前回の授業で説明したハッシュ法は、データから簡単な計算(ハッシュ関数)で求まるハッシュ値をデータの記憶場所とする。しかし、異なるデータでも同じハッシュ値が求まった場合、どうすれば良いか?
ハッシュ法を簡単なイメージで説明すると、100個の椅子(ハッシュ表)が用意されていて、1クラスの学生が自分の電話番号の末尾2桁(ハッシュ関数)の場所(ハッシュ値)に座るようなもの。自分のイスに座ろうとしたら、同じハッシュ値の人が先に座っていたら、どこに座るべきだろうか?
オープンアドレス法
先の椅子取りゲームの例え話であれば、先に座っている人がいた場合、最も簡単な椅子に座る方法は、隣が空いているか確認して空いていたらそこに座ればいい。
これをプログラムにしてみると、以下のようになる。このハッシュ法は、求まったアドレスの場所にこだわらない方式でオープンアドレス法と呼ばれる。
// オープンアドレス法
// table[] は大域変数で0で初期化されているものとする。
// 配列に電話番号と名前を保存
void entry( int phone , name ) {
int idx = hash_func( phone ) ;
while( table[ idx ].phone != 0 )
idx = (idx + 1) % HASH_SIZE ; // ひとつ後ろの席
} // idx++ でないのは何故?
table[ idx ].phone = phone ;
strcpy( table[ idx ].name , name ) ;
}
// 電話番号から名前を調べる
char* search( int phone ) {
int idx = hash_func( phone ) ;
while( table[ idx ].phone != 0 ) {
if ( table[ idx ].phone == phone )
return table[ idx ].name ;
idx = (idx + 1) % HASH_SIZE ; // ひとつ後ろの席
} // idx++ でないのは何故?
return NULL ; // 見つからなかった
}
注意:このプログラムは、ハッシュ表すべてにデータが埋まった場合、無限ループとなるので、実際にはもう少し改良が必要である。
この実装方法であれば、ハッシュ表にデータが少ない場合は、ハッシュ値を計算すれば終わり。よって、処理時間のオーダはO(1)となる。しかし、ハッシュ表がほぼ埋まっている状態だと、残りわずかな空き場所を探すようなもの。
チェイン法
前に述べたオープンアドレス法は、ハッシュ衝突が発生した場合、別のハッシュ値を求めそこに格納する。配列で実装した場合であれば、ハッシュ表のサイズ以上の データ件数を保存することはできない。
チェイン法は、同じハッシュ値のデータをグループ化して保存する方法。 同じハッシュ値のデータは、リスト構造とするのが一般的。ハッシュ値を求めたら、そのリスト構造の中からひとつづつ目的のデータを探す処理となる。
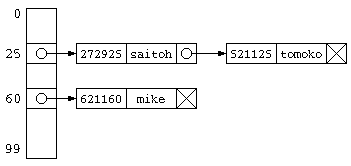
この処理にかかる時間は、データ件数が少なければ、O(1) となる。しかし、ハッシュ表のサイズよりかなり多いデータ件数が保存されているのであれば、ハッシュ表の先に平均「N/ハッシュ表サイズ」件のデータがリスト構造で並んでいることになるので、O(N) となってしまう。
#define SIZE 100
int hash_func( int ph ) {
return ph % SIZE ;
}
struct PhoneNameList {
int phone ;
char name[ 20 ] ;
struct PhoneNameList* next ;
} ;
struct PhoneNameList* hash[ SIZE ] ; // NULLで初期化
struct PhoneNameList* cons( int ph ,
char* nm ,
struct PhoneNameList* nx ) {
struct PhoneNameList* ans ;
ans = (struct PhoneNameList*)malloc(
sizeof( struct PhoneNameList ) ) ;
if ( ans != NULL ) {
ans->phone = ph ;
strcpy( ans->name , nm ) ;
ans->next = nx ;
}
return ans ;
}
void entry( int phone , char* name ) {
int idx = hash_func( phone ) ;
hash[ idx ] = cons( phone , name , hash[ idx ] ) ;
}
char* search( int phone ) {
int idx = hash_func( phone ) ;
struct PhoneNameList* p ;
