複素数クラスによる演習
複素数クラスの例
隠蔽化と基本的なオブジェクト指向の練習課題として、前回の授業では、直交座標系による複素数クラスを示した。今回の授業では、演習を行うとともに直交座標系を極座標系にクラス内部を変更したことにより、隠蔽化の効果について考えてもらい、第1回レポートとする。
直交座標系
前回の授業で示した直交座標系のクラス。比較対象とするために再掲。
#include <stdio.h>
#include <math.h>
// 直交座標系の複素数クラス
class Complex {
private:
double re ; // 実部
double im ; // 虚部
public:
void print() {
printf( "%lf + j%lf¥n" , re , im ) ;
}
Complex( double r , double i ) // 実部虚部のコンストラクタ
: re( r ) , im( i ) {}
Complex() // デフォルトコンストラクタ
: re( 0.0 ) , im( 0.0 ) {}
void add( Complex z ) {
// 加算は、直交座標系だと極めてシンプル
re = re + z.re ;
im = im + z.im ;
}
void mul( Complex z ) {
// 乗算は、直交座標系だと、ちょっと煩雑
double r = re * z.re - im * z.im ;
double i = re * z.im + im * z.re ;
re = r ;
im = i ;
}
double get_re() {
return re ;
}
double get_im() {
return im ;
}
double get_abs() { // 絶対値
return sqrt( re*re + im*im ) ;
}
double get_arg() { // 偏角
return atan2( im , re ) ;
}
} ; // ←何度も繰り返すけど、ここのセミコロン忘れないでね
int main() {
// 複素数を作る
Complex a( 1.0 , 2.0 ) ;
Complex b( 2.0 , 3.0 ) ;
// 複素数の計算
a.print() ;
a.add( b ) ;
a.print() ;
a.mul( b ) ;
a.print() ;
return 0 ;
}
極座標系
上記の直交座標系の Complex クラスは、加減算の関数は単純だけど、乗除算の関数を書く時には面倒になってくる。この場合、極座標系でプログラムを書いたほうが判りやすいかもしれない。
// 局座標系の複素数クラス
class Complex {
private:
double r ; // 絶対値 r
double th ; // 偏角 θ
public:
void print() {
printf( "%lf ∠ %lf¥n" , r , th / 3.14159265 * 180.0 ) ;
}
Complex() // デフォルトコンストラクタ
: r( 0.0 ) , th( 0.0 ) {}
// 表面的には、同じ使い方ができるように
// 直交座標系でのコンストラクタ
Complex( double x , double y ) {
r = sqrt( x*x + y*y ) ;
th = atan2( y , x ) ; // 象限を考慮したatan()
}
// 極座標系だと、わかりやすい処理
void mul( Complex z ) {
// 極座標系での乗算は
r = r * z.r ; // 絶対値の積
th = th + z.th ; // 偏角の和
}
// 反対に、加算は面倒な処理になってしまう。
void add( Complex z ) {
; // 自分で考えて
}
// ゲッターメソッド
double get_abs() {
return r ;
}
double get_arg() {
return th ;
}
double get_re() { // 直交座標系との互換性のためのゲッターメソッド
return r * cos( th ) ;
}
double get_im() {
return r * sin( th ) ;
}
} ; // ←しつこく繰り返すけど、セミコロン忘れないでね(^_^;
このように、プログラムを開発していると、当初は直交座標系でプログラムを記述していたが、途中で極座標系の方がプログラムが書きやすいという局面となるかもしれない。しかし、オブジェクト指向による隠蔽化を正しく行っていれば、利用者に影響なく「データ構造」や「その手続き(メソッド)」を書換えることも可能となる。
このように、プログラムをさらに良いものとなるべく書換えることは、オブジェクト指向ではリファクタリングと呼ぶ。
正しくクラスを作っていれば、クラス利用者への影響が最小にしながらリファクタリングが可能となる。
const 指定 (経験者向け解説)
C++ では、間違って値を書き換えるような処理を書けないようにするための、const 指定の機能がある。
void bar( char* s ) { // void bar( const char* s ) {...}
printf( "%s\n" , s ) ; // で宣言すべき。
}
void foo( const int x ) {
