SQLの基礎
前回の講義で、データベースでは、記録されているデータの読み書きは、SQL で行われ、射影・結合・選択を表す処理で構成されることを示した。SQL の機能を理解するために、同じ処理を C 言語で書いたらどうなるのかを示す。
SELECT S.業者番号 -- 必要とされるデータを抽出する射影 --
FROM S -- 複数のテーブルを組合せる結合 --
WHERE S.優良度 >= 20 ; -- 対象となるデータを選び出す選択 --
// 配列の個数を求める #define 文
#define sizeofarray(ARY) (sizeof(ARY) / sizeof(ARY[0]))
// C言語なら... S のデータを構造体宣言で書いてみる。
struct Table_S {
char 業者番号[ 6 ] ;
char 業者名[ 22 ] ;
int 優良度 ;
char 所在[ 16 ] ;
} S[] = {
{ "S1" , "ABC社" , 20 , "福井" } ,
:
} ;
// 結合
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
// 選択
if ( S[i].優良度 >= 20 )
// 射影
printf( "%d¥n" , S[i].業者番号 ) ;
}
Sは、テーブル名であり、文脈上対象テーブルが明らかな場合、フィールド名の前の テーブルは省略可能である。
SELECT 業者番号 FROM S WHERE 優良度 >= 20 ;
WHERE 節で記述できる条件式では、= , <>(not equal) , < , > , <= , >= の比較演算子が使える。
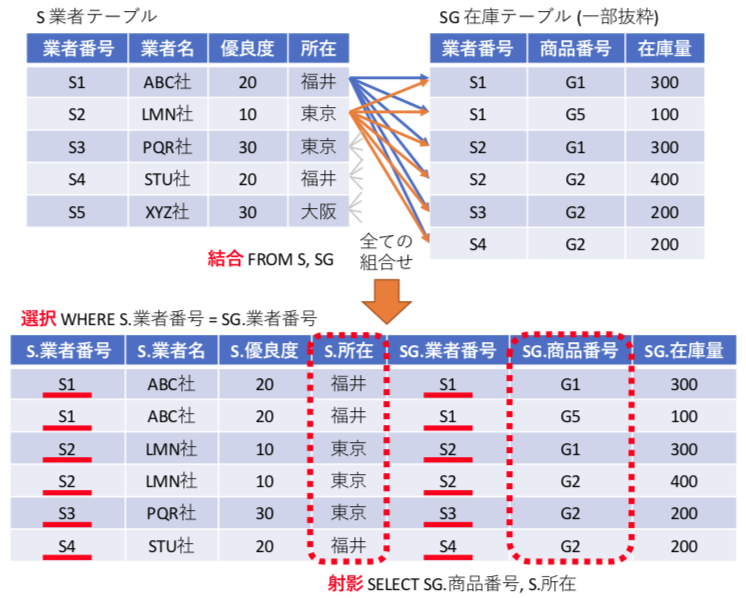
直積と結合処理
ここで、SQLの最も便利な機能は、直積による結合処理。複数の表を組み合わせる処理。単純な表形式の関係データベースで、複雑なデータを表現できる基本機能となっている。
SELECT SG.商品番号 , S.所在 FROM S , SG WHERE SG.業者番号 = S.業者番号
上記の様に FROM 節に複数のテーブルを書くと、それぞれのテーブルの直積(要素の全ての組み合わせ)を生成する処理が行われる。この機能が結合となる。しかし、これだけでは意味がないので、通常は外部キーが一致するレコードでのみ処理を行うように、WHERE SG.業者番号 = S.業者番号 のような選択を記載する。最後に、結果として欲しいデータを抽出する射影を記載する。
// C言語なら
struct Table_S {
char 業者番号[ 6 ] ;
char 業者名[ 22 ] ;
int 優良度 ;
char 所在[ 16 ] ;
} S[] = {
{ "S1" , "ABC社" , 20 , "福井" } ,
:
} ;
struct Table_SG {
char 業者番号[ 6 ] ;
char 商品番号[ 6 ] ;
int 在庫量 ;
} = SG[] {
{ "S1" , "G1" , 300 } ,
:
} ;
// FROM S
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
// FROM SG
for( int j = 0 ; j < sizeofarray( SG ) ; j++ ) {
// WHERE S.業者番号 = SG.業者番号
if ( strcmp( S[i].業者番号 , SG[j].業者番号 ) == 0 ) {
// SELECT SG.商品番号 , S.所在
printf( "%s %s¥n" , SG[j].商品番号 , S[i].所在 ) ;
}
}
}
(1) i,jの2重forループが、FROM節の結合に相当し、(2) ループ内のif文がWHERE節の選択に相当し、(3) printfの表示内容が射影に相当している。
射影の処理では、データの一部分を抽出することから、1件の抽出レコードが同じになることもある。この際の重複したデータを1つにまとめる場合には、DISTINCT を指定する。
SELECT DISTINCT SG.商品番号, S.所在 FROM S, SG WHERE SG.業者番号 = S.業者番号 ;
上記のプログラムでは、データの検索は単純 for ループで記載しているが、内部で HASH などが使われていると、昇順に処理が行われない場合も多い。出力されるデータの順序を指定したい場合には、ORDER BY … ASC (or DESC) を用いる
SELECT SG.商品番号, S.所在 FROM S, SG WHERE SG.業者番号 = S.業者番号 ORDER BY S.所在 ASC ; -- ASC:昇順 , DESC:降順 --
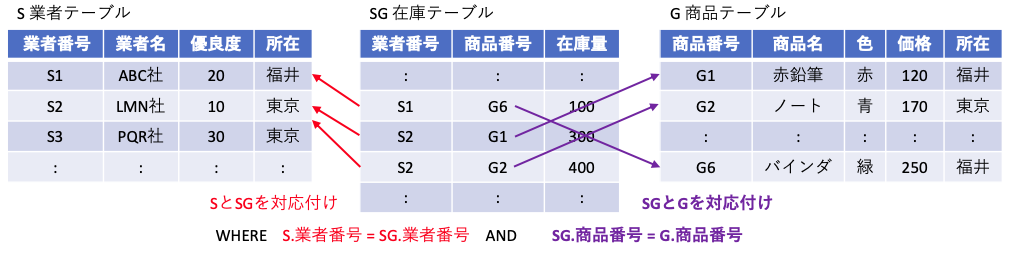
表型のデータと串刺し
FROM に記載する直積のための結合では、2つ以上のテーブルを指定しても良い。
SELECT S.業者名, G.商品名, SG.在庫量
FROM S, G, SG
WHERE S.業者番号 = SG.業者番号 -- 外部キー業者番号の対応付け --
AND SG.商品番号 = G.商品番号 -- 外部キー商品番号の対応付け --
// 上記の処理をC言語で書いたら
struct Table_G {
char 商品番号[ 6 ] ;
char 商品名[ 22 ] ;
char 色[ 4 ] ;
int 価格 ;
char 所在[ 12 ] ;
} = G[] = {
{ "G1" , "赤鉛筆" , "青" , 120 , "福井" } ,
:
} ;
// FROM S (結合)
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
// FROM G (結合)
for( int j = 0 ; j < sizeofarray( G ) ; j++ ) {
// FROM SG (結合)
for( int k = 0 ; k < sizeofarray( SG ) ; k++ ) {
// WHERE S.業者番号 = SG.業者番号
// AND SG.商品番号 = G.商品番号 (選択)
if ( strcmp( S[i].業者番号 , SG[k].業者番号 ) == 0
&& strcmp( SG[k].商品番号 , G[j].商品番号 ) == 0 ) {
// 使用するフィールドを出力 (射影)
printf( "%s %s %d\n" ,
S[i].業者名 , G[j].商品名 , SG[k].在庫量 ) ;
}
}
}
}
 ここで結合と選択で実行している内容は、外部キーである業者番号を S から探す、商品番号を G から探している。この、外部キー対応しているものを探すという視点で、上記 C 言語のプログラムを書き換えると、以下のように表せる。
ここで結合と選択で実行している内容は、外部キーである業者番号を S から探す、商品番号を G から探している。この、外部キー対応しているものを探すという視点で、上記 C 言語のプログラムを書き換えると、以下のように表せる。
// FROM SG
for( int k = 0 ; k < sizeofarray( SG ) ; k++ ) {
// 外部キー SG.業者番号に対応するものを S から探す
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
if ( strcmp( S[i].業者番号 , SG[k].業者番号 ) == 0 ) {
// 外部キー SG.商品番号に対応するものを G から探す
for( int j = 0 ; j < sizeofarray( G ) ; j++ ) {
if ( strcmp(SG[k].商品番号,G[j].商品番号) == 0 ) {
printf( "%s %s %d\n" ,
S[i].業者名,G[j].商品名,SG[k].在庫量 ) ;
}
}
}
}
}
このような、複数の表の実体と関係を対応付けた検索を、データベースの専門の人は「データを串刺しにする」という言い方をすることも多い。
また、SQL では、このようなイメージの繰り返し処理を、数行で分かりやすく記述できている。このプログラム例では、キーに対応するものを単純 for ループで説明しているが、SQL ではプライマリキーなら、B木やハッシュなどを用いた検索が行われるが、SQLの記述するときにはあまり考えなくて良い。
SQLの副問い合せ
前節の結合処理は時として効率が悪い。このような場合は、副問い合わせを用いる場合も多い。
SELECT S.業者名, S.所在
FROM S
WHERE S.業者番号 IN
( SELECT SG.業者番号
FROM SG
WHERE SG.商品番号 = 'G2'
AND SG.在庫量 >= 200 ) ;
まず、『◯ IN { … }』 の比較演算子は、◯が{…}の中に含まれていれば、真となる。また、SQLの中の (…) の中が副問い合わせである。
この SQL では、副問い合わせの内部には、テーブル S に関係する要素が含まれない。この場合、副問い合わせ(商品番号がG2で在庫量が200以上)は先に実行される。
{(S1,G2,200),(S2,G2,400),(S3,G2,200),(S4,G2,200)}が該当し、その業者番号の{S1,S2,S3,S4}が副問い合わせの結果となる。最終的に SELECT … FROM S WHERE S.業者番号 IN {‘S1′,’S2′,’S3′,’S4’} を実行する。
相関副問い合わせ
SELECT G.商品名, G.色, G.価格
FROM G
WHERE 'S4' IN
( SELECT SG.業者番号
FROM SG
WHERE SG.商品番号 = G.商品番号 ) ;
この副問い合わせでは、内部に G.商品番号 が含まれており、単純に()内を先に実行することはできない。こういった副問い合わせは、相関副問い合わせと呼ばれる。
処理は、Gのそれぞれの要素毎に、副問い合わせを実行し、その結果を使って WHERE節の判定を行う。WHERE節の選択で残った結果について、射影で商品名,色,価格が抽出される。
// 概念の説明用に、C言語風とSQL風を混在して記載する
for( int i = 0 ; i < sizeofarray( G ) ; i++ ) {
SELECT SG.業者番号 FROM SG
WHERE SG.商品番号 = G[i].商品番号 を実行
if ( WHERE 'S4' IN 副query の結果が真なら ) {
printf( ... ) ;
}
}
// 全てのG 副queryの結果 WHERE 射影
// G1 -> {S1,S2}
// G2 -> {S1,S2,S3,S4} -> ◯ -> (ノート,青,170)
// G3 -> {S1}
// G4 -> {S1,S4} -> ◯ -> (消しゴム,白,50)
// G5 -> {S1,S4} -> ◯ -> (筆箱,青,300)
// G6 -> {S1}