フィルタプログラム
パイプを使うと、標準入力からデータをもらい・標準出力に結果を出力するような簡単なプログラムを組み合わせて、様々な処理が簡単にできる。こういったプログラムは、フィルタと呼ぶ。
簡単な例として、入力をすべて大文字に変換するプログラム(toupper)、入力文字をすべて小文字に変換するプログラム(tolower)が、下記の例のように保存してあるので動作を確かめよ。
guest00@nitfcei:~$ cp /home0/Challenge/2.1-RedirectPipe.d/toupper.c .
guest00@nitfcei:~$ gcc -o toupper toupper.c .
guest00@nitfcei:~$ cat toupper.c | ./toupper
#INCLUDE <STDIO.H>
#INCLUDE <CTYPE.H>
INT MAIN() {
INT C ;
WHILE( (C = GETCHAR()) != EOF )
PUTCHAR( TOUPPER( C ) ) ;
RETURN 0 ;
}
guest00@nitfcei:~$ cp /home0/Challenge/2.1-RedirectPipe.d/tolower.c .
guest00@nitfcei:~$ gcc -o tolower tolower.c
guest00@nitfcei:~$ cat tolower.c | ./tolower
(((何が出力されるか答えよ)))
よく使われるフィルタのまとめ
| 文字パターンを含む行だけ出力 | grep 文字パターン |
| 文字パターンを含まない行を出力 文字パターンを正規表現でマッチングし該当行を出力 大文字小文字を区別しない |
grep -v 文字パターン grep -e 正規表現 grep -i 文字パターン |
| 入力文字数・単語数・行数をカウント(word counter) | wc |
| 入力行数をカウント | wc -l |
| データを昇順に並べる | sort |
| データを降順に並べる 先頭を数字と見なしてソート |
sort -r sort -g |
| 同じ行データが連続したら1つにまとめる | uniq |
| 同じ行が連続したら1つにまとめ、連続した数を出力 | uniq -c |
| 空白区切りで指定した場所(1番目)を抽出 | awk ‘{print$1;}’ |
| 入力の先頭複数行を表示(10行) | head |
| 入力の末尾複数行を表示(10行) | tail |
| 指定した行数だけ、先頭/末尾を表示 | head -行数 tail -行数 |
LOG解析
Linux は利用者に様々なサービスを提供するサーバで広く利用されている。しかし、幅広いサービス提供となると、中にはウィルス拡散や個人情報収集のための悪意のあるアクセスも増えてくる。
このためサーバでは、アクセスを受けた時の状況を記録し保存する。このような情報はアクセス履歴、ログと呼ぶ。
ログの中には、以下のような情報が混在することになるが、大量の 1. や 2. 目的のアクセスの中に、3. や 4. といったアクセスが混ざることになるが、これを見逃すとシステムに不正侵入を受ける可能性もある。
- 本来の利用者からのアクセス
- 検索システムの情報収集(クローラーからのアクセス)
- 不正な情報収集のためのアクセス
- システムの不備を探して不正侵入などを試みるアクセス
今回の演習では、電子情報の web サーバのとある1日のアクセス履歴ファイルを用い、パイプ機能を使い様々なフィルタを使い LOG解析の練習を行う。
アクセス履歴の解析
Webサーバのアクセス履歴が、/home0/Challenge/2.2-LOG.d/access.log に置いてある。このファイルで簡単な確認をしてみよう。
(( ファイルの場所に移動 )) $ cd /home0/Challenge/2.2-LOG.d/ (( .asp という文字を含む行を表示 )) $ grep .asp access.log
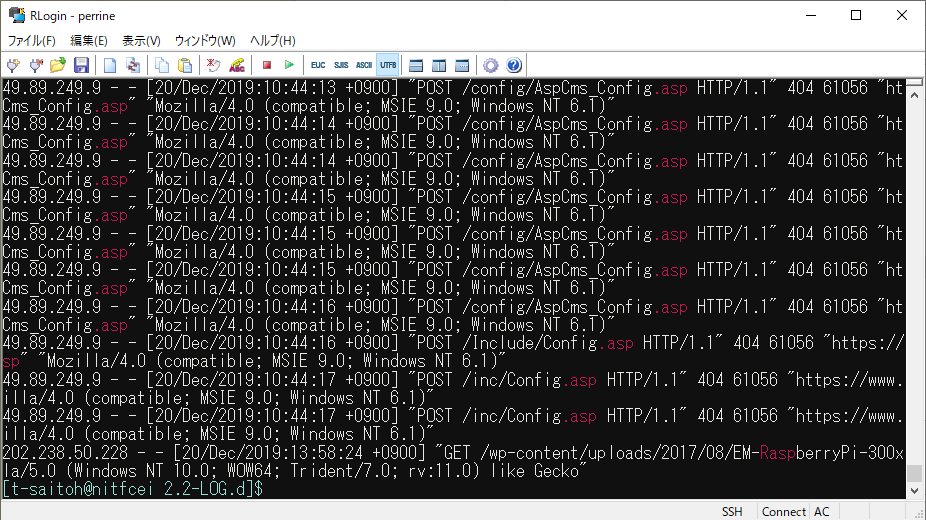
電子情報のWebサーバには、.asp (WindowsのWebサーバで動かすプログラムの拡張子) など存在しない。明らかに設定不備を探すための攻撃である。