for( p = hash[ idx ] ; p != NULL ; p = p->next ) {
if ( p->phone == phone )
return p->name ;
}
return NULL ;
}
これまでの授業の中では、データを効率よく扱うためのデータ構造について議論をしてきた。これまでのプログラムの中では、データ構造のために動的メモリ(特にヒープメモリ)を多用してきた。ヒープメモリでは、malloc() 関数により指定サイズのメモリ空間を借りて、処理が終わったら free() 関数によって返却をしてきた。この返却を忘れたままプログラムを連続して動かそうとすると、返却されなかったメモリが使われない状態(メモリリーク)となり、メモリ領域不足から他のプログラムの動作に悪影響を及ぼす。
メモリリークを防ぐためには、malloc() で借りたら、free() で返すを実践すればいいのだが、複雑なデータ構造になってくると、こういった処理が困難となる。そこで、ヒープメモリの問題点について以下に説明する。
共有のあるデータの取扱の問題
リスト構造で集合計算の和集合を求める処理を考える。
// 集合和を求める処理
struct List* join( struct List* a , struct List* b )
{ struct List* ans = b ;
for( ; a != NULL ; a = a->next )
if ( !find( ans , a->data ) )
ans = cons( a->data , ans ) ;
return ans ;
}
void list_del( struct List* p )
{ // ダメなプログラムの例
while( p != NULL ) { // for( ; p != NULL ; p = p->next )
struct List* d = p ; // free( p ) ;
p = p->next ;
free( d ) ;
}
}
void main() {
// リストの生成
struct List* a = cons( 1 , cons( 2 , cons( 3 , NULL ) ) ) ;
struct List* b = cons( 2 , cons( 3 , cons( 4 , NULL ) ) ) ;
struct List* c = join( a , b ) ; // c = { 1, 2, 3, 4 }
// ~~~~~~~ ここは b
// a,b,cを使った処理
// 処理が終わったのでa,b,cを捨てる
list_del( a ) ;
list_del( b ) ;
list_del( c ) ; // list_del(b)ですでに消えている
} // このためメモリー参照エラー発生
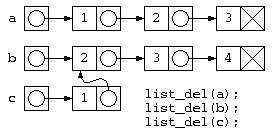
このようなプログラムでは、c=join(a,b) ; が終わると下の図のようなデータ構造となる。しかし処理が終わってリスト廃棄list_del(a), list_del(b), listdel(c)を行おうとすると、bの先のデータは廃棄済みなのに、list_del(c)の実行時に、その領域を触ろうとして異常が発生する。
実体をコピーする方法
こういった共有の問題の一つの解決法としては、共有が発生しないように実体を別にコピーする方法もある。しかし、この方法はメモリがムダになる場合もあるし、List内のデータを修正した時に、実体をコピーした部分でも修正が反映されてほしい場合に問題となる。
// 実体をコピーする(簡潔に書きたいので再帰を使う) struct List* copy( struct List* p ) { if ( p != NULL ) return cons( p->data , copy( p->next ) ) ; else return NULL ; } // 共有が無い集合和を求める処理 struct List* join( struct List* a , struct List* b ) { struct List* ans = copy( b ) ; // ~~~~~~~~~実体をコピー for( ; a != NULL ; a = a->next ) if ( !find( ans , a->data ) ) ans = cons( a->data , ans ) ; return ans ; }
参照カウンタ法
上記の問題は、b の先のリストが c の一部とデータを共有しているために発生する。この解決方法として簡単な方法では、参照カウンタ法が用いられる。
参照カウンタ法では、データを参照するポインタの数をデータと共に保存する。
- データの中にポインタ数を覚える参照カウンタを設け、データを生成した時に1とする。
- 処理の中で共有が発生すると、参照カウンタをカウントアップする。
- データを捨てる際には、参照カウンタをカウントダウンし、0になったら本当にそのデータを消す。
struct List {
