先週の、関係データベースの導入説明を終えて、実際のSQLの説明。
SQLの命令
SQL で使われる命令は、以下のものに分類される。((参考資料))
- データ定義言語 – CREATE, DROP, ALTER 等
- データ操作言語 – INSERT, UPDATE, DELETE, SELECT 等
- データ制御言語 – GRANT, REVOKE 等 (その他トランザクション制御命令など)
create user
データベースを扱う際の create user 文は、DDL(Data Definition Language)で行う。
CREATE USER ユーザ名
IDENTIFIED BY "パスワード"
grant
テーブルに対する権限を与える命令。
GRANT システム権限 TO ユーザ名 データベースシステム全体に関わる権限をユーザに与える。 (例) GRANT execute ON admin.my_package TO saitoh GRANT オブジェクト権限 ON オブジェクト名 TO ユーザ名 作られたテーブルなどのオブジェクトに関する権限を与える。 (例) GRANT select,update,delete,insert ON admin.my_table TO saitoh REVOKE オブジェクト権限 ON オブジェクト名 TO ユーザ名 オブジェクトへの権限を剥奪する。
ただし、後に示す実験環境では、データベースのシステムにSQLiteを用いている。SQLite はネットワーク対応型のデータベースではないため、データベースをアクセスするユーザや権限の概念が存在しない。
create table
実際にテーブルを宣言する命令。構造体の宣言みたいなものと捉えると分かりやすい。
CREATE TABLE テーブル名 ( 要素名1 型 , 要素名2 型 ... ) ; PRIMARY KEY 制約 1つの属性でのキーの場合、型の後ろに"PRIMARY KEY"をつける、 複数属性でキーとなる場合は、要素列の最後に PRIMARY KEY(要素名,...) をつける。 これによりKEYに指定した物は、重複した値を格納できない。 型には、以下の様なものがある。(Oracle) CHAR( size) : 固定長文字列 / NCHAR国際文字 VARCHAR2( size ) : 可変長文字列 / NVARCHAR2... NUMBER(桁) :指定 桁数を扱える数 BINARY_FLOAT / BINARY_DOUBLE : 浮動小数点(float / double) DATE : 日付(年月日時分秒) SQLiteでの型 INTEGER : int型 REAL : float/double型 TEXT : 可変長文字列型 BLOB : 大きいバイナリデータ DROP TABLE テーブル名 テーブルを削除する命令
insert,update,delete
指定したテーブルに新しいデータを登録,更新,削除する命令
INSERT INTO テーブル名 ( 要素名,... ) VALUES ( 値,... ) ; 要素に対応する値をそれぞれ代入する。 UPDATE テーブル名 SET 要素名=値 WHERE 条件 指定した条件の列の値を更新する。 DELETE FROM テーブル名 WHERE 条件 指定した条件の列を削除する。
select
データ問い合わせは、select文を用いる、 select文は、(1)必要なカラムを指定する射影、(2)指定条件にあうレコードを指定する選択、 (3)複数のテーブルの直積を処理する結合から構成される。
SELECT 射影 FROM 結合 WHERE 選択 (例) SELECT S.業者番号 FROM S WHERE S.優良度 > 30 ;
理解確認
- キー・プライマリキー・外部キーについて説明せよ。
- 上記説明中の、科目テーブルにふさわしい create table 文を示せ。
- select文における、射影,結合,選択について説明せよ。
SQLの演習環境の使い方
SQL の演習は、Paiza.IO もしくは 下記の 学内向け SQL 演習環境で動作確認をしてください。
下記URLにアクセスすると、認証画面が表示されるので、情報処理センターのユーザIDとパスワードで、Login する。
以下のような画面が表示されるので、最初に”データベースリセット”を押すこと。
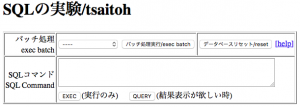
以降、登録済みの処理を実行する場合は、左上のプルダウンメニューから、処理を選んで”バッチ処理実行”を行う。
画面下に、実行された結果が表示される。
教科書内の基本演習のデータを利用したい場合は、”0_Create_DB” , “1_Insert_Data”を実行する。
