リスト構造
リスト構造は、データと次のデータへのポインタで構成され、必要に応じてメモリを確保することで、配列の上限が制限にならないようにする。また、次のデータへのポインタでつなげているため、途中へのデータ挿入が簡単にできるようにする。
struct List {
int data ;
struct List* next ;
} ;
struct List* top ;
top = (struct List*)malloc( sizeof( struct List ) ) ;
top->data = 111 ;
top->next = (struct List*)malloc( sizeof( struct List ) ) ;
top->next->data = 222 ;
top->next->next = (struct List*)malloc( sizeof( struct List ) ) ;
top->next->next->data = 333 ;
top->next->next->next = NULL ; // 末尾データの目印
struct List*p ;
for( p = top ; p != NULL ; p = p->next ) {
printf( "%d¥n" , p->data ) ;
}

補助関数
上記のプログラムでは、(struct…)malloc(sizeof(…))を何度も記載し、プログラムが分かりにくいので、以下に示す補助関数を使うと、シンプルに記載できる。
struct List* cons( int x , struct List* n ) {
struct List* ans ;
ans = (struct List*)malloc( sizeof( struct List ) ) ;
if ( ans != NULL ) {
ans->data = x ;
ans->next = n ;
}
return ans ;
}
struct List* top ;
top = cons( 111 , cons( 222 , cons( 333 , NULL ) ) ) ;
補助関数の名前の cons は、constructor の略であり、古くから使われている List Processor(LISP) というプログラム言語でのリスト(セル)を生成する関数が cons 。
LISPと関数型プログラミング言語
LISPの歴史は長く、最古のFORTRAN,COBOLに次ぐ3番目ぐらい。最初は、人工知能のプログラム開発のための関数型プログラミング言語として作られた。特徴として、データもプログラムもすべてリスト構造(S式)で表すことができ、プログラムは関数型に基づいて作られる。
関数型プログラミングは、Ruby や Python でも取り入れられている。関数型プログラミングは、処理を関数をベースに記述することで「副作用を最小限にすることができ」、極端な話をすればループも再帰呼出しで書けばいい…。
LISPの処理系は、最近では Scheme などが普通だが、プログラムエディタの Emacs は、内部処理が LISP で記述されている。
簡単なリスト処理の例
先に示したリスト構造について簡単なプログラム作成を通して、プログラミングに慣れてみよう。
// 全要素を表示する関数
void print( struct List* p ) {
for( ; p != NULL ; p = p->next )
printf( "%d " , p->data ) ;
printf( "¥n" ) ;
}
// データ数を返す関数
int count( struct List* p ) {
int c = 0 ;
for( ; p != NULL ; p = p->next )
c++ ;
return c ;
}
void main() {
struct List* top = cons( 111 , cons( 444 , cons( 333 , NULL ) ) ) ;
print( top ) ;
printf( "%d¥n" , count( top ) ) ;
}
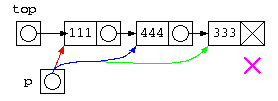
リスト処理を自分で考えて作成
以下のようなプログラムを作ってみよう。意味がわかって慣れてくれば、配列の部分の for の回し方が変わっただけということに慣れてくるだろう。
// 全要素の合計
int sum( struct List* p ) {
// sum( top ) → 888
自分で考えよう
}
// リストの最大値を返す
int max( struct List* p ) {
// max( top ) → 444 (データ件数0の場合0を返す)
自分で考えよう
}
// リストの中から指定した値の場所を返す
int find( struct List* p , int key ) {
// find( top , 444 ) = 1 (先頭0番目)
// 見つからなかったら -1
自分で考えよう
}
再帰呼び出しでリスト処理
リスト処理の応用のプログラムを作るなかで、2分木などのプログラミングでは、リスト処理で再帰呼出しを使うことも多いので、先に示したプログラムを再帰呼び出しで書いたらどうなるであろうか?
// 全データを表示
void print( struct List* p ) {
if ( p == NULL ) {
printf( "¥n" ) ;
} else {
printf( "%d " , p->data ) ;
print( p->next ) ; // 末尾再帰
}
}
// データ数を返す関数
int count( struct List* p ) {
if ( p == NULL )
return 0 ;
else
return 1 + count( p->next ) ; // 末尾再帰
}
// 全要素の合計
int sum( struct List* p ) {
// sum( top ) → 888
自分で考えよう
}
// リストの最大値を返す
int max( struct List* p ) {
// max( top ) → 444 (データ件数0の場合0を返す)
自分で考えよう
}
// リストの中から指定した値を探す。
int find( struct List* p , int key ) {
// find( top , 444 ) = 1
// 見つかったら1 , 見つからなかったら 0
自分で考えよう
}
理解度確認
上記プログラム中の sum() , max() , find() を再帰呼び出しをつかって記述せよ。