データベースでは、キーなどの値を高速に探し出すために、単純なデータが並んだだけのテーブルとは別に、検索専用のデータ構造を別に持たせることが多い。これらの検索用のデータは、インデックスファイルと呼ばれる。また、データベースのテーブルのデータも、高速に検索する機能とすべてのデータを順次取り扱うための機能が求められる。これらの機能を実現するための仕組みを以下に説明する。
B木
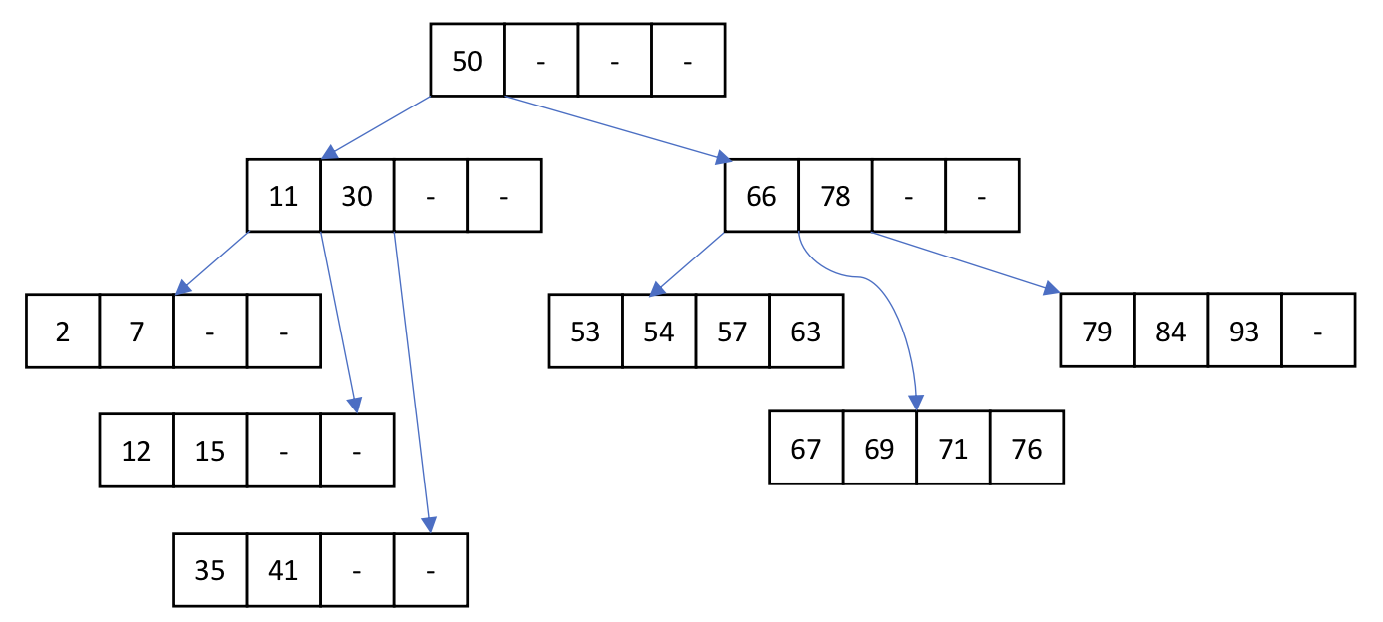
データベースのデータを扱う場合には、B木を用いることが多い。(4年の情報構造論で説明済み)
複数のデータを格納するノードは、位数Nであれば、2✕N個のデータと、その間のデータを持つノードへの2N+1個のポインタで構成される。
{kind=link}
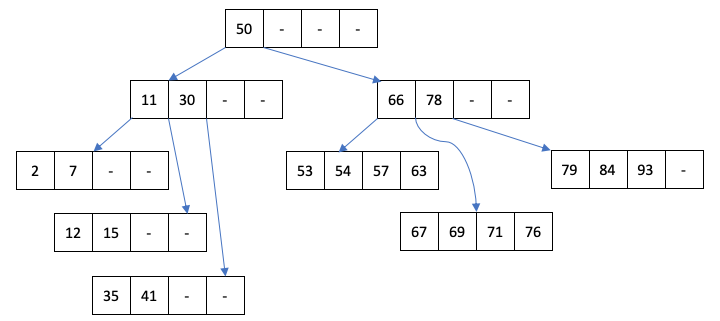
