先週に、2重の繰り返し処理の時間分析をやったので、次のステップに。
2分探索法の処理時間
データを探す処理において、単純検索より速い方法ということで、2分探索法の処理速度見積もりを行う。
// 2分探索法 O(log N)
int a[ 1000 ] = { 対象となるデータ } ;
int size = N ; // データ数 N
int L = 0 ; // L=下限のデータの場所
int R = size ; // R=上限のデータ+1の場所
while( L != R ) {
int M = (L + R) / 2 ; // 計算は整数型で行われることに注意
if ( a[M] == key ) // 見つかった
break ;
else if ( a[M] < key ) // |L |M. |R
L = M + 1 ; // |----------|-+---------|
else // |L---------|M|
R = M ; // |M+1------|R
}
上記のようなプログラムの場合、処理に要する時T(N)は、
処理は、対象となるデータ件数が繰り返し毎に半分(正確には(N-1)/2だけどここでは厳密な分析はしない)となり、対象データ件数が1件になれば処理が終わる。このことから、データ件数Nとループ回数Mの間には以下の関係が成り立つ。
よって の関係が成り立つ。よって、
は、以下のように表せる。
# T(N)の式の中では、logの底については書かないことが一般的。(後の練習問題を参照)
単純なソート(最大選択法)の処理時間
次に、並べ替え処理の処理時間について考える。
int a[ 1000 ] = { 対象となるデータ } ;
int size = N ;
for( int i = 0 ; i < size - 1 ; i++ ) {
int tmp ;
// i..size-1 の範囲で一番大きいデータの場所を探す
int m = i ;
for( int j = i + 1 ; j < size ; j++ ) {
if ( a[j] > a[m] )
m = j ;
}
// 一番大きいデータを先頭に移動
tmp = a[i] ;
a[i] = a[m] ;
a[m] = tmp ;
}
このプログラムの処理時間T(N)は… (参考 数列の和の公式)
となる。
オーダー記法
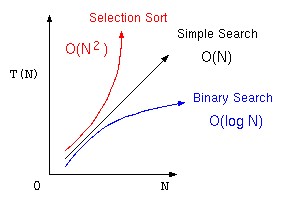
ここまでのアルゴリズムをまとめると以下の表のようになる。ここで処理時間に大きく影響する部分は、最後の項の部分であり、特にその項の係数は、コンピュータの処理性能に影響を受けるが、アルゴリズムの優劣を考える場合は、それぞれ、
の部分の方が重要である。
| 単純サーチ | |
| 2分探索法 | |
| 最大選択法 |
そこで、アルゴリズムの優劣を議論する場合は、この処理時間の見積もりに最も影響する項で、コンピュータの性能によって決まる係数を除いた部分を抽出した式で表現する。これをオーダー記法と言う。
| 単純サーチ | オーダーNのアルゴリズム | |
| 2分探索法 | オーダー log N のアルゴリズム | |
| 最大選択法 | オーダー N2 のアルゴリズム |
練習問題
- ある処理のデータ数Nに対する処理時間が、
であった場合、オーダー記法で書くとどうなるか?
- コンピュータで2分探索法で、データ100件で10[μsec]かかったとする。
データ10000件なら何[sec]かかるか?
(ヒント: 底変換の公式) の処理時間を要するアルゴリズムを、オーダー記法で書くとどうなるか?また、このようなアルゴリズムの例を答えよ。
の処理時間を要するアルゴリズムを、オーダー記法で書くとどうなるか?
(ヒント: ロピタルの定理)
- 2と4の解説
- 1は、N→∞において、N2<<2Nなので、O(2N) 。厳密に回答するなら、練習問題4と同様の説明を行う。
- 3は、O(1)。誤答の例:O(0)と書いちゃうと、T(N)=Tα×0=0になってしまう。事例は、電話番号を、巨大配列の”電話番号”番目の場所に記憶するといった方法。(これはハッシュ法で改めて講義予定)
再帰呼び出しの予習
次の講義の基礎を確認という意味で、再帰呼出しと簡単な処理の例を説明する。
最初に定番の階乗(fact)

次に、フィボナッチ数列の場合

次の講義への導入問題
ここで示す導入問題をすべて答えるには、若干の予習が必要です。まずはどういう考え方をすれば解けるかな…を考えてみてください。
- fact(N)の処理時間を、
のような式で表現し、処理時間をオーダ記法で答えよ。
- 以下のプログラムの実行結果を答えよ。また、関数sum()の処理時間を対象となるデータ件数N=R-Lを用いて
のような式で表現せよ。
int a[] = { 1 , 5 , 8 , 9 , 2 , 3 , 4 , 7 } ;
int sum( int a[] , int L , int R ) {
if ( R-L == 1 ) {
return a[L] ;
} else {
int M = (L + R) / 2 ;
return sum( a , L , M ) + sum( a , M , R ) ;
}
}
int main() {
printf( "%d¥n" , sum( a , 0 , 8 ) ) ;
return 0 ;
}