隠ぺい化の次のステップとして、派生・継承を説明する。オブジェクト指向プログラミングでは、一番基本となるデータ構造を宣言し、その基本構造に様々な機能を追加した派生クラスを記述することでプログラムを作成する。今回は、その派生を理解するためにC言語で発生する問題点を考える。
派生を使わずに書くと…
元となるデータ構造(例えばPersonが名前と年齢)でプログラムを作っていて、 途中でその特殊パターンとして、所属と学年を加えた学生(Student)という データ構造を作るとする。
// 元となる構造体(Person) / 基底クラス
struct Person {
char name[ 20 ] ; // 名前
int age ; // 年齢
} ;
// 初期化関数
void set_Person( struct Person* p ,
char s[] , int x ) {
strcpy( p->name , s ) ;
p->age = x ;
}
// 表示関数
void print_Person( struct Person* p ) {
printf( "%s %d\n" , p->name , p->age ) ;
}
int main() {
struct Person saitoh ;
set_Person( &saitoh , "t-saitoh" , 50 ) ;
print_Person( &saitoh ) ;
return 0 ;
}
パターン1(そのまんま…)
上記のPersonに、所属と学年を加えるのであれば、以下の方法がある。 しかし以下パターン1は、要素名がname,ageという共通な部分があるようにみえるが、 プログラム上は、PersonとPersonStudent1は、まるっきり関係のない別の型にすぎない。
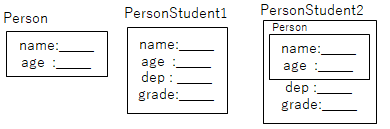
このため、元データと共通部分があっても、同じ処理を改めて書き直しになる。(プログラマーの手間が減らせない)
// 元のデータに追加要素(パターン1)
struct PersonStudent1 {
// Personと同じ部分
char name[ 20 ] ; // 名前
int age ; // 年齢
// 追加部分
char dep[ 20 ] ; // 所属
int grade ; // 学年
} ;
void set_PersonStudent1( struct PersonStudent1* p ,
char s[] , int x ,
char d[] , int g ) {
// set_Personと同じ処理を書いている。
strcpy( p->name , s ) ;
p->age = x ;
// 追加された処理
strcpy( p->dep , d ) ;
p->grade = g ;
}
// 名前と年齢 / 所属と学年を表示
void print_PersonStudent1( struct PersonStudent1* p ) {
// print_Personと同じ処理を書いている。
printf( "%s %d\n" , p->name , p->age ) ;
printf( "- %s %d¥n" , p->dep , p->grade ) ;
}
int main() {
struct PersonStudent1 yama1 ;
set_PersonStudent1( &yama1 ,
"yama" , 22 , "PS" , 2 ) ;
print_PersonStudent1( &yama1 ) ;
return 0 ;
}
パターン2(元データの処理を少し使って…)
パターン1では、機能が追加された新しいデータ構造のために、同じような処理を改めて書くことになりプログラムの記述量を減らせない。面倒なので、 元データ用の関数をうまく使うように書いてみる。
// 元のデータに追加要素(パターン2)
struct PersonStudent2 {
// 元のデータPerson
struct Person person ;
// 追加部分
char dep[ 20 ] ;
int grade ;
} ;
void set_PersonStudent2( struct PersonStudent2* p ,
char s[] , int x ,
char d[] , int g ) {
// Personの関数を部分的に使う
set_Person( &(p->person) , s , x ) ;
// 追加分はしかたない
strcpy( p->dep , d ) ;
p->grade = g ;
}
void print_PersonStudent2( struct PersonStudent2* p ) {
// Personの関数を使う。
print_Person( &p->person ) ;
printf( "- %s %d¥n" , p->dep , p->grade ) ;
}
int main() {
struct PersonStudent2 yama2 ;
set_PersonStudent2( &yama2 ,
"yama" , 22 , "PS" , 2 ) ;
print_PersonStudent2( &yama2 ) ;
return 0 ;
}
このパターン2であれば、元データ Person の処理をうまく使っているので、 プログラムの記述量を減らすことはできるようになった。
しかし、print_PersonStudent2() のような処理は、名前と年齢だけ表示すればいいという場合、元データ構造が同じなのに、 PersonStudent2 用のプログラムをいちいち記述するのは面倒ではないか?
そこで、元データの処理を拡張し、処理の流用ができないであろうか?