// ~~~~~~~~~~~
x++ ; // 定数を書き換えることはできない。
printf( "%d\n" , x ) ;
}
int main() {
const double pi = 3.141592 ;
// C言語で #define PI 3.141592 と同等
bar( "This is a pen" ) ; // Warning: string constant to 'char*' の警告
int a = 123 ;
foo( a ) ;
return 0 ;
}
前述の、getter メソッドの例では要素を参照するだけで、オブジェクトの中身が変化しない。逆に言えば、getter のメソッド内にはオブジェクトに副作用のある処理を書いてはいけない。こういった用途に、オブジェクトを変化させないメソッド宣言がある。先の、get_re() は、
class ... {
:
inline double get_re() const {
// ~~~~~
re = 0 ; // 文法エラー
return re ;
}
} ;
クラスオブジェクトを引数にする場合
前述の add() メソッドでは、”void add( Complex z ) { … }” にて宣言をしていた。しかし、引数となる変数 z の実体が巨大な場合、この書き方では値渡しになるため、データの複製の処理時間が問題となる場合がある。この場合は、(書き方1)のように、z の参照渡しにすることで、データ複製の時間を軽減する。また、この例では、引数 z の中身を間違って add() の中で変化させる処理を書いてしまうかもしれない。そこで、この事例では(書き方2)のように const 指定もすべきである。
// (書き方1)
class Complex {
:
void add( Complex& z ) {
re += z.re ;
im += z.im ;
}
} ;
// (書き方2)
class Complex {
:
void add( const Complex& z )
{ // ~~~~~~~~~~~~~~~~
re += z.re ;
im += z.im ;
}
} ;
レポート1(複素数の加減乗除)
授業中に示した、直交座標系・極座標系の複素数のプログラムをベースに、記載されていない減算・除算のプログラムを作成し、レポートを作成する。 レポートには、下記のものを記載すること。
- プログラムリスト
- プログラムへの説明
- 動作確認の結果
- プログラムより理解できること。
- 実際にプログラムを書いてみて分かった問題点など…
オブジェクト指向の基本プログラムと複素数クラス
C++のクラスで表現
前回の講義での、構造体のポインタ渡しをC++の基本的なクラスで記述した場合のプログラムを再掲する。
#include <stdio.h>
#include <string.h>
// この部分はクラス設計者が書く
class Person {
private: // クラス外からアクセスできない部分
// データ構造を記述
char name[10] ; // メンバーの宣言
int age ;
public: // クラス外から使える部分
// データに対する処理を記述
void set( char s[] , int a ) { // メソッドの宣言
// pのように対象のオブジェクトを明記する必要はない。
strcpy( name , s ) ;
age = a ;
}
void print() {
printf( "%s %d¥n" , name , age ) ;
}
} ; // ← 注意ここのセミコロンを書き忘れないこと。
// この部分はクラス利用者が書く
int main() {
Person saitoh ;
saitoh.set( "saitoh" , 55 ) ;
saitoh.print() ;
// 文法エラーの例
printf( "%d¥n" , saitoh.age ) ; // phoneはprivateなので参照できない。
return 0 ;
}
この様にC++のプログラムに書き換えたが、内部の処理は元のC言語と同じであり、オブジェクトへの関数呼び出し saitoh.set(…) などが呼び出されても、set() は、オブジェクトのポインタを引数して持つ関数として、機械語が生成されるだけである。
用語の解説:C++のプログラムでは、データ構造とデータの処理を、並行しながら記述する。 データ構造に対する処理は、メソッド(method)と呼ばれる。 データ構造とメソッドを同時に記載したものは、クラス(class)と呼ぶ。 そのデータに対し具体的な値や記憶域が割り当てられたものをオブジェクト(object)と呼ぶ。
C++では隠蔽化をさらに明確にするために、private: や public: といったアクセス制限を指定できる。private: は、そのメソッドの中でしか使うことができない要素や関数であり、public: は、メソッド以外からでも参照したり呼出したりできる。オブジェクト指向でプログラムを書くとき、データ構造や関数の処理方法は、クラス内部の設計者しか触れないようにしておけば、その内部を改良することができる。しかし、クラスの利用者が勝手に内部データを触っていると、内部設計者が改良するとそのプログラムは動かないものになってしまう。
