コンパイラの処理の流れ
構文の構造を表すために、2分木を使うという話をこの後に行うが、その前にコンパイラが機械語を生成するまでの処理の流れについて説明をする。
Cコンパイラのソース ↓ プリプロセッサ (#define,#includeなどの処理) ↓ コンパイラ ・字句解析(ソースコードをトークンに切り分ける) ・構文解析(トークンから構文木を生成) ・最適化(命令を効率よく動かすために命令を早い命令に書き換え) ・コード生成(構文木から中間コードを生成) | | リンカでライブラリと結合 (+)←---ライブラリ ↓ 機械語
バイトコードインタプリタ
通常、コンパイラとかインタプリタの説明をすると、Java がコンパイラとか、JavaScript はインタプリタといった説明となる。しかし、最近のこういった言語がどのように処理されるのかは、微妙である。
(( Java の場合 )) foo.java (ソースコード) ↓ Java コンパイラ foo.class (中間コード) ↓ JRE(Java Runtime Engine)の上で 中間コードをインタプリタ方式で実行
あらかじめコンパイルされた中間コードを、JREの上でインタプリタ的に実行するものは、バイトコードインタプリタ方式と呼ぶ。
ただし、JRE でのインタプリタ実行では遅いため、最近では JIT コンパイラ(Just-In-Time Compiler)により、中間コードを機械語に変換してから実行する。
また、JavaScriptなどは(というか最近のインタプリタの殆どPython,PHP,Perl,…は)、一般的にはインタプリタに分類されるが、実行開始時に高級言語でかかれたコードから中間コードを生成し、そのバイトコードをインタプリタ的に動かしている。
しかし、インタプリタは、ソースコードがユーザの所に配布されて実行するので、プログラムの内容が見られてしまう。プログラムの考え方が盗まれてしまう。このため、変数名を短くしたり、空白を除去したり(…部分的に暗号化したり)といった難読化を行うのが一般的である。
字句解析と構文解析
トークンと正規表現(字句解析)
字句解析でトークンを表現するために、規定されたパターンの文字列を表現する方法として、正規表現(regular expression)が用いられる。
((正規表現の書き方)) 選言 「abd|acd」は、abd または acd にマッチする。 グループ化 「a(b|c)d」は、真ん中の c|b をグループ化 量化 パターンの後ろに、繰り返し何回を指定 ? 直前パターンが0個か1個 「colou?r」 * 直前パターンが0個以上繰り返す 「go*gle」は、ggle,gogle,google + 直前パターンが1個以上繰り返す 「go+gle」は、gogle,google,gooogle
正規表現は、sed,awk,Perl,PHPといった文字列処理の得意なプログラム言語でも利用できる。こういった言語では、以下のようなパターンを記述できる。
[文字1-文字2...] 文字コード1以上、文字コード2以下 「[0-9]+」012,31415,...数字の列 ^ 行頭にマッチ $ 行末にマッチ ((例)) [a-zA-Z_][a-zA-Z_0-9]* C言語の変数名にマッチする正規表現
構文とバッカス記法
言語の文法(構文)を表現する時、バッカス記法(BNF)が良く使われる。
((バッカス記法)) <表現> ::= <表現1...> | <表現2...> | <表現3...> | ... ;
例えば、加減乗除記号と数字だけの式の場合、以下の様なBNFとなる。
((加減乗除式のバッカス記法))
<加算式> ::= <乗算式> '+' <乗算式> 【要注意】わざと間違っている部分あり
| <乗算式> '-' <乗算式>
| <乗算式>
;
<乗算式> ::= <数字> '*' <乗算式>
| <数字> '/' <乗算式>
| <数字>
;
<数字> ::= [0-9]+
;
上記のバッカス記法には、間違いがある。”1+2+3″を正しく認識できない。どこが間違っているだろうか?