基底クラスから派生クラスを作る
オブジェクト指向では、元データ(基底クラス)に新たな要素を加えたクラス(派生クラス)を 作ることを「派生」と呼ぶ。派生クラスを定義するときは、クラス名の後ろに、 「:」,「public/protected/private」, 基底クラス名を書く。
// 基底クラス
class Person {
private:
char name[ 20 ] ;
int age ;
public:
Person( const char s[] , int x )
: age( x ) {
strcpy( name , s ) ;
}
void print() {
printf( "%s %d\n" , name , age ) ;
}
} ;
// 派生クラス(Student は Person から派生)
class Student : public Person {
private:
// 追加部分
char dep[ 20 ] ;
int grade ;
public:
Student( const char s[] , int x ,
const char d[] , int g )
: Person( s , x ) // 基底クラスのコンストラクタ
{ // 追加された処理
strcpy( dep , d ) ;
grade = g ;
}
} ;
int main() {
Person saitoh( "t-saitoh" , 50 ) ;
saitoh.print() ;
Student yama( "yama" , 22 , "PS" , 2 ) ;
yama.print() ; // "yama 22"が表示される
return 0 ;
}
ここで注目すべき点は、main()の中で、Studentクラス”yama”に対し、yama.print() を呼び出しているが、パターン2であれば、print_PersonStudent2()に相当するプログラムを 記述していない。 しかし、この派生を使うと Person の print() が自動的に流用することができる。 これは、基底クラスのメソッドを「継承」しているから、 このように書け、名前と年齢「yama 22」が表示される。
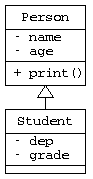
さらに、Student の中に、以下のような Student 専用の新しい print()を記述してもよい。
class Student ...略... {
...略...
// Student クラス専用の print()
void print() {
// 親クラス Person の print() を呼び出す
Person::print() ;
// Student クラス用の処理
printf( "%s %d\n" , dep , grade ) ;
}
} ;
void main() {
...略...
Student yama( "yama" , 22 , "PS" , 2 ) ;
yama.print() ;
}
この場合は、継承ではなく機能が上書き(オーバーライト)されるので、 「yama 22 / PS 2」が表示される。
派生クラスを作る際の後ろに記述した、public は、他にも protected , private を 記述できる。
public だれもがアクセス可能。
protected であれば、派生クラスからアクセスが可能。
派生クラスであれば、通常は protected で使うのが一般的。
private 派生クラスでもアクセス不可。
C言語で無理やりオブジェクト指向の”派生”を使う方法
オブジェクト指向の機能の無いC言語で、このような派生と継承を実装する場合には、共用体を使う以下のようなテクニックが使われていた。
unix の GUI である X11 でも共用体を用いて派生を実装していた。// 基底クラス struct PersonBase { // 基底クラス char name[ 20 ] ; int age ; } ; struct PersonStudent { // 派生クラス struct PersonBase base ; char dep[ 20 ] ; int grade ; } ; //(base) //(student) union Person { // name //[name] struct PersonBase base ; // age //[age ] struct PersonStudent student ; // dep } ; // grade void person_Print( struct Person* p ) { printf( "%s %d\n" , p->base.name , p->base.age ) ; } int main() { struct PersonBase tsaitoh = { "tsaitoh" , 55 } ; struct PersonStudent mitsuki = { { "mitsuki" , 21 } , "KIT" , 4 } ; print_Person( (struct Person*)&tsaitoh ) ; print_Person( (struct Person*)&mitsuki ) ; // 無理やり print_Person を呼び出す return 0 ; }
仮想関数への伏線
上記のような派生したプログラムを記述した場合、以下のようなプログラムでは何が起こるであろうか?
class Student ... {
:
void print() {
Person::print() ; // 名前と年齢を表示
printf( " %s %d¥n" , dep , grade ) ; // 所属と学年を表示
}
} ;
int main() {
Person saitoh( "t-saitoh" , 55 ) ;
saitoh.print() ; // t-saitoh 55 名前と年齢を表示
Student mitsu( "mitsuki" , 20 , "KIT" , 3 ) ;
Student ayuka( "ayuka" , 18 , "EI" , 4 ) ;
mitsu.print() ; // mitsuki 20 / KIT 3 名前,年齢,所属,学年を表示
ayuka.print() ; // ayuka 18 / EI 4 名前,年齢,所属,学年を表示
Person* family[] = {
&saitoh , &mitsu , &ayuka , // 配列の中に、Personへのポインタと
} ; // Studentへのポインタが混在している
// 派生クラスのポインタは、
// 基底クラスのポインタとしても扱える
for( int i = 0 ; i < 3 ; i++ )
family[ i ]->print() ; // t-saitoh 55/mitsuki 20/ayuka 18
return 0 ; // が表示される。
} // # "mitsuki 20/KIT 3" とか "ayuka 18/EI 4"
// # が表示されてほしい?