隠蔽化を的確に行うことで、クラスの利用者はクラスの内部構造を触ることができなくなる。一方でクラス設計者はクラスの外部への挙動が変化しないようにクラス内部を修正することに心がければ、クラス利用者への影響がないままクラスの内部を改良できる。このように利用者への影響を最小に、常にプログラムを修正することをリファクタリングと呼ぶ。
クラス限定子
前述のプログラムでは、class 宣言の中に関数内部の処理を記述していた。しかし関数の記述が長い場合は、書ききれないこういう場合はクラス限定子を使って、メソッドの具体的な処理をクラス宣言の外に記載する。
class Person {
private:
char name[10] ;
int age ;
public:
// メソッドのプロトタイプ宣言
void set( char s[] , int a) ;
void print() ;
} ;
// メソッドの実体をクラス宣言の外に記載する。
void Person::set( char s[] , int a ) { // Person::set()
strcpy( name , s ) ;
age = a ;
}
void Person::print() { // Person::print()
printf( "%s %d¥n" , name , age ) ;
}
inline 関数と開いたサブルーチン
オブジェクト指向では、きわめて簡単な処理な関数を使うことも多い。
例えば、上記のプログラム例で、クラス利用者に年齢を読み出すことは許しても書き込みをさせたくない場合、以下のような、inline 関数を定義する。(getterメソッド)
# 逆に、値の代入専用のメソッドは、setterメソッドと呼ぶclass Person { private: char name[10] ; int age ; public: // メソッドのプロトタイプ宣言 inline int get_age() { return age ; } // getter inline void set_age( int a ) { age = a ; } // setter } ;ここで inline とは、開いた関数(開いたサブルーチン)を作る指定子である。通常、機械語を生成するとき中身を参照するだけの機械語と、get_age() を呼出したときに関数呼び出しを行う機械語が作られる(閉じたサブルーチン)が、age を参照するだけのために関数呼び出しの機械語はムダが多い。inline を指定すると、入り口出口のある関数は生成されず、get_age() の処理にふさわしい age を参照するだけの機械語が生成される。
# 質問:C言語で開いたサブルーチンを使うためにはどういった機能があるか?
コンストラクタとデストラクタ
プログラムを記述する際、データの初期化忘れや終了処理忘れで、プログラムの誤動作の原因になることが多い。
このための機能がコンストラクタ(構築子)とデストラクタ(破壊子)という。
コンストラクタは、返り値を記載しない関数でクラス名(仮引数…)の形式で宣言し、オブジェクトの宣言時に初期化を行う処理として呼び出される。デストラクタは、~クラス名() の形式で宣言し、オブジェクトが不要となる際に、自動的に呼び出し処理が埋め込まれる。
class Person {
private:
// データ構造を記述
char name[10] ;
int age ;
public:
Person() { // (A) 引数なしのコンストラクタ
name[0] = 'class Person {
private:
// データ構造を記述
char name[10] ;
int age ;
public:
Person() { // (A) 引数なしのコンストラクタ
name[0] = '\0' ;
age = 0 ;
}
Person( char s[] , int a ) { // (B) 引数ありのコンストラクタ
strcpy( name , s ) ;
age = a ;
}
~Person() { // デストラクタ
print() ;
}
void print() {
printf( "'%s' = %d¥n" , name , age ) ;
}
} ;
int main() {
Person saitoh( "saitoh" , 55 ) ; // オブジェクトsaitohを"saitoh"と55で初期化
Person tomoko ; // 引数なしのコンストラクタで初期化される。
return 0 ;
// main を抜ける時にオブジェクトsaitohは不要になるので、
// デストラクタが自動的に呼び出され、'saitoh' = 55 が表示。
// 同様に tomoko のデストラクタでは、'' = 0 を表示。
}
' ;
age = 0 ;
}
Person( char s[] , int a ) { // (B) 引数ありのコンストラクタ
strcpy( name , s ) ;
age = a ;
}
~Person() { // デストラクタ
print() ;
}
void print() {
printf( "'%s' = %d¥n" , name , age ) ;
}
} ;
int main() {
Person saitoh( "saitoh" , 55 ) ; // オブジェクトsaitohを"saitoh"と55で初期化
Person tomoko ; // 引数なしのコンストラクタで初期化される。