ノードにデータを加える場合(あるいは削除する場合)は、頻繁にノードのポインタの付け替えが発生しないように、データがN個を下回った時や、2N個を超える場合に以下のような処理を行う。ノード内のデータ数が2Nを超える場合は、均等に木構造が成長するように、中央値を上のノードに移動し、ノードを2分割する。
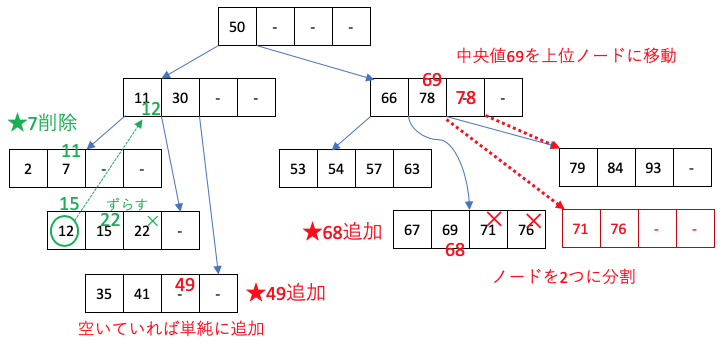
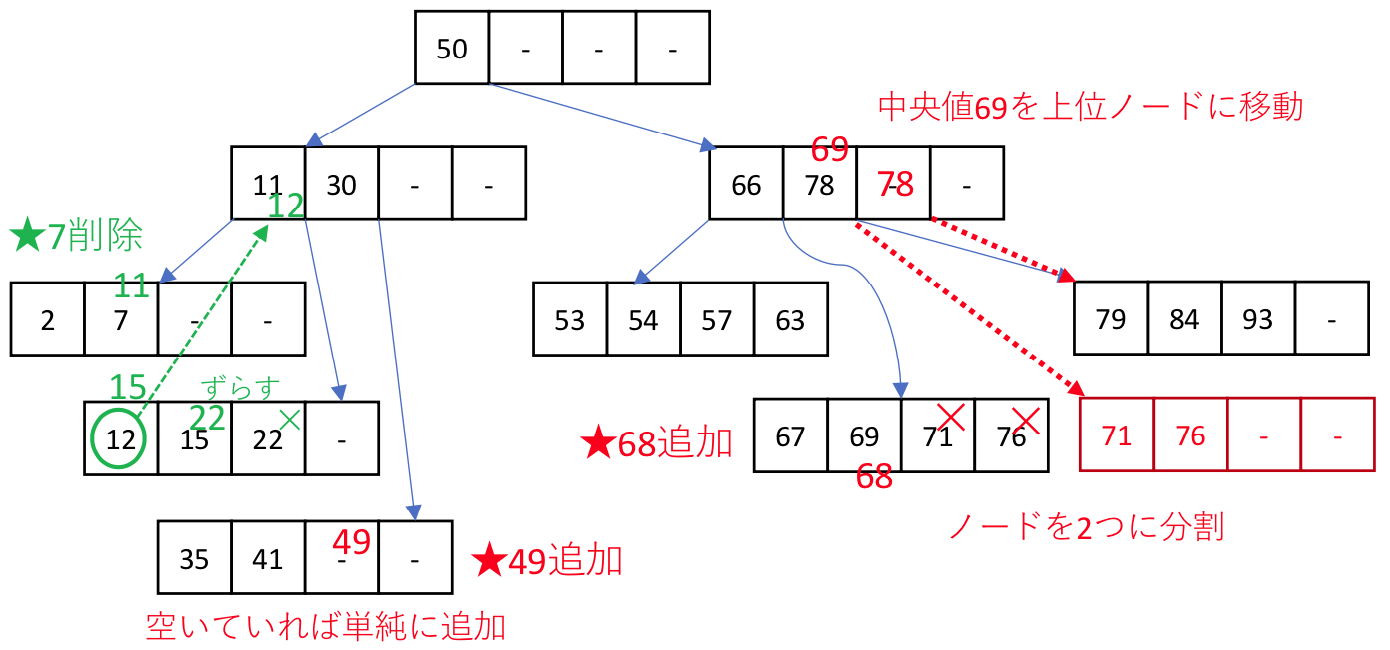 データを削除することでN個を下回る場合は、隣接するノードからデータを移動する。(上図の緑部分のように上位ノードの値を交えながら移動する)
データを削除することでN個を下回る場合は、隣接するノードからデータを移動する。(上図の緑部分のように上位ノードの値を交えながら移動する)
{kind=link}
このような処理を行うことで、極力不均一に成長した木構造が発生しないようにB木は管理されている。
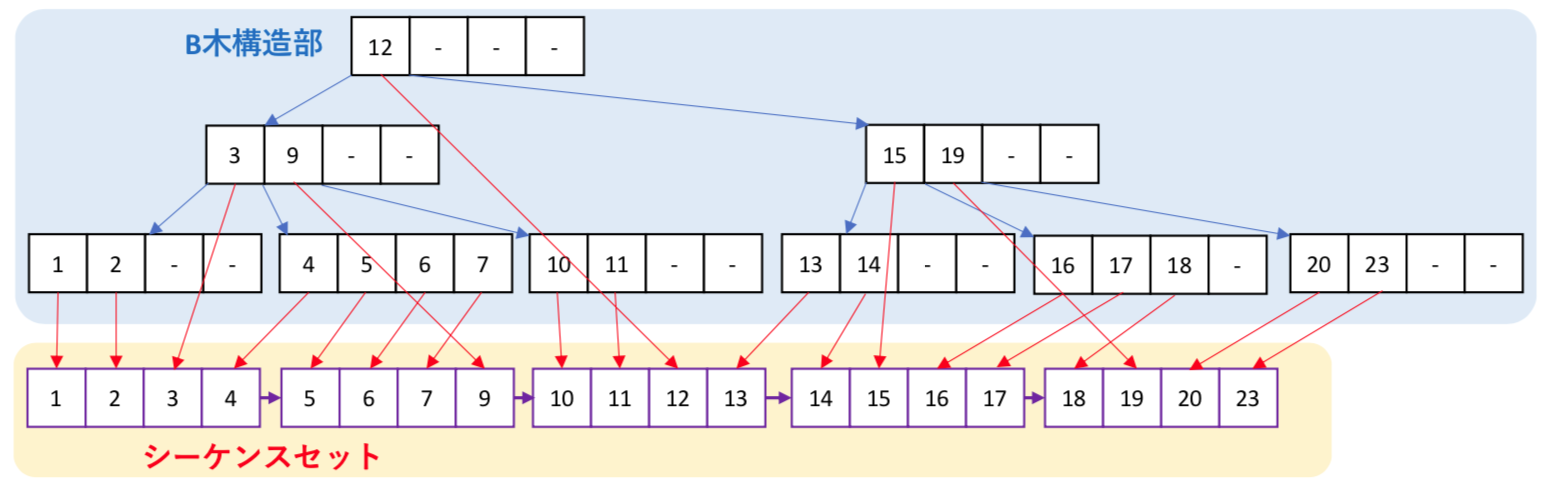
B+木とシーケンスセット
再帰的な木構造のB木では、特定のデータを探す場合には、O(log N)で検索が可能である。
しかしながら、直積のようなすべてのデータを対象とする処理を行う場合、単純なB木では再帰呼出しをしながらの処理を必要とすることから、複雑な処理が発生する。そこで、データ列を横方向にアクセスするための単純リストであるシーケンスセットをB木と並行して管理するデータ構造がB+木である。
データを検索する場合は、B木構造部を用い、全データ処理は、シーケンスセットを用いる。
ハッシュ法
ハッシュ表は、データの一部をとりだしてハッシュ値を求め、そのハッシュ値を番地とする場所にデータを保存する方法である。しかし、データの一部を取り出すため、異なるデータに対して同じハッシュ値となる場合がある。これをハッシュ衝突とよぶ。この際のデータの保存の方法から、2つの方式がある。
- オープンアドレス法
ハッシュ表がすでに埋まっていたら、別の保存場所を探す方式。 - チェイン法
同じハッシュ値となるデータをリスト構造で保存する方法。