データ処理において、配列は基本的データ構造だが、動的メモリ確保の説明で述べたように、基本の配列では大きさを変更することができない。これ以外にも、配列は途中にデータを挿入・削除を行う場合、の処理時間を伴う。以下にその問題点を整理し、その解決策であるリスト構造について説明する。
配列の利点と欠点
今までデータの保存には、配列を使ってきたが、配列は添字で場所を指定すれば、その場所のデータを簡単に取り出すことができる。配列には苦手な処理がある。例えば、配列の中から目的のデータを高速に探す方式として、2分探索法を用いる。
int find( int array[] , int left , int right , int key ) {
// データは left から right-1までに入っているとする。
while( left < right ) {
int mid = (left + right) / 2 ; // 中央の場所
if ( array[ mid ] == key )
return mid ; // 見つかった
else if ( array[ mid ] > key )
right = mid ; // 左半分にある
else
left = mid + 1 ; // 右半分にある
}
return -1 ; // 見つからない
}
しかし、配列の中に新たに要素を追加しようとするならば、データは昇順に並んでいる必要があることから、以下のようになるだろう。
void entry( int array[] , int* psize , int key ) {
// データを入れるべき場所を探す処理
for( int i = 0 ; i < *psize ; i++ ) // O(N) の処理だけど、
if ( array[ i ] > key ) // O(log N) でも書けるけど
break ; // 単純に記載する。
if ( i < *psize ) {
// 要素を1つ後ろにずらす処理
for( int j = *psize ; j > i ; j-- ) // O(N)の処理
array[ j ] = array[ j - 1 ] ;
array[ i ] = key ;
} else {
array[ *psize ] = key ;
}
(*psize)++ ;
}
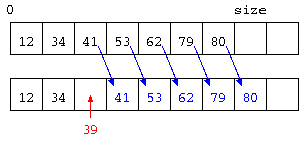
これで判るように、データを配列に追加する場合、途中にデータを入れる際にデータを後ろにずらす処理が発生する。
この例は、データを追加する場合であったが、不要となったデータを取り除く場合にも、データの場所の移動が必要である。
順序が重要なデータ列で途中へのデータ挿入削除
例えば、アパート入居者に回覧板を回すことを考える。この中で、入居者が増えたり・減ったりした場合、どうすれば良いか考える。
通常は、自分の所に回覧板が回ってきたら、次の入居者の部屋番号さえわかっていれば、回覧板を回すことができる。
101 102 103 104 105 106 [ 105 | 106 | -1 | 102 | 104 | 103 ]
このように次のデータの場所という概念を使うと、データの順序を持って扱うことができる。
struct LIST {
int data ;
int next ;
} ;
struct LIST array[] = {
/*0*/ { 11 , 2 } ,
/*1*/ { 67 , 3 } , // 末尾にデータ34を加える
/*2*/ { 23 , 4 } , // { 23 , 5 } ,
/*3*/ { 89 , -1 } , // 末尾データの目印
/*4*/ { 45 , 1 } ,
/*5*/ { 0 , 0 } , // { 34 , 4 } ,
} ;
for( int idx = 0 ; idx >= 0 ; idx = array[ idx ].next ) {
printf( "%d¥n" , array[ idx ].data ) ;
}
この方法を取れば、途中にデータ入れたり、抜いたりする場合に、データの移動を伴わない。
しかし、配列をベースにしているため、配列の上限サイズを超えて格納することはできない。
リスト構造
リスト構造は、データと次のデータへのポインタで構成され、必要に応じてメモリを確保することで、配列の上限が制限にならないようにする。また、次のデータへのポインタでつなげているため、途中へのデータ挿入が簡単にできるようにする。
struct List {
int data ;
struct List* next ;
} ;
struct List* top ;
top = (struct List*)malloc( sizeof( struct List ) ) ;
top->data = 111 ;
top->next = (struct List*)malloc( sizeof( struct List ) ) ;
top->next->data = 222 ;
top->next->next = (struct List*)malloc( sizeof( struct List ) ) ;
top->next->next->data = 333 ;
top->next->next->next = NULL ; // 末尾データの目印
struct List*p ;
for( p = top ; p != NULL ; p = p->next ) {
printf( "%d¥n" , p->data ) ;
}

補助関数
上記のプログラムでは、(struct…)malloc(sizeof(…))を何度も記載し、プログラムが分かりにくいので、以下に示す補助関数を使うと、シンプルに記載できる。
struct List* cons( int x , struct List* n ) {
struct List* ans ;
ans = (struct List*)malloc( sizeof( struct List ) ) ;
if ( ans != NULL ) {
ans->data = x ;
ans->next = n ;
}
return ans ;
}
struct List* top ;
top = cons( 111 , cons( 222 , cons( 333 , NULL ) ) ) ;
授業アンケートで板書の字が読みづらいといわれつつも、パッパッパッってコードを書いていると「その関数名読めない…」とツッコミが。cons : constructor の意味ですがな…と話しつつ、例年どおり「どーでもいいウンチク」を話す。
今日以降説明していくリスト構造は、古くから使われていて、LISP というプログラム言語があり、この言語でリスト(セル)を生成する関数が cons 。
LISPと関数型プログラミング言語
LISPの歴史は長く、最古のFORTRAN,COBOLに次ぐ3番目ぐらい。最初は、人工知能のプログラム開発のための関数型プログラミング言語として作られた。特徴として、データもプログラムもすべてリスト構造(S式)で表すことができ、プログラムは関数型に基づいて作られる。
関数型プログラミングは、Ruby や Python でも取り入れられている。関数型プログラミングは、処理を関数をベースに記述することで「副作用を最小限にすることができ」、極端な話をすればループも再帰呼出しで書けばいい…。
LISPの処理系は、最近では Scheme などが普通だが、プログラムエディタの Emacs は、内部処理が LISP で記述されている。