return 0 ;
// main を抜ける時にオブジェクトsaitohは不要になるので、
// デストラクタが自動的に呼び出され、'saitoh' = 55 が表示。
// 同様に tomoko のデストラクタでは、'' = 0 を表示。
}
このクラスの中には、(A)引数無しのコンストラクタと、(B)引数ありのコンストラクタが出てくる。C++では、同じ名前の関数でも引数の数や型に応じて呼出す関数を適切に選んでくれる。(関数のオーバーロード)
デストラクタは、データが不要となった時に自動的に呼び出してくれる関数で、一般的にはC言語でのファイルの fopen() , fclose() のようなものを使う処理で、コンストラクタで fopen() , デストラクタで fclose() を呼出すように使うことが多いだろう。同じように、コンストラクタで malloc() を呼出し、デストラクタで free() を呼出すというのが定番の使い方だろう。
複素数クラスの例
隠蔽化と基本的なオブジェクト指向の練習課題として、複素数クラスをあげる。ここでは、複素数の加算・乗算を例に説明をするので、減算・除算などの処理を記述することで、クラスの扱いに慣れてもらう。
直交座標系の複素数クラス
#include <stdio.h>
#include <math.h>
// 直交座標系の複素数クラス
class Complex {
private:
double re ; // 実部
double im ; // 虚部
public:
void print() {
printf( "%lf + j%lf¥n" , re , im ) ;
}
Complex( double r , double i ) // コンストラクタで要素の
: re( r ) , im( i ) { // 初期化はこのように書いてもいい
} // re = r ; im = i ; の意味
Complex() // デフォルトコンストラクタ
: re( 0.0 ) , im( 0.0 ) {
}
void add( Complex z ) {
// 加算は、直交座標系だと極めてシンプル
re = re + z.re ;
im = im + z.im ;
}
void mul( Complex z ) {
// 乗算は、直交座標系だと、ちょっと煩雑
double r = re * z.re - im * z.im ;
double i = re * z.im + im * z.re ;
re = r ;
im = i ;
}
double get_re() {
return re ;
}
double get_im() {
return im ;
}
double get_abs() { // 絶対値
return sqrt( re*re + im*im ) ;
}
double get_arg() { // 偏角
return atan2( im , re ) ;
}
} ; // ←何度も繰り返すけど、ここのセミコロン忘れないでね
int main() {
// 複素数を作る
Complex a( 1.0 , 2.0 ) ;
Complex b( 2.0 , 3.0 ) ;
// 複素数の計算
a.print() ;
a.add( b ) ;
a.print() ;
a.mul( b ) ;
a.print() ;
return 0 ;
}
練習課題
- 上記の直交座標系の複素数のクラスのプログラムを入力し、動作を確認せよ。
- このプログラムに減算や除算の処理を追加せよ。
この練習課題は、次週に予定している「曲座標系の複素数クラス」に変更となった場合のプログラムを加え、第1回のレポート課題となります。
引数の取扱いとオブジェクト指向の導入
値渡し,ポインタ渡し,参照渡し
C言語をあまりやっていない学科の人向けのC言語の基礎として、関数との値渡し, ポインタ渡しについて説明する。ただし、参照渡しについては電子情報の授業でも細かく扱っていない内容なので電子情報系学生も要注意。
オブジェクト指向のプログラムでは、構造体のポインタ渡し(というよりは参照渡し)を多用するが、その基本となる関数との値の受け渡しの理解のため、以下に値渡し・ポインタ渡し・参照渡しについて説明する。
ポインタと引数
値渡し(Call by value)
// 値渡しのプログラム
void foo( int x ) { // x は局所変数(仮引数は呼出時に
// 対応する実引数で初期化される。
x++ ;
printf( "%d¥n" , x ) ;
}
int main() {
int a = 123 ;
foo( a ) ; // 124
// 処理後も main::a は 123 のまま。
foo( a ) ; // 124
return 0 ;
}
このプログラムでは、aの値は変化せずに、124,124 が表示される。ここで、関数 foo() を呼び出しても、関数に「値」が渡されるだけで、foo() を呼び出す際の実引数 a の値は変化しない。こういった関数に値だけを渡すメカニズムは「値渡し」と呼ぶ。
値渡しだけが使われれば、関数の処理後に変数に影響が残らない。こういった処理の影響が残らないことは一般的に「副作用がない」という。
大域変数を使ったプログラム
でも、プログラムによっては、124,125 と変化して欲しい場合もある。どのように記述すべきだろうか?
