前回の授業の復習と練習問題
前回の授業では、for ループによる繰り返し処理のプログラムについて、処理時間を T(N) の一般式で表現することを説明し、それを用いたオーダー記法について説明を行った。理解を確認するための練習問題を以下に示す。
練習問題
- ある処理のデータ数Nに対する処理時間が、
であった場合、オーダー記法で書くとどうなるか?
の処理時間を要するアルゴリズムを、オーダー記法で書くとどうなるか?また、このような処理時間となるアルゴリズムの例を答えよ。
の処理時間を要するアルゴリズムを、オーダー記法で書くとどうなるか?
(ヒント: ロピタルの定理)
- 1は、N→∞において、N2 ≪ 2Nなので、O(2N) 。厳密に回答するなら、練習問題3と同様の証明を行うべき。
- 2は、O(1)。誤答の例:O(0)と書いちゃうと、T(N)=Tα×0=0になってしまう。事例は、電話番号を、巨大配列の”電話番号”番目の場所に記憶するといった方法。(これはハッシュ法で改めて講義予定)
- 3の解説
再帰呼び出しの基本
次に、再帰呼び出しを含むような処理の処理時間見積もりについて解説をおこなう。そのまえに、再帰呼出しと簡単な処理の例を説明する。
再帰関数は、自分自身の処理の中に「問題を小さくした」自分自身の呼び出しを含む関数。プログラムには問題が最小となった時の処理があることで、再帰の繰り返しが止まる。
// 階乗 (末尾再帰)
int fact( int x ) {
if ( x <= 1 )
return 1 ;
else
return x * fact( x-1 ) ;
}
// ピラミッド体積 (末尾再帰)
int pyra( int x ) {
if ( x <= 1 )
return 1 ;
else
return x*x + pyra( x-1 ) ;
}
// フィボナッチ数列 (非末尾再帰)
int fib( int x ) {
if ( x <= 2 )
return 1 ;
else
return fib( x-1 ) + fib( x-2 ) ;
}
階乗 fact(N) を求める処理は、以下の様に再帰が進む。

また、フィボナッチ数列 fib(N) を求める処理は以下の様に再帰が進む。

再帰呼び出しの処理時間
次に、この再帰処理の処理時間を説明する。 最初のfact(),pyra()については、 x=1の時は、関数呼び出し,x<=1,return といった一定の処理時間を要し、T(1)=Ta で表せる。 x>1の時は、関数呼び出し,x<=1,*,x-1,returnの処理(Tb)に加え、x-1の値で再帰を実行する処理時間T(N-1)がかかる。 このことから、 T(N)=Tb=T(N-1)で表せる。
} 再帰方程式
このような、式の定義自体を再帰を使って表した式は再帰方程式と呼ばれる。これを以下のような代入の繰り返しによって解けば、一般式 が得られる。
T(1)=Ta
T(2)=Tb+T(1)=Tb+Ta
T(3)=Tb+T(2)=2×Tb+Ta
:
T(N)=Tb+T(N-1)=Tb + (N-2)×Tb+Ta
一般的に、再帰呼び出しプログラムは(考え方に慣れれば)分かりやすくプログラムが書けるが、プログラムを実行する時には、局所変数や関数の戻り先を覚える必要があり、深い再帰ではメモリ使用量が多くなる。
ただし、fact() や pyra() のような関数は、プログラムの末端で再帰が行われている。(fib()は、再帰の一方が末尾ではない)
このような再帰は、末尾再帰(tail recursion) と呼ばれ、関数呼び出しの return を、再帰処理の先頭への goto 文に書き換えるといった最適化が可能である。言い換えるならば、末尾再帰の処理は繰り返し処理に書き換えが可能である。このため、末尾再帰の処理をループにすれば再帰のメモリ使用量の問題を克服できる。
再帰を含む一般的なプログラム例
ここまでのfact()やpyra()のような処理の再帰方程式は、再帰の度にNの値が1減るものばかりであった。もう少し一般的な再帰呼び出しのプログラムを、再帰方程式で表現し、処理時間を分析してみよう。
以下のプログラムを実行したらどんな値になるであろうか?それを踏まえ、処理時間はどのように表現できるであろうか?
int array[ 8 ] = {
3 , 6 , 9 , 1 , 8 , 2 , 4 , 5 ,
} ;
int sum( int a[] , int L , int R ) { // 非末尾再帰
if ( R - L == 1 ) {
return a[ L ] ;
} else {
int M = (L + R) / 2 ;
return sum( a , L , M ) + sum( a , M , R ) ;
}
}
int main() {
printf( "%d¥n" , sum( array , 0 , 8 ) ) ;
return 0 ;
}
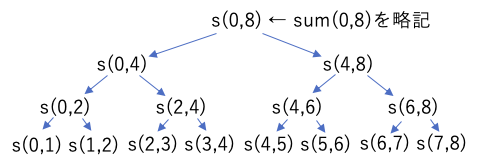
このプログラムでは、配列の合計を計算しているが、引数の L,R は、合計範囲の 左端(左端のデータのある場所)・右端(右端のデータのある場所+1)を表している。そして、再帰のたびに2つに分割して解いている。
このような、処理を(この例では半分に)分割し、分割したそれぞれを再帰で計算し、その処理結果を組み合わせて最終的な結果を求めるような処理方法を、分割統治法と呼ぶ。
このプログラムでは、対象となるデータ件数(R-L)をNとおいた場合、実行される命令からsum()の処理時間Ts(N)は次の再帰方程式で表せる。
← Tβ + (L〜M)の処理時間 + (M〜R)の処理時間
これを代入の繰り返しで解いていくと、
ということで、このプログラムの処理時間は、 で表せる。