このような構文が与えられた時、”1+23*456″と入力されたものを、“1,+,23,*,456”と区切る処理が、字句解析である。
また、バッカス記法での文法に合わせ、以下のような構文木を生成するのが構文解析である。
+ / \ 1 * / \ 23 456
2項演算と構文木
演算子を含む式が与えられたとして、古いコンパイラではそれを逆ポーランド変換して計算命令を生成していた。しかし最近の複雑な言語では、計算式や命令を処理する場合、その式(または文)の構造を表す2分木(構文木)を生成する。。
+ / \ 1 * / \ 2 3
演算子の木のノードで、末端は数値であることに注目し、右枝・左枝がNULLなら数値(data部にはその数値)、それ以外は演算子(data部には演算子の文字コード)として扱うとして、上記の構文木のデータを作る処理と、その構文木の値を計算するプログラムを示す。
import java.util.*;
class ExpTreeNode {
String op_val ;
ExpTreeNode left ;
ExpTreeNode right ;
ExpTreeNode( String op , ExpTreeNode l , ExpTreeNode r ) {
this.op_val = op ;
this.left = l ;
this.right = r ;
}
ExpTreeNode( String val ) {
this.op_val = val ;
this.left = null ;
this.right = null ;
}
}
public class Main {
public static int eval( ExpTreeNode p ) {
if ( p.left == null && p.right == null ) {
return Integer.parseInt( p.op_val ) ;
} else {
int l_val = eval( p.left) ;
int r_val = eval( p.right ) ;
switch( p.op_val ) {
case "+" : return l_val + r_val ;
case "*" : return l_val * r_val ;
}
return -1 ; // error
}
}
public static void main(String[] args) throws Exception {
ExpTreeNode top =
new ExpTreeNode( "+" ,
new ExpTreeNode( "1" ) ,
new ExpTreeNode( "*" ,
new ExpTreeNode( "2" ) ,
new ExpTreeNode( "3" ) ) ) ;
System.out.println( eval( top ) ) ;
}
}
- 2分木による構文木(Paiza.io)
オブジェクト指向を使った構文木(テスト範囲外)
前述の2分木を用いた構文木では、式を構成する「整数値」の式、「式 演算子 式」の演算式の二つのパターンを、無理やり1つのクラスで扱っていた。整数値と演算子の文字列の違いがあるため、数値も文字列で保存したものを parseInt() で数値に変換している。
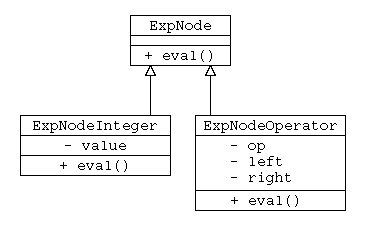
こういった、大きくは式と分類できるけど、数値を表す式、演算子からなる式と異なるデータの場合、Java では、オブジェクト指向プログラミングの抽象クラスと仮想関数のテクニックを用いる。式を表現する基底クラス ExpNode から、数値を表す ExpNodeInteger , 演算子からなる式を表す ExpNodeOperator を派生させ、式の値を求める際には、各クラスに応じた計算処理を行う仮想関数 eval() を使って処理を行っている。
import java.util.* ;
// 抽象基底クラス
abstract class ExpNode {
abstract public int eval() ;
}
// 整数で具体化
class ExpNodeInteger extends ExpNode {
int value ;
ExpNodeInteger( int i ) {
this.value = i ;
}
// 仮想関数
public int eval() {
return this.value ;
}
}
// 演算子で具体化
class ExpNodeOperator extends ExpNode {
String op ;
ExpNode left ;
ExpNode right ;
ExpNodeOperator( String s , ExpNode l , ExpNode r ) {
this.op = s ;
this.left = l ;
this.right = r ;
}
// 仮想関数
public int eval() {
int l_val = this.left.eval() ;
int r_val = this.right.eval() ;
switch( this.op ) {
case "+" : return l_val + r_val ;
case "*" : return l_val * r_val ;
}
return -1 ;
}
}
public class Main {
public static void main(String[] args) throws Exception {
ExpNode top =
new ExpNodeOperator( "+" ,
new ExpNodeInteger( 1 ) ,
new ExpNodeOperator( "*" ,
new ExpNodeInteger( 2 ) ,
new ExpNodeInteger( 3 ) ) ) ;
System.out.println( top.eval() ) ;
}
}