これまでの授業の中では、データを効率よく扱うためのデータ構造について議論をしてきた。これまでのプログラムの中では、データ構造のために動的メモリ(特にヒープメモリ)を多用してきた。ヒープメモリでは、malloc() 関数により指定サイズのメモリ空間を借りて、処理が終わったら free() 関数によって返却をしてきた。この返却を忘れたままプログラムを連続して動かそうとすると、返却されなかったメモリが使われない状態(メモリリーク)となり、メモリ領域不足から他のプログラムの動作に悪影響を及ぼす。
メモリリークを防ぐためには、malloc() で借りたら、free() で返すを実践すればいいのだが、複雑なデータ構造になってくると、こういった処理が困難となる。そこで、ヒープメモリの問題点について以下に説明する。
共有のあるデータの取扱の問題
リスト構造で集合計算の和集合を求める処理を考える。
// 集合和を求める処理
struct List* join( struct List* a , struct List* b )
{ struct List* ans = b ;
for( ; a != NULL ; a = a->next )
if ( !find( ans , a->data ) )
ans = cons( a->data , ans ) ;
return ans ;
}
void list_del( struct List* p )
{ // ダメなプログラムの例
while( p != NULL ) { // for( ; p != NULL ; p = p->next )
struct List* d = p ; // free( p ) ;
p = p->next ;
free( d ) ;
}
}
void main() {
// リストの生成
struct List* a = cons( 1 , cons( 2 , cons( 3 , NULL ) ) ) ;
struct List* b = cons( 2 , cons( 3 , cons( 4 , NULL ) ) ) ;
struct List* c = join( a , b ) ; // c = { 1, 2, 3, 4 }
// ~~~~~~~ ここは b
// a,b,cを使った処理
// 処理が終わったのでa,b,cを捨てる
list_del( a ) ;
list_del( b ) ;
list_del( c ) ; // list_del(b)ですでに消えている
} // このためメモリー参照エラー発生
このようなプログラムでは、c=join(a,b) ; が終わると下の図のようなデータ構造となる。しかし処理が終わってリスト廃棄list_del(c), list_del(b), listdel(a)を行おうとすると、bの先のデータは廃棄済みなのに、list_del(c)の実行時に、その領域を触ろうとして異常が発生する。
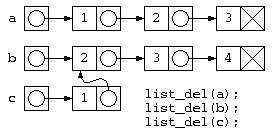
参照カウンタ法
上記の問題は、b の先のリストが c の一部とデータを共有しているために発生する。この解決方法として簡単な方法では、参照カウンタ法が用いられる。
参照カウンタ法では、データを参照するポインタの数をデータと共に保存する。
- データの中にポインタ数を覚える参照カウンタを設け、データを生成した時に1とする。
- 処理の中で共有が発生すると、参照カウンタをカウントアップする。
- データを捨てる際には、参照カウンタをカウントダウンし、0になったら本当にそのデータを消す。
struct List {
int refc ; // 参照カウンタ
int data ; // データ
struct List* next ; // 次のポインタ
} ;
void list_del( strcut List* p ) { // 再帰で全廃棄
if ( p != NULL
&& --(p->refc) <= 0 ) { // 参照カウンタを減らし
list_del( p->next ) ; // 0ならば本当に消す
free( p ) ;
}
}
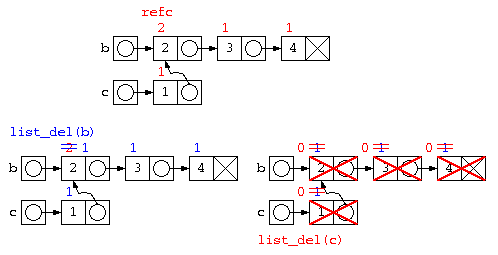
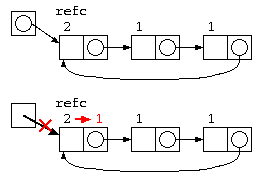
ただし、参照カウンタ法は、循環リストではカウンタが0にならないので、取扱いが苦手。
unix i-nodeで使われている参照カウンタ
unixのファイルシステムでは、1つのファイルを別の名前で参照するハードリンクという機能がある。このため、ファイルの実体には参照カウンタが付けられている。unix では、ファイルを生成する時に参照カウンタを1にする。ハードリンクを生成すると参照カウンタをカウントアップ”+1″する。ファイルを消す場合は、基本的に参照カウンタのカウントダウン”-1″が行われ、参照カウンタが”0″になるとファイルの実体を消去する。
ガベージコレクタ
では、循環リストの発生するようなデータで、共有が発生するような場合には、どのようにデータを管理すれば良いだろうか?
最も簡単な方法は、処理が終わっても、使い終わったメモリを返却しない、方法である。ただし、このままでは、メモリを使い切ってしまう。
そこで、廃棄処理をしないまま、ゴミだらけになってしまったメモリ空間を再利用するのが、ガベージコレクタ(一般的にはGCと略される)である。
ガベージコレクタは、貸し出すメモリ空間が無くなった時に起動され、
- すべてのメモリ空間に、「不要」の目印をつける。(unmark処理)
- 変数に代入されているデータが参照している先のデータは「使用中」の目印をつける。(mark処理-目印をつける)
- その後、「不要」の目印がついている領域は、だれも使っていないので回収する。(sweep処理-掃き掃除する)
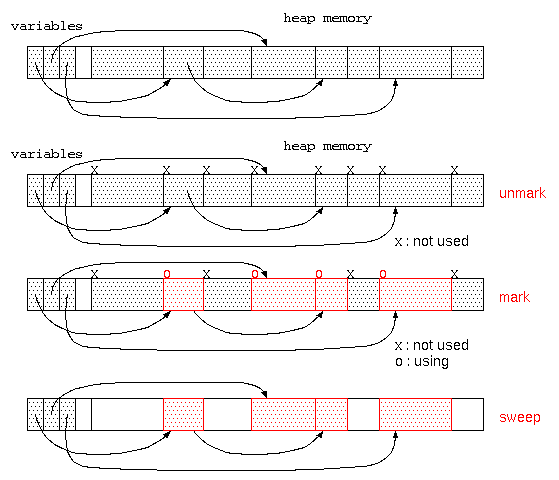
この方式は、マークアンドスイープ法と呼ばれる。ただし、このようなガベージコレクタはメモリ空間が広い場合は、処理時間かかり、さらにこの処理中は、他の処理ができず処理が中断されるので、コンピュータの操作性という点では問題となる。
最近のプログラミング言語では、参照カウンタとガベージコレクタを取り混ぜた方式でメモリ管理をする機能が組み込まれている。このようなシステムでは、局所変数のような関数に入った時点で生成され関数終了ですぐに不要となる領域は、参照カウンタで管理し、大域変数のような長期間保管するデータはガベージコレクタで管理される。
大量のメモリ空間で、メモリが枯渇したタイミングでガベージコレクタを実行すると、長い待ち時間となることから、ユーザインタフェースの待ち時間に、ガベージコレクタを少しづつ動かすなどの方式もとることもある。