// 大域変数を使う場合
int x ;
void foo() {
x++ ;
printf( "%d¥n" , x ) ;
}
int main() {
x = 123 ;
foo() ; // 124
foo() ; // 125
return 0 ;
}
しかし、このプログラムは大域変数を使うために、間違いを引き起こしやすい。大域変数はどこでも使える変数であり、副作用が発生して間違ったプログラムを作る原因になりやすい。
// 大域変数が原因で予想外の挙動をしめす簡単な例
int i ;
void foo() {
for( i = 0 ; i < 2 ; i++ )
printf( "A" ) ;
}
int main() {
for( i = 0 ; i < 3 ; i++ ) // このプログラムでは、AA AA AA と
foo() ; // 表示されない。
return 0 ;
}
ポインタ渡し(Call by pointer)
C言語で引数を通して、呼び出し側の値を変化して欲しい場合は、変更して欲しい変数のアドレスを渡し、関数側では、ポインタ変数を使って受け取った変数のアドレスの示す場所の値を操作する。(副作用の及ぶ範囲を限定する) こういった、値の受け渡し方法は「ポインタ渡し」と呼ぶ。
// ポインタ渡しのプログラム
void foo( int* p ) { // p はポインタ
(*p)++ ;
printf( "%d¥n" , *p ) ;
}
int main() {
int a = 123 ;
foo( &a ) ; // 124
// 処理後 main::a は 124 に増えている。
foo( &a ) ; // 124
return 0 ; // さらに125と増える
}
ポインタを利用して引数に副作用を与える方法は、ポインタを正しく理解していないプログラマーでは、危険な操作となる。
参照渡し(Call by reference)
C++では、ポインタ渡しを極力使わないようにするために、参照渡しを利用する。ただし、ポインタ渡しも参照渡しも、機械語レベルでは同じ処理にすぎない。
// ポインタ渡しのプログラム void foo( int& x ) { // xは参照 x++ ; printf( "%d¥n" , x ) ; } int main() { int a = 123 ; foo( a ) ; // 124 // 処理後 main::a は 124 に増えている。 foo( a ) ; // 124 return 0 ; // さらに125と増える。 }
大きなプログラムを作る場合、副作用のあるプログラムの書き方は、間違ったプログラムの原因となりやすい。そこで関数の呼び出しを中心としてプログラムを書くものとして、関数型プログラミングがある。
構造体の参照渡し
構造体のデータを関数で受け渡しをする場合は、参照渡しを利用する。
struct Person {
char name[ 20 ] ;
int age ;
} ;
void print( struct Person* p ) {
printf( "%s %d¥n" , p->name , p->age ) ;
}
void main() {
struct Person saitoh ;
strcpy( saitoh.name , "t-saitoh" ) ;
saitoh.age = 50 ;
print( &saitoh ) ; // ポインタによる参照渡し
}
このようなプログラムの書き方をすると、「データ saitoh に、print() せよ…」 といった処理を記述したようになる。 これを発展して、データ saitoh に、print という命令をするイメージにも見える。
この考え方を、そのままプログラムに反映させ、Personというデータは、 名前と年齢、データを表示するprintは…といったように、 データ構造と、そのデータ構造への処理をペアで記述すると分かりやすい。
オブジェクト指向の導入
構造体でオブジェクト指向もどき
例えば、名前と年齢の構造体で処理を記述する場合、 以下の様な記載を行うことで、データ設計者とデータ利用者で分けて 仕事ができることを説明。
// この部分はデータ構造の設計者が書く
// データ構造を記述
struct Person {
char name[10] ;
int age ;
} ;
// データに対する処理を記述
void setPerson( struct Person* p , char s[] , int a ) {
// ポインタの参照で表記
strcpy( (*p).name , s ) ;
(*p).age = a ;
}
void printPerson( struct Person* p ) {
// アロー演算子で表記 "(*p).name" は "p->name" で書ける
