配列やリスト構造のデータの中から、目的となるデータを探す場合、配列であれば2分探索法が用いられる。これにより、配列の中からデータを探す処理は、O(log N)となる。(ただし事前にデータが昇順に並んでいる必要あり)
// 2分探索法
int array[ 8 ] = { 11, 13 , 27, 38, 42, 64, 72 , 81 } ;
int bin_search( int a[] , int key , int L , int R ) {
// Lは、範囲の左端
// Rは、範囲の右端+1 (注意!!)
while( R > L ) {
int m = (L + R) / 2 ;
if ( a[m] == key )
return key ;
else if ( a[m] > key )
R = m ;
else
L = m + 1 ;
}
return -1 ; // 見つからなかった
}
void main() {
printf( "%d¥n" , bin_search( array , 0 , 8 ) ) ;
}
一方、リスト構造ではデータ列の真ん中のデータを取り出すには、先頭からアクセスするしかないのでO(N)の処理時間がかかり、極めて効率が悪い。リスト構造のようにデータの追加が簡単な特徴をもったまま、もっとデータを高速に探すことはできないものか?
2分探索木
ここで、データを探すための効率の良い方法として、2分探索木(2分木)がある。以下の木のデータでは、分離する部分に1つのデータと、左の枝(下図赤)と右の枝(下図青)がある。
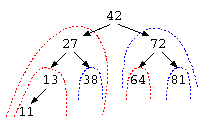
この枝の特徴は何だろうか?この枝では、中央のデータ例えば42の左の枝には、42未満の数字の枝葉が繋がっている。同じように、右の枝には、42より大きな数字の枝葉が繋がっている。この構造であれば、64を探したいなら、42より大きい→右の枝、72より小さい→左の枝、64が見つかった…と、いう風にデータを探すことができる。
特徴としては、1回の比較毎にデータ件数は、(N-1)/2件に減っていく。よって、この方法であれば、O(log N)での検索が可能となる。これを2分探索木とよぶ。
このデータ構造をプログラムで書いてみよう。
struct Tree {
struct Tree* left ;
int data ;
struct Tree* right ;
} ;
// 2分木を作る補助関数
struct Tree* tcons( struct Tree* L ,
int d ,
struct Tree* R ) {
struct Tree* n = (struct Tree*)malloc(
sizeof( struct Tree ) ) ;
if ( n != NULL ) { /* (A) */
n->left = L ;
n->data = d ;
n->right = R ;
}
return n ;
}
// 2分探索木よりデータを探す
int tree_search( struct List* p , int key ) {
while( p != NULL ) {
if ( p->data == key )
return key ;
else if ( p->data > key )
p = p->left ;
else
p = p->right ;
}
return -1 ; // 見つからなかった
}
struct Tree* top = NULL ;
void main() {
// 木構造をtcons()を使って直接生成 (B)
top = tcons( tcons( tcons( NULL , 13 , NULL ) ,
27 ,
tcons( NULL , 38 , NULL ) ) ,
42 ,
tcons( tcons( NULL , 64 , NULL ) ,
72 ,
tcons( NULL , 81 , NULL ) ) ) ;
printf( "%d¥n" , tree_search( top , 64 ) ) ;
}
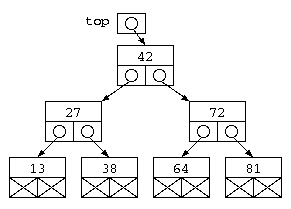
この方式の注目すべき点は、struct Tree {…} で宣言しているデータ構造は、2つのポインタと1つのデータを持つという点では、双方向リストとまるっきり同じである。データ構造の特徴の使い方が違うだけである。
理解度確認
- 上記プログラム中の、補助関数tcons() の(A)の部分 “if ( n != NULL )…” の判定が必要な理由を答えよ。
- 同じくmain() の (B) の部分 “top = tcons(…)” において、末端部に NULL を入れる理由を答えよ。
2分木に対する処理
2分探索木に対する簡単な処理を記述してみよう。
// データを探す
int search( struct Tree* p , int key ) {
// 見つかったらその値、見つからないと-1
while( p != NULL ) {
if ( p->data == key )
return key ;
else if ( p->data > key )
p = p->left ;
else
p = p->right ;
}
return -1 ;
}
// データを全表示
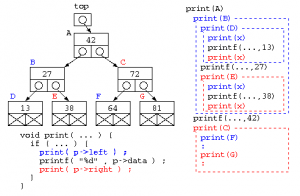
void print( struct Tree* p ) {
if ( p != NULL ) {
print( p->left ) ;
printf( "%d¥n" , p->data ) ;
print( p->right ) ;
}
}
// データ件数を求める
int count( struct Tree* p ) {
if ( p == NULL )
return 0 ;
else
return 1
+ count( p->left )
+ count( p->right ) ;
}
// データの合計を求める
int sum( struct Tree* p ) {
if ( p == NULL )
return 0 ;
else
return p->data
+ count( p->left )
+ count( p->right ) ;
}
// データの最大値
int max( struct Tree* p ) {
while( p->right != NULL )
p = p->right ;
return p->data ;
}
これらの関数では、木構造の全てに対する処理を実行する場合には、再帰呼び出しが必要となる。
2分探索木にデータを追加
前回の授業では、データの木構造は、補助関数 tcons() により直接記述していた。実際のプログラムであれば、データに応じて1件づつ木に追加するプログラムが必要となる。この処理は以下のようになるだろう。
struct Tree* top = NULL ;
// 2分探索木にデータを追加する処理
void entry( int d ) {
struct Tree** tail = &top ;
while( *tail != NULL ) {
if ( (*tail)->data == d ) // 同じデータが見つかった
break ;
else if ( (*tail)->data > d )
tail = &( (*tail)->left ) ; // 左の枝に進む
else
tail = &( (*tail)->right ) ; // 右の枝に進む
}
if ( (*tail) == NULL )
*tail = tcons( d , NULL , NULL ) ;
}
int main() {
char buff[ 100 ] ;
int x ;
while( fgets( buff , sizeof( buff ) , stdin ) != NULL )
if ( sscanf( buff , "%d" , &x ) != 1 )
break ;
entry( x ) ;
return 0 ;
}
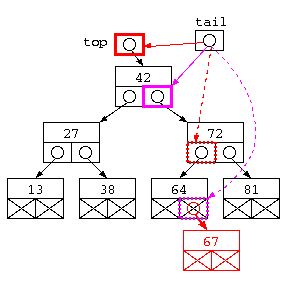
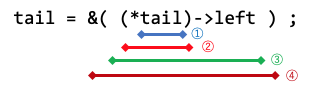
このプログラムでは、struct Tree** tail というポインタへのポインタ型を用いている。tail が指し示す部分をイメージするための図を以下に示す。
理解確認
- 関数entry() の14行目の if 判定を行う理由を説明せよ。
- 同じく、8行目の tail = &( (*tail)->left ) の式の各部分の型について説明せよ。
- sscanf() の返り値を 1 と比較している理由を説明せよ。
- entry() でデータを格納する処理時間のオーダを説明せよ。
ポインタのポインタを使わない挿入
struct Tree* insert( struct Tree* p , int x ) {
if ( p == NULL )
p = tcons( NULL , x , NULL ) ;
else if ( p->data == x )
;
else if ( p->data > x )
p->left = insert( p->left , x ) ;
else
p->right = insert( p->right , x ) ;
return p ;
}
int main() {
struct Tree* top = NULL ;
int x ;
while( scanf( "%d" , &x ) == 1 ) {
top = insert( top , x ) ;
}
print( top ) ;
return 0 ;
}