前回のハッシュ法では、数値(電話番号)をキーとする検索であった。 このためハッシュ関数は、数値の不規則性の部分を取り出すだけでよかった。 それでは、文字をキーとしてデータを探す場合はどのようにすればよいか?
文字列をキーとするハッシュ
文字の場合は、文字コードを用いてハッシュ値を作れば良い。
int hash_func( char* s ) {
int sum = 0 ;
for( int i = 0 ; s[i] != '¥0' ; i++ )
sum += s[i] ;
return sum % HASE_SIZE ;
}
しかし、この方法では、文字の並び順が違うだけ(“ABC”,”CBA”,”BBB”)に対して、 同じハッシュ値となってしまう。 英文字の場合は文字数も限られ、文字コード的には末尾4bitが変化するだけであり、 上位ビットは文字数に左右されることになる。 この場合、同じような文字数であれば、末尾4bitの不規則性も平均化されて、 近いハッシュ値になることが懸念される。
そこで、文字コード的に変化のある部分が、数値的に全体に影響を及ぼし、 最終的な値が広く分布するように以下のような計算とする場合が多い。
// 積算部のみ sum = ( sum * (小さめの素数) + s[i] ) % (大きめの素数) ;
このような考え方は、疑似乱数を生成する方式と近い部分が多い。
共有のあるデータの取扱い問題
struct List* join( struct List* p , struct List* q )
{ struct List* ans = p ;
for( ; q != NULL ; q = q->next )
if ( !find( ans , q->data ) )
ans = cons( q->data , ans ) ;
return ans ;
}
void list_del( struct List* p )
{ // ダメなプログラムの例
while( p != NULL ) { // for( ; p != NULL ; p = p->next )
struct List* d = p ; // free( p ) ;
p = p->next ;
free( d ) ;
}
}
void main() {
// リストの生成
struct List* a = cons( 1 , cons( 2 , cons( 3 , NULL ) ) ) ;
struct List* b = cons( 2 , cons( 3 , cons( 4 , NULL ) ) ) ;
struct List* c = join( a , b ) ; // c = { 4, 1, 2, 3 }
// ~~~~~~~ ここは a
// a,b,cを使った処理
// 処理が終わったのでa,b,cを捨てる
list_del( c ) ;
list_del( b ) ;
list_del( a ) ; // list_del(c)ですでに消えている
} // このためメモリー参照エラー発生
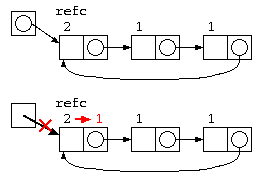
参照カウンタ法
上記の問題の簡単な解決方法は、参照カウンタ法である。
参照カウンタ法は、データを指すポインタ数を一緒に保存し、
- データ生成時は、refc = 1
- 共有が発生する度に、refc++
データを消す場合は、
- refc–
- refc が 0 の時は、本当に消す
struct List {
int refc ; // 参照カウンタ
int data ; // データ
struct List* next ; // 次のポインタ
} ;
void list_del( strcut List* p ) { // 再帰で全廃棄
if ( p->refc <= 0 ) { // 参照カウンタを減らし
list_del( p->next ) ; // 0ならば本当に消す
free( p ) ;
}
}
ただし、参照カウンタ法は、循環リストではカウンタが0にならないので、取扱いが苦手。