int refc ; // 参照カウンタ
int data ; // データ
struct List* next ; // 次のポインタ
} ;
struct List* cons( int x , struct List* p ) {
struct List* n = (struct List*)malloc( sizeof( struct List* ) ) ;
if ( n != NULL ) {
n->refc = 1 ; // 初期状態は参照カウンタ=1
n->data = x ;
n->next = p ;
}
return n ;
}
struct List* copy( struct List* p ) {
p->refc++ ; // 共有が発生したら参照カウンタを増やす。
return p ;
}
// 集合和を求める処理
struct List* join( struct List* a , struct List* b )
{
struct List* ans = copy( b ) ;
// ~~~~~~~~~共有が発生するのでrefc++
for( ; a != NULL ; a = a->next )
if ( !find( ans , a->data ) )
ans = cons( a->data , ans ) ;
return ans ;
}
void list_del( strcut List* p ) { // 再帰で全廃棄
if ( p != NULL
&& --(p->refc) <= 0 ) { // 参照カウンタを減らし
// ~~~~~~~~~~~
list_del( p->next ) ; // 0ならば本当に消す
free( p ) ;
}
}
int main() { // リストの生成
struct List* a = cons( 1 , cons( 2 , cons( 3 , NULL ) ) ) ;
struct List* b = cons( 2 , cons( 3 , cons( 4 , NULL ) ) ) ;
struct List* c = join( a , b ) ;
// a,b,cを使った処理
// 処理が終わったのでa,b,cを捨てる
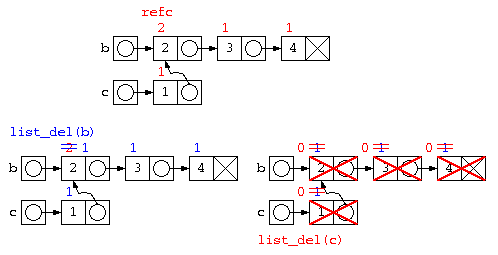
list_del( a ) ; // aの要素は全部refc=1なので普通に消えていく
list_del( b ) ; // bは、joinの中のcopy時にrefc=2なので、
// この段階では、refc=2 から refc=1 になるだけ
list_del( c ) ; // ここで全部消える。
}
unix i-nodeで使われている参照カウンタ
unixのファイルシステムの基本的構造 i-node では、1つのファイルを別の名前で参照するハードリンクという機能がある。このため、ファイルの実体には参照カウンタが付けられている。unix では、ファイルを生成する時に参照カウンタを1にする。ハードリンクを生成すると参照カウンタをカウントアップ”+1″する。ファイルを消す場合は、基本的に参照カウンタのカウントダウン”-1″が行われ、参照カウンタが”0″になるとファイルの実体を消去する。
以下に、unix 環境で 参照カウンタがどのように使われているのか、コマンドで説明していく。
$ echo a > a.txt
$ ls -al *.txt
-rw-r--r-- 1 t-saitoh t-saitoh 2 12月 21 10:07 a.txt
~~~ # ここが参照カウンタの値
$ ln a.txt b.txt # ハードリンクでコピーを作る
$ ls -al *.txt
-rw-r--r-- 2 t-saitoh t-saitoh 2 12月 21 10:07 a.txt
-rw-r--r-- 2 t-saitoh t-saitoh 2 12月 21 10:07 b.txt
~~~ # 参照カウンタが増えているのが分かる
$ rm a.txt # 元ファイルを消す
$ ls -al *.txt
-rw-r--r-- 1 t-saitoh t-saitoh 2 12月 21 10:07 b.txt
~~~ # 参照カウンタが減っている
$ ln -s b.txt c.txt # シンボリックリンクでコピーを作る
$ ls -al *.txt
-rw-r--r-- 1 t-saitoh t-saitoh 2 12月 21 10:07 b.txt
lrwxrwxrwx 1 t-saitoh t-saitoh 5 12月 21 10:10 c.txt -> b.txt
$ rm b.txt # 元ファイルを消す
$ ls -al *.txt
lrwxrwxrwx 1 t-saitoh t-saitoh 5 12月 21 10:10 c.txt -> b.txt
$ cat c.txt # c.txt は存在するけどその先の実体 b.txt は存在しない
cat: c.txt: そのようなファイルやディレクトリはありません