインタで覚える場合
struct NameAge* table2[ SIZE ] ;
int size2 = 0 ;
void entry2( char s[] , int a ) {
table2[size2] = (struct NameAge*)malloc( sizeof( struct NameAge ) ) ;
if ( table2[size2] != NULL ) { // なぜ != NULL のチェックを行うのか、説明せよ
strcpy( table2[size2]->name , s ) ;
table2[size2]->age = a ;
size2++ ;
}
}
// データ出力
void print_NA( struct NameAge* p ) {
printf( "%s %d¥n" , p->name , p->age ) ;
}
int main() {
// table1に保存
entry1( "t-saitoh" , 55 ) ;
entry1( "tomoko" , 44 ) ;
print_NA( &table1[0] ) ;
print_NA( &table1[1] ) ;
// table2に保存
entry2( "t-saitoh" , 55 ) ;
entry2( "tomoko" , 44 ) ;
print_NA( _________________ ) ; // table2の中身を表示せよ
print_NA( _________________ ) ;
return 0 ;
}
配列サイズ固定・名前が可変長
しかしながら、前回の授業で説明したように、際限なく長い名前があるのであれば、以下の様に名前は、ポインタで保存し、データを保存する時に strdup(…) を使って保存する方法もあるだろう。
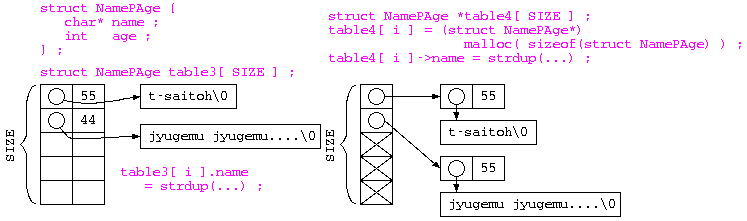
// 名前が可変長のプログラム
// 名前(可変長)と年齢の構造体
struct NamePAge {
char* name ; // ポインタで保存
int age ;
} ;
struct NamePAge table3[ SIZE ] ;
int size3 = 0 ;
void entry3( char s[] , int a ) {
table3[ size3 ].name = strdup( s ) ; // ★★★★
table3[ size3 ].age = a ;
size3++ ;
}
// ポインタで覚える場合
struct NamePAge* table4[ SIZE ] ;
int size4 = 0 ;
void entry4( char s[] , int a ) {
table4[size4] = (struct NamePAge*)malloc( ____________________ ) ;
if ( table4[size4] != NULL ) { // ↑適切に穴埋めせよ
table4[size4]->name = strdup( s ) ; // ★★★★
_________________________________ ; // ←適切に穴埋めせよ
size4++ ;
}
}
// データ出力
void print_NPA( struct NamePAge* p ) {
printf( "%s %d¥n" , ____________ , ____________ ) ;
} // ↑適切に穴埋めせよ
int main() {
// table3に保存
entry3( "t-saitoh" , 55 ) ;
entry3( "jyugemu jyugemu ..." , 44 ) ;
print_NPA( _________________ ) ; // table3[] の中身を表示せよ。
print_NPA( _________________ ) ;
// table4に保存
entry4( "t-saitoh" , 55 ) ;
entry4( "jyugemu jyugemu ..." , 44 ) ;
print_NPA( table4[0] ) ;
print_NPA( table4[1] ) ;
return 0 ;
}
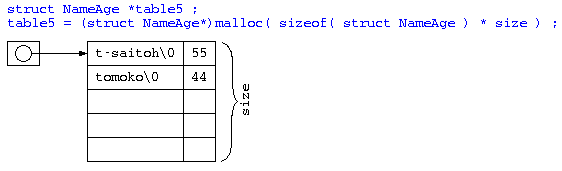
データ件数が可変長ならば
前述のプログラムでは、データ件数全体は、SIZE という固定サイズを想定していた。しかしながら、データ件数自体も数十件かもしれないし、数万件かもしれないのなら、配列のサイズを可変長にする必要がある。
struct NamePAge* table5 ;
int size5 = 0 ;
void entry5( char s[] , int a ) {
strcpy( table5[ size5 ].name , s ) ;
table5[ size5 ].age = a ;
size5++ ;
}
int main() {
// table5に保存
table5 = (struct NameAge*)malloc( sizeof( struct NameAge ) * 2 ) ;
if ( table5 != NULL ) {
entry5( "t-saitoh" , 55 ) ;
entry5( "tomoko" , 44 ) ;
}
return 0 ;
}
メモリの管理に十分気を付ける必要があるが、名前の長さも配列全体のサイズも可変長であれば、以下のようなイメージ図のデータを作る必要があるだろう。(JavaScriptやJavaといった言語ではデータのほとんどがこういったポインタで管理されている)

レポート課題
授業での malloc , free を使ったプログラミングを踏まえ、以下のレポートを作成せよ。
以下のデータのどれか1つについて、データを入力し、何らかの処理を行うこと。
課題は、原則として、(自分の出席番号%3)+1 についてチャレンジすること。
- 名前と電話番号
- 名前と身長・体重
- 名前と生年月日
このプログラムを作成するにあたり、以下のことを考慮しmallocを適切に使うこと。
名前は、長い名前の人が混ざっているかもしれない。
保存するデータ件数は、10件かもしれない1000件かもしれない。(データ件数は、処理の最初に入力すること。)
ただし、mallocの理解に自信がない場合は、名前もしくはデータ件数のどちらか一方は固定値でも良い。
レポートには、(a)プログラムリスト, (b)プログラムの説明, (c)正しく動いたことがわかる実行例, (d)考察 を記載すること。
考察には、自分のプログラムが正しく動かない事例はどういう状況でなぜ動かないのか…などを検討したり、プログラムで良くなった点はどういう所かを説明すること。