最初のリスト生成の説明では、補助関数 cons を用いて、直接リストを生成していた。
しかし、実際にはデータを入力しながらの処理となるであろう。今回は、前回のリスト操作のプログラムの確認などと合わせ、リストへのデータの追加処理について説明する。
ループによるリスト操作・再帰によるリスト操作
ループによるリスト操作のプログラム例を以下に示す。
// リストの全要素を出力
void print( struct List* p ) {
for( ; p != NULL ; p = p->next )
printf( "%d " , p->data ) ;
printf( "¥n" ) ;
}
// リストの件数を返す
int count( struct List* p ) {
int c = 0 ;
for( ; p != NULL ; p = p->next )
c++ ;
return c ;
}
// リストの合計を返す
int sum( struct List* p ) {
int s = 0 ;
for( ; p != NULL ; p = p->next )
s += p->data ;
return s ;
}
// リストの最大値を返す
int max( struct List* p ) {
if ( p == NULL ) {
return 0 ;
} else {
int m = p->data ;
for( p = p->next ; p != NULL ; p = p->next )
if ( p->data > m )
m = p->data ;
return m ;
}
}
// リストの中から指定したkeyが含まれるか探す
int find( struct List* p , int key ) {
// 要素を見つけたら 1 、見つからなかったら 0 を返す
for( ; p != NULL ; p = p->next )
if ( p->data == key )
return 1 ;
return 0 ;
}
同じプログラムを再帰呼び出しで書いた場合。
// リストの全要素を再帰処理で出力
void print( struct List* p ) {
if ( p == NULL ) {
printf( "¥n" ) ;
} else {
printf( "%d " , p->data ) ;
print( p->next ) ;
}
}
// リストの件数を再帰処理でカウント
int count( struct List* p ) {
if ( p == NULL )
return 0 ;
else
return 1 + count( p->next ) ;
}
// リストの合計を再帰処理で求める
int sum( struct List* p ) {
if ( p == NULL )
return 0 ;
else
return p->data + sum( p->next ) ;
}
// リストの最大値を再帰処理で求める
int max( struct List* p ) {
if ( p == NULL ) {
return 0 ;
} else {
int tm = p->data ;
int rm = max( p->next ) ;
return tm > rm ? tm : rm ; // if ( tm > rm )
} // return tm ;
} // else
// return rm ;
// リストの中から指定した値 key を再帰処理で探す
int find( struct List* p , int key ) {
if ( p == NULL )
return 0 ; // 見つからなかった
else if ( p->data == key )
return 1 ; // 見つかった
else
return find( p->next , key ) ;
}
最も単純なリスト先頭への挿入
リスト構造を使うと、必要に応じてメモリを確保しながらデータをつなげることができるので、配列のように最初に最大データ件数を想定した入れ物を最初に作って保存するような処理をしなくて済む。
struct List {
int data ;
struct List* next ;
} ;
// 保存するリストの先頭
struct List* top = NULL ;
void print( struct List* p ) {
for( ; p != NULL ; p = p->next )
// ~~~~~~~~~(A) ~~~~~~~(B)
printf( "%d " , p->data ) ;
// ~~~~~(C) ~~~~~~~(D)
printf( "¥n" ) ;
}//~~~~~~~~~~~~~~(E)
int main() {
int x ;
while( scanf( "%d" , &x ) == 1 ) {
// ~~~~~~~~~~~~~~~~~~(F)
top = cons( x , top ) ;
} // ~~~~~~~~~~~~~~~(G)
print( top ) ; // 前回示したリスト全要素表示
// ~~~~~~~~~~~~(H)
return 0 ; // (生成したリストの廃棄処理は省略)
}
// (1) 入力で、11 , 22 を与えるとどうなる? - 下図参照
// (2) 練習問題(A)~(H)の型は?
// (3) 入力で、11,22 の後に 33 を与えるとどうなる?
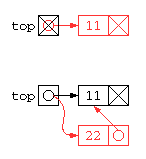
ここで示したコードは、新しい要素を先頭に挿入していく処理となる。このため、作られたリストは、与えられた要素順とは逆順となる。この方法は、リストを管理するポインタが1つで分かりやすい。
授業では、C言語のプログラムを示しているが、C++を使うと LIST 処理もシンプルに記述できるようになっている。参考資料として、C++で同様の処理を示す。テンプレートを使ったコンテナクラスを使うと、struct List {…} といった記述は不要で、std::forward_list<int> という型を使うだけで書けてしまう。
// C++ コンテナクラスで書くと...(auto を使うには C++11 以上) #include <iostream> #include <forward_list> #include <algorithm> int main() { std::forward_list<int> top ; int x ; while( std::cin >> x ) top.push_front( x ) ; for( auto i = top.cbegin() ; i != top.cend() ; ++i ) std::cout << *i << std::endl ; return 0 ; }
要素を末尾に追加して追加順序で保存
前に示した方法は、逆順になるので、追加要素が常に末尾に追加される方法を示す。
struct List* top = NULL ;
struct List** tail = &top ;
int main() {
int x ;
while( scanf( "%d" , &x ) == 1 ) {
// ~~~~~~~~~~~~~~~~~~~~~~~(A)
*tail = cons( x , NULL ) ;
tail = &((*tail)->next) ;
}//~~~~~~~~~~~~~~~~~~~~~~~(B) 下記の解説参照
print( top ) ; // 前回示したリスト全要素表示
// ~~~~~~~~~~~~(C)
return 0 ; // (生成したリストの廃棄処理は省略)
}
// (1) 入力で 11,22 を与えるとどうなる? - 下図参照
// (2) 練習問題(A),(C)の型は?
// (3) 11,22の後に、さらに 33 を与えるとどうなる?
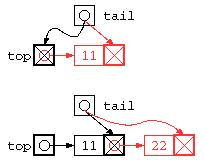
この方法は、次回にデータを追加する場所(末尾の目印のNULLが入っているデータの場所)を覚える方式である。ただし、リストへのポインタのポインタを使う方法なので、少しプログラムがわかりづらいかもしれない。
理解の確認のために、末尾のポインタを動かす部分の式を、型で解説すると以下のようになる。

途中でデータ挿入・データ削除
リスト構造の特徴は、途中にデータを入れたり、途中のデータを抜くのが簡単にできる所。そのプログラムは以下のようになるだろう。
// 指定した途中の場所に要素を挿入
void insert( struct List*p , int data ) {
// p は要素を入れる前のポインタ
// data は追加する要素
// あえて、補助関数consを使わずに書いてみる
struct List* n ;
n = (struct List*)malloc( sizeof( struct List ) ) ;
// ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~(A)
if ( n != NULL ) {
n->data = data ;
// ~~~~(B)
n->next = p->next ;
// ~~~~~~~(C)
p->next = n ;
}
// consを使って書けば、簡単
// p->next = cons( data , p->next ) ;
}
int main() {
struct List* top = cons( 11 , cons( 22 , cons( 44 , NULL ) ) ) ;
// ↑
insert( top->next , 33 ) ; // ここに33を挿入したい
return 0 ; // (生成したリストの廃棄処理は省略)
}
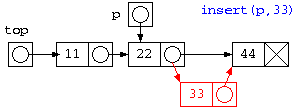
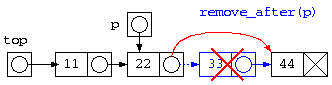
// 指定した場所のデータを消す
void remove_after( struct List* p ) {
struct List* del = p->next ;
p->next = del->next ;
free( del ) ;
}
int main() {
struct List* top = cons( 11 , cons( 22 , cons( 33 , cons( 44 , NULL ) ) ) ) ;
remove_after( top->next ) ; // ↑
// これを消したい
return 0 ; // リストの廃棄処理は省略)
}
理解度確認
上記プログラムinsert() の中の、下線部(A),(B),(C)の型は何か答えよ。
レポート課題
以下に示すようなデータを扱うリスト構造を作り、そのリストを扱うプログラムを作成せよ。
( 出席番号 % 3 ) の番号の課題に取り組むこと。
- 緯度(latitude)経度(longitude)とその場所の都市名(city)
- 名前(name)と誕生日(month,day)(1つの変数に2月7日を0207のように保存するのは禁止)
- 複素数(re,im)
このようなプログラムを作るのであれば、以下の例を参考に。
struct NameAgeList {
char name[ 20 ] ; // 名前
int age ; // 年齢
struct NameAgeList* next ; // 次のデータへのポインタ
} ;
struct NameAgeList* na_cons( char* nm, int ag,
struct NameAgeList*p )
{ struct NameAgeList* ans ;
ans = (struct NameAgeList*)malloc(
sizeof( struct NameAgeList ) ) ;
if ( ans != NULL ) {
strcpy( ans->name , nm ) ;
ans->age = ag ;
ans->next = p ;
}
return ans ;
}
int main() {
struct NameAgeList* top = NULL ;
struct NameAgeList* p ;
char buff[ 1024 ] ;
// 1行読み込みの繰り返し
while( fgets( buff , sizeof( buff ) , stdin ) != NULL ) {
char nm[ 100 ] ;
int ag ;
// 1行の中から名前と年齢があったら na_cons で挿入保存
if ( sscanf( buff , "%s%d" , nm , &ag ) == 2 ) {
top = na_cons( nm , ag , top ) ;
}
}
// 読み込んだデータを全部出力
for( p = top ; p != NULL ; p = p->next )
printf( "%s %d¥n" , p->name , p->age ) ;
return 0 ; // リストの廃棄処理は省略)
}