printf( "%s %d¥n" ,
p->name , p->age ) ;
}
// この部分は、データ利用者が書く
int main() {
// Personの中身を知らなくてもいいから配列を定義(データ隠蔽)
struct Person saitoh ;
setPerson( &saitoh , "saitoh" , 55 ) ;
struct Person table[ 10 ] ; // 初期化は記述を省略
for( int i = 0 ; i < 10 ; i++ ) {
// 出力する...という雰囲気で書ける(手続き隠蔽)
printPerson( &table[i] ) ;
}
return 0 ;
}
このプログラムの書き方では、mainの中を読むだけもで、 データ初期化とデータ出力を行うことはある程度理解できる。 この時、データ構造の中身を知らなくてもプログラムが理解でき、 データ実装者はプログラムを記述できる。これをデータ構造の隠蔽化という。 一方、setPerson()や、printPerson()という関数の中身についても、 初期化・出力の方法をどうするのか知らなくても、 関数名から動作は推測できプログラムも書ける。 これを手続きの隠蔽化という。
C++のクラスで表現
上記のプログラムをそのままC++に書き直すと以下のようになる。
#include <stdio.h>
#include <string.h>
// この部分はクラス設計者が書く
class Person {
private: // クラス外からアクセスできない部分
// データ構造を記述
char name[10] ; // メンバーの宣言
int age ;
public: // クラス外から使える部分
// データに対する処理を記述
void set( char s[] , int a ) { // メソッドの宣言
// pのように対象のオブジェクトを明記する必要はない。
strcpy( name , s ) ;
age = a ;
}
void print() {
printf( "%s %d¥n" , name , age ) ;
}
} ; // ← 注意ここのセミコロンを書き忘れないこと。
// この部分はクラス利用者が書く
int main() {
Person saitoh ;
saitoh.set( "saitoh" , 55 ) ;
saitoh.print() ;
// 文法エラーの例
printf( "%d¥n" , saitoh.age ) ; // age は private なので参照できない。
return 0 ;
}
用語の解説:C++のプログラムでは、データ構造とデータの処理を、並行しながら記述する。 データ構造に対する処理は、メソッド(method)と呼ばれる。 データ構造とメソッドを同時に記載したものは、クラス(class)と呼ぶ。 そのclassに対し、具体的な値や記憶域が割り当てられたものをオブジェクト(object)と呼ぶ。
オブジェクト指向プログラミング・ガイダンス2024
専攻科2年のオブジェクト指向プログラミングの授業の1回目。
最近のプログラミングの基本となっているオブジェクト指向について、その機能についてC++言語を用いて説明し、後半では対象(オブジェクト)をモデル化して設計するための考え方(UML)について説明する。
評価は、3つの課題と最終テストを各25%づつで評価を行う。
オブジェクト指向プログラミングの歴史
最初のプログラム言語のFortran(科学技術計算向け言語)の頃は、処理を記述するだけだったけど、 COBOL(商用計算向け言語)ができた頃には、データをひとまとめで扱う「構造体」(C言語ならstruct {…}の考えができた。(データの構造化)
// C言語の構造体
struct Person { // 1人分のデータ構造をPersonとする
char name[ 20 ] ; // 名前
int b_year, b_month, b_day ; // 誕生日
} ;
一方、初期のFortranでは、プログラムの処理順序は、繰り返し処理も if 文と goto 文で記載し、処理がわかりにくかった。その後のALGOLの頃には、処理をブロック化して扱うスタイル(C言語なら{ 文 … }の複文で 記述する方法ができてきた。(処理の構造化)
! 構造化文法がないFORTRAN
integer i
do 999 i = 0 , 9
write( 6 , '(I2)' ) i
999 continue
end
---------------------------------------------------
// ブロックの考えがない時代の雰囲気をC言語で表すと
int i = 0 ;
LOOP: if ( i >= 10 ) goