情報構造論のテストを返却。 25点満点5問出題で4問選択だから、普通に勉強していれば80点 (平均79点)といった状態。 テストとレポートを返却して、解説を行う。 時間が少し余ったので、テスト前の続きということでハッシュ法(チェイン法)を説明する。
チェイン法
チェイン法の最初に説明した方法は、オープンアドレス法で、 ハッシュ衝突が発生したデータは、本来の場所をはずれて次の場所に保管… といった方法をとっていた。しかしながら、単純なオープンアドレス法では、 ハッシュ表サイズ以上のデータを覚えられない。
チェイン法では、同じハッシュ値になったデータをリストに連結して保存する方式。
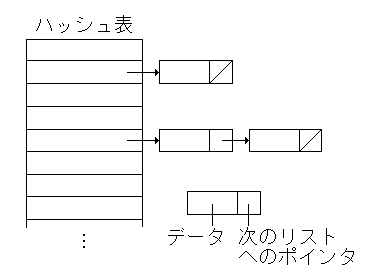
// 電話番号をハッシュ法で保存する。
struct List {
int phone ;
struct List* next ;
} ;
struct List* hash[ SIZE ] ; // NULLで初期化
void entry( int ph ) {
int idx = hash_func( ph ) ;
// 授業ではリストの説明の際の補助関数で説明
// hash[ idx ] = cons( ph , hash[ idx ] ) ;
struct List* p ;
p = (struct List*)malloc( sizeof( struct List ) ) ;
if ( p != NULL ) {
p->phone = ph ;
p->next = hash[ idx ] ;
hash[ idx ] = p ;
}
}
// hash表に登録されているか?
int find( int ph ) {
int idx = hash_func( ph ) ;
struct List* p ;
for( p = hash[ idx ] ; p != NULL ; p = p->next ) {
if ( p->phone == ph )
return 1 ;
}
return 0 ;
}
チェイン法の処理速度を考えると、データ件数がハッシュ表より小さい間は、 ほぼリストの先には1件のデータしか入っていない。 このため検索時間は、ほぼハッシュ値計算の一定時間であり、 となる。
しかし、データ件数Nが、ハッシュ表のサイズを超えると、 リストの先に平均「データ件数/ハッシュ表サイズ」件の要素が連なる。 よって、検索時間はデータ件数に比例し、 となる。

うーむ、説明用にいい図はないかと、「チェイン法、オーダー」で画像検索したら、 オーダーメードの装飾品ばっかり…