自分で処理を実行したい場合には、中段のSQLコマンドの欄に、命令を記載する。”create table”や”insert”といった結果を伴わない命令の場合は、”EXEC”を実行。”select” などの実行結果がある場合は、”QUERY”を実行すること。
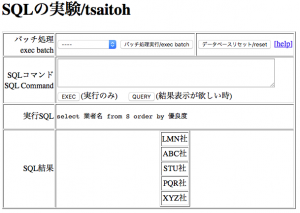
SQLの基礎
ここまで述べたようにデータベースでは記録されているデータの読み書きは、SQL で行われ、射影・結合・選択を表す処理で構成されることを示した。SQL の機能を理解するために、同じ処理を C 言語で書いたらどうなるのかを示す。
((( 元のSQL )))
SELECT S.業者番号 -- 必要とされるデータを抽出する射影 --
FROM S -- 複数のテーブルを組合せる結合 --
WHERE S.優良度 >= 20 ; -- 対象となるデータを選び出す選択 --
((( SQLをC言語で書いたら )))
// 配列の個数を求める #define 文
#define sizeofarray(ARY) (sizeof(ARY) / sizeof(ARY[0]))
// C言語なら... S のデータを構造体宣言で書いてみる。
struct Table_S {
char 業者番号[ 6 ] ; // 当然、C言語では要素名を
char 業者名[ 22 ] ; // 漢字で宣言はできない。
int 優良度 ;
char 所在[ 16 ] ;
} S[] = {
{ "S1" , "ABC社" , 20 , "福井" } ,
:
} ;
// SELECT...をC言語で書いた場合の命令のイメージ
// 結合
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
// 選択
if ( S[i].優良度 >= 20 )
// 射影
printf( "%d¥n" , S[i].業者番号 ) ;
}
Sは、テーブル名であり、文脈上対象テーブルが明らかな場合、フィールド名の前の テーブルは省略可能である。
SELECT 業者番号 FROM S WHERE 優良度 >= 20 ;
WHERE 節で記述できる条件式では、= , <>(not equal) , < , > , <= , >= の比較演算子が使える。
# これ以外の演算機能は、次週にて紹介予定。
直積と結合処理
ここで、SQLの最も便利な機能は、直積による結合処理。複数の表を組み合わせる処理。単純な表形式の関係データベースで、複雑なデータを表現できる基本機能となっている。
SELECT SG.商品番号 , S.所在 FROM S , SG WHERE SG.業者番号 = S.業者番号
- 実験環境で直積と結合処理(学内のみ)
- sample.cxx
上記の様に FROM 節に複数のテーブルを書くと、それぞれのテーブルの直積(要素の全ての組み合わせ)を生成する処理が行われる。この機能が結合となる。しかし、これだけでは意味がないので、通常は外部キーが一致するレコードでのみ処理を行うように、WHERE SG.業者番号 = S.業者番号 のような選択を記載する。最後に、結果として欲しいデータを抽出する射影を記載する。
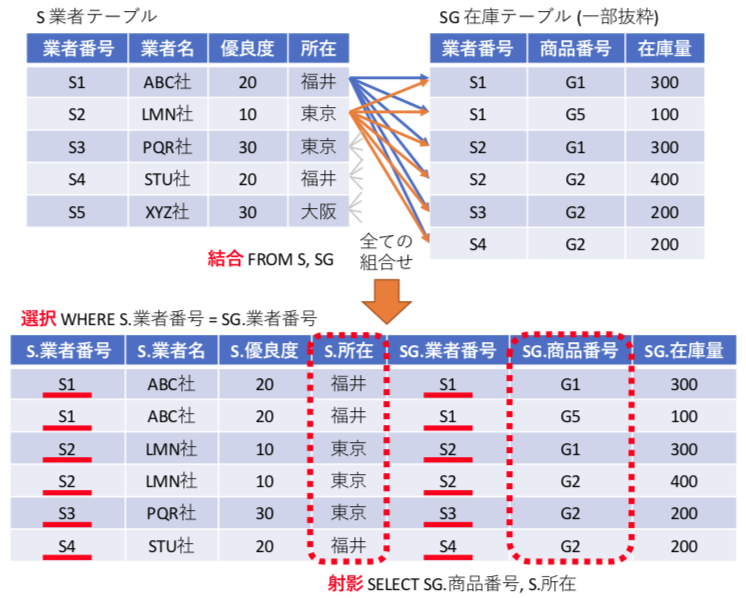
SELECTの結合処理と処理内容
selectでの選択,結合,射影の処理(select 射影 from 結合 where 選択)を理解するために、同じ処理をC言語で書いたらどうなるかを示す。
// C言語なら
struct Table_S {
char 業者番号[ 6 ] ;
char 業者名[ 22 ] ;
int 優良度 ;
char 所在[ 16 ] ;
} S[] = {
{ "S1" , "ABC社" , 20 , "福井" } ,
:
} ;
struct Table_SG {
char 業者番号[ 6 ] ;
char 商品番号[ 6 ] ;
int 在庫量 ;
} = SG[] {
{ "S1" , "G1" , 300 } ,
:
} ;
// FROM S
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
// FROM SG
for( int j = 0 ; j < sizeofarray( SG ) ; j++ ) {
// WHERE S.業者番号 = SG.業者番号
if ( strcmp( S[i].業者番号 , SG[j].業者番号 ) == 0 ) {
// SELECT SG.商品番号 , S.所在
printf( "%s %s¥n" , SG[j].商品番号 , S[i].所在 ) ;
}
}
}
(1) i,jの2重forループが、FROM節の結合に相当し、(2) ループ内のif文がWHERE節の選択に相当し、(3) printfの表示内容が射影に相当している。
射影の処理では、データの一部分を抽出することから、1件の抽出レコードが同じになることもある。この際の重複したデータを1つにまとめる場合には、DISTINCT を指定する。
SELECT DISTINCT SG.商品番号, S.所在 FROM S, SG WHERE SG.業者番号 = S.業者番号 ;
- 実験環境で結合/重複削除(学内のみ)
上記のプログラムでは、データの検索は単純 for ループで記載しているが、内部で HASH などが使われていると、昇順に処理が行われない場合も多い。出力されるデータの順序を指定したい場合には、ORDER BY … ASC (or DESC) を用いる
SELECT SG.商品番号, S.所在 FROM S, SG WHERE SG.業者番号 = S.業者番号 ORDER BY S.所在 ASC ; -- ASC:昇順 , DESC:降順 --
- 実験環境で結合/並び替え(学内のみ)
表型のデータと串刺し
FROM に記載する直積のための結合では、2つ以上のテーブルを指定しても良い。
SELECT S.業者名, G.商品名, SG.在庫量
FROM S, G, SG
WHERE S.業者番号 = SG.業者番号 -- 外部キー業者番号の対応付け --
AND SG.商品番号 = G.商品番号 -- 外部キー商品番号の対応付け --
// 上記の処理をC言語で書いたら
struct Table_G {
char 商品番号[ 6 ] ;
char 商品名[ 22 ] ;
char 色[ 4 ] ;
int 価格 ;
char 所在[ 12 ] ;
} = G[] = {
{ "G1" , "赤鉛筆" , "青" , 120 , "福井" } ,
:
} ;
// [結合] S,G,SGのすべての組み合わせ
// FROM S -- 結合
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
// FROM G -- 結合
for( int j = 0 ; j < sizeofarray( G ) ; j++ ) {
// FROM SG -- 結合
for( int k = 0 ; k < sizeofarray( SG ) ; k++ ) {
// [選択] 条件でレコードを選び出す
// WHERE S.業者番号 = SG.業者番号
// AND SG.商品番号 = G.商品番号
if ( strcmp( S[i].業者番号 , SG[k].業者番号 ) == 0
&& strcmp( SG[k].商品番号 , G[j].商品番号 ) == 0 ) {
// [射影] 使用するフィールドを出力
printf( "%s %s %d\n" ,
S[i].業者名 , G[j].商品名 , SG[k].在庫量 ) ;
}
}
}
}
- 実験環境で結合/3つのTABLEの串刺し(学内のみ)
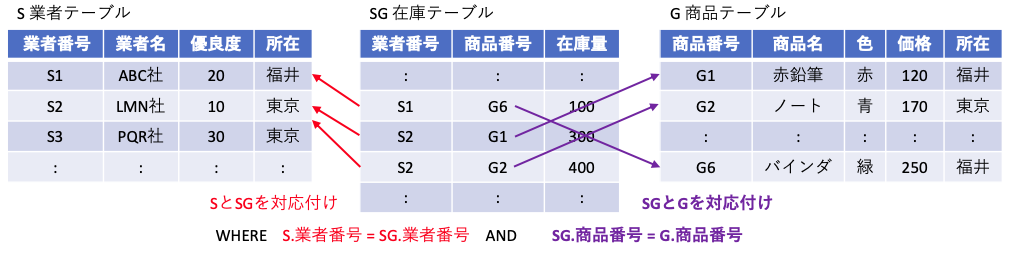 ここで結合と選択で実行している内容は、外部キーである業者番号を S から探す、商品番号を G から探している。この、外部キー対応しているものを探すという視点で、上記 C 言語のプログラムを書き換えると、以下のように表せる。
ここで結合と選択で実行している内容は、外部キーである業者番号を S から探す、商品番号を G から探している。この、外部キー対応しているものを探すという視点で、上記 C 言語のプログラムを書き換えると、以下のように表せる。
// FROM SG
for( int k = 0 ; k < sizeofarray( SG ) ; k++ ) {
// 外部キー SG.業者番号に対応するものを S から探す
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
if ( strcmp( S[i].業者番号 , SG[k].業者番号 ) == 0 ) {
// 外部キー SG.商品番号に対応するものを G から探す
for( int j = 0 ; j < sizeofarray( G ) ; j++ ) {
if ( strcmp(SG[k].商品番号,G[j].商品番号) == 0 ) {
printf( "%s %s %d\n" ,
S[i].業者名,G[j].商品名,SG[k].在庫量 ) ;
}
}
}
}
}
このような、複数の表の実体と関係を対応付けた検索を、データベースの専門の人は「データを串刺しにする」という言い方をすることも多い。
また、SQL では、このようなイメージの繰り返し処理を、数行で分かりやすく記述できている。このプログラム例では、キーに対応するものを単純 for ループで説明しているが、SQL ではプライマリキーなら、B木やハッシュなどを用いた効率の良い検索が自動的に行われる。このため、SQLを扱う応用プログラマは、SQLの結合の処理方法は通常はあまり考えなくて良い。