これを見ると、grep で .asp を含む行が抜粋され、.asp の部分が強調されていることで、攻撃を簡単に確認できる。しかしこれは画面行数で10件程度が確認できるが、本当は何回攻撃を受けたのだろうか?この場合は、行数をカウントする”wc -l” を使えばいい。
(( アクセス回数を数える )) $ grep .asp access.log | wc -l 37
access.log の各項目の意味
電子情報のWebサーバの access.log に記録されている各項目の意味は以下の通り。
| 項目 | log項目 | 内容 |
|---|---|---|
| 1 | %h | リモートホスト。WebサーバにアクセスしてきたクライアントのIPアドレス |
| 2 | %l | リモートログ名。説明略。通常は “-“ |
| 3 | %u | ログインして操作するページでのユーザ名。通常は “-“ |
| 4 | %t | アクセスを受けた時刻 |
| 5 | %r | 読み込むページ。アクセス方法(GET/POSTなど)と、アクセスした場所。 |
| 6 | %>s | ステータスコード。(200成功,403閲覧禁止,404Not Found) |
| 7 | %b | 通信したデータのバイト数。 |
| 8 | %{Referer}i | Referer どのページからアクセスが発生したのか |
| 9 | %{User-Agent}i | User-Agent ブラウザ種別(どういったブラウザからアクセスされたのか) |
以下に、フィルタプログラムを活用して、色々な情報を探す例を示す。実際にコマンドを打って何が表示されるか確認しながら、フィルタプログラムの意味を調べながら、何をしているか考えよう。
.asp を使った攻撃を探す
(( .asp を試す最初の履歴を探す )) $ grep "\.asp" access.log | head -1 49.89.249.9 - - [20/Dec/2019:09:19:06 +0900] "POST /Include/md5.asp HTTP/1.1" 404 64344 "https://www.ei.fukui-nct.ac.jp/Include/md5.asp" "Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)" (( 49.89.249.9 がどんなアクセスを試みているのか探す )) $ grep ^49.89.249.9 access.log | head 49.89.249.9 - - [20/Dec/2019:09:19:06 +0900] "POST /Include/md5.asp HTTP/1.1" 404 64344 "https://www.ei.fukui-nct.ac.jp/Include/md5.asp" "Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)" 49.89.249.9 - - [20/Dec/2019:09:19:06 +0900] "POST /inc/md5.asp HTTP/1.1" 404 61056 "https://www.ei.fukui-nct.ac.jp/inc/md5.asp" "Mozilla/4.0 (compatible; MSIE 9.0; Windows NT 6.1)"
- ステータスコードが404は”Not Found”なので、読み出しに失敗している。
- IPアドレス検索で、49.89.249.9 がどこのコンピュータか調べよう。
攻撃の時間を確認
(( 49.89.249.9 がどんな時間にアクセスを試みているのか探す ))
$ grep ^49.89.249.9 access.log | awk '{print $4;}'
[20/Dec/2019:09:19:06
[20/Dec/2019:09:19:06
[20/Dec/2019:09:19:07
:
- 不正アクセスを試みている時間を調べると、そのアクセス元の09:00~17:00に攻撃していることがわかる場合がある。どういうこと?
ページの閲覧頻度を確認
(( /~t-saitoh/ 見たIPアドレスと頻度 ))
$ grep "/~t-saitoh/" access.log | awk '{print $1;}' | sort | uniq -c | sort -g -r | head
38 151.80.39.78
35 151.80.39.209
32 203.104.143.206
31 5.196.87.138
:
- grep – “/~t-saitoh/”のページをアクセスしているデータを抽出
- awk – 項目の先頭(IPアドレス)だけ抽出
- sort – IPアドレス順に並べる(同じIPアドレスならその数だけ重複した行になる)
- uniq – 重複している行数を数える
- sort -g -r – 先頭の重複数で大きい順にソート
- head – 先頭10行だけ抽出
(( /~t-saitoh/ 見たIPアドレスと頻度 )) (( t-saitoh のテスト問題のページを誰が見ているのか? )) $ grep "/~t-saitoh/exam/" access.log 5.196.87.156 - - [20/Dec/2019:06:36:02 +0900] "GET /~t-saitoh/exam/db2009/ex2009-5-1.pdf HTTP/1.1" 200 20152 "-" "Mozilla/5.0 (compatible; AhrefsBot/6.1; +http://ahrefs.com/robot/)" : (( クローラーのアクセスが多くてよくわからないので bot を含まない行を抽出 )) $ grep "/~t-saitoh/exam/" access.log | grep -v -i bot | lv 213.242.6.61 - - [20/Dec/2019:06:33:12 +0900] "GET /%7Et-saitoh/exam/ HTTP/1.0" 200 19117 "http://www.ei.fukui-nct.ac.jp/%7Et-saitoh/exam/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36 OPR/54.0.2952.64 (Edition Yx)" 188.163.109.153 - - [20/Dec/2019:06:43:04 +0900] "GET /%7Et-saitoh/exam/ HTTP/1.0" 200 19117 "http://www.ei.fukui-nct.ac.jp/%7Et-saitoh/exam/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36 OPR/53.0.2907.99" 188.163.109.153 - - [20/Dec/2019:06:43:05 +0900] "POST /cgi-bin/movabletype/mt-comments.cgi HTTP/1.0" 404 432 "http://www.ei.fukui-nct.ac.jp/%7Et-saitoh/exam/" "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36 OPR/53.0.2907.99" 45.32.193.50 - - [20/Dec/2019:07:06:15 +0900] "GET /~t-saitoh/exam/apply-prog.html HTTP/1.0" 200 5317 "http://www.ei.fukui-nct.ac.jp/" "Mozilla/5.0 (Windows NT 5.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36"
- この結果を見ると mt-comments.cgi というアクセスが見つかる。どうも コメントスパム(ブログのコメント欄に広告を勝手に書き込む迷惑行為)をしようとしている。
ネットワーク攻撃への対処
今回の access.log のアクセス履歴解析は、Webサーバへのアクセスへの基本的な対処となる。しかし、もっと違うネットワーク接続ではどのような対処を行うべきであろうか?
一般的には、
- サーバにネットワークアクセスの記録ソフトを使う(例ネットワークプロトコルアナライザーWireShark)
- ファイアウォールのアクセス履歴を解析
授業内レポート
- ここまでのLOG解析の例の1つについて、どういう考え方でフィルタを使っているのか、自分の言葉で説明せよ。
- LOG 解析のためのコマンドを考え、その実行結果を示し、それから何が判るか説明せよ。
(例) コメントスパムを何度も試す危ないアクセス元は〇〇である。
ジョブ管理
プログラムを実行している時、それがすごくメモリも使い計算時間もかかる処理の場合、条件を変化させながら結果が欲しい時、どのように実行すべきだろうか?1つの処理が1時間かかるとして、画面を見ながら1時間後に処理が終わったことを確認してプログラムを実行するのか?
簡単な方法としては、1つ目の処理(仮にプログラムAとする)を実行させたままで、新しくウィンドウを開いてそこで新しい条件でプログラムを並行処理すればいい(プログラムBとする)と考えるかもしれない。しかし、メモリを大量に使用する処理をいくつも並行処理させると、仮想メモリが使われるようになる。結果的にスワッピングが発生する分、プログラムAを実行させた後にプログラムBを実行するための時間以上に、時間がかかることになる。
ここで、プログラムを並行処理させるか、逐次処理させるといった、JOB(ジョブ)管理について説明を行う。
以下の説明で、複雑で時間のかかる処理を実行するとサーバの負担が高くなるので指定時間の処理待ちを行うための sleep 命令を使う。
逐次実行と並行実行
プログラムを連続して実行(処理Aの後に処理Bを実行する)場合には、セミコロン”;” で区切って A ; B のように処理を起動する。
guest00@nitfcei:~$ echo A A guest00@nitfcei:~$ echo A ; echo B A B
プログラムを並行して実行(処理Aと処理Bを並行処理)する場合には、アンド”&”で区切って A & B のように処理を起動する。
guest00@nitfcei:~$ sleep 5 & [1] 55 guest00@nitfcei:~$ echo A A [1]+ 終了 sleep 5 guest00@nitfcei:~$ sleep 2 & sleep 3 [1] 56 [1]+ 終了 sleep 2 guest00@nitfcei:~$ time ( sleep 1 ; sleep 1 ) # time コマンドは、コマンドの実行時間を測ってくれる。 real 0m2.007s user 0m0.005s sys 0m0.002s guest00@nitfcei:~$ time ( sleep 1 & sleep 1 ) real 0m1.002s user 0m0.003s sys 0m0.000s
fg, bg, jobs コマンド
プログラムを実行中に、処理(ジョブ)を一時停止したり、一時停止している処理を復帰させたりするときには、fg, bg, jobs コマンドを使う。
- 処理をしている時に、Ctrl-C を入力すると前面処理のプログラムは強制停止となる。
- 処理をしている時に、Ctrl-Z を入力すると前面処理のプログラムは一時停止状態になる。
- fg (フォアグラウンド) は、指定した処理を前面処理(キー入力を受け付ける処理)に変更する。
- bg (バックグラウンド) は、指定した処理を後面処理(キー入力が必要になったら待たされる処理)に変更する。
- jobs (ジョブ一覧) は、実行中や一時停止している処理(ジョブ)の一覧を表示する。
guest00@nitfcei:~$ sleep 10 # 途中で Ctrl-Z を入力する ^Z [1]+ 停止 sleep 10 guest00@nitfcei:~$ fg sleep 10 # 一時停止していた sleep 10 を実行再開 guest00@nitfcei:~$ sleep 3 ^Z [1]+ 停止 sleep 3 guest00@nitfcei:~$ sleep 4 ^Z [2]+ 停止 sleep 4 guest00@nitfcei:~$ jobs [1]- 停止 sleep 3 # [1],[2]というのはjob番号 [2]+ 停止 sleep 4 guest00@nitfcei:~$ fg %1 # ジョブ番号1 を前面処理にする sleep 3 guest00@nitfcei:~$ fg %2 # ジョブ番号2 を前面処理にする sleep 4
ps, kill コマンド
OS では、プログラムの処理単位は プロセス(process) と呼ぶ。OS はプロセスごとにメモリの実行範囲などの管理を行う。一連のプロセスを組み合わせて実行する単位を ジョブ(job) と呼ぶ。
複数のプロセスは間違ったメモリアクセスで他のプロセスが誤動作するようでは、安心して処理が実行できない。そこで、OS は、プロセスが他のプロセスのメモリをアクセスすると強制停止させるなどの保護をしてくれる。しかし、プロセスと他のプロセスが協調して処理を行うための情報交換のためにメモリを使うことは困難である。プロセス間で情報交換が必要であれば、パイプ機能やプロセス間共有メモリ機能を使う必要がある。
最近のOSでは、共通のメモリ空間で動き 並行動作する個々の処理は スレッド(thread) と呼び、その複数のスレッドをまとめたものがプロセスとなる。OS では、プロセスごとに番号が割り振られ、その番号を プロセスID(PID) と呼ぶ。実行中のプロセスを表示するには、ps コマンドを使う。
実行中のプロセスを停止する場合には、kill コマンドを用いる。停止するプログラムは、ジョブ番号(%1など) か プロセスID を指定する。
guest00@nitfcei:~$ sleep 3 ^Z [1]+ 停止 sleep 3 guest00@nitfcei:~$ sleep 4 ^Z [2]+ 停止 sleep 4 guest00@nitfcei:~$ jobs [1]- 停止 sleep 3 # [1],[2]というのはjob番号 [2]+ 停止 sleep 4 guest00@nitfcei:~$ ps w # プロセスの一覧(wを付けるとコマンドの引数も確認できる) PID TTY STAT TIME CMD 13 pts/0 Ss 00:00:00 -bash 84 pts/0 T 00:00:00 sleep 3 85 pts/0 T 00:00:00 sleep 4 86 pts/0 R 00:00:00 ps w guest00@nitfcei:~$ kill %1 [1]- Terminated sleep 3 guest00@nitfcei:~$ kill -KILL 85 [2]+ 強制終了 sleep 4 guest00@nitfcei:~$ ps ax # 他人を含めた全プロセスの一覧表示 PID TTY STAT TIME COMMAND 1 ? Ss 0:52 /sbin/init 2 ? S 0:00 [kthreadd] 3 ? I< 0:00 [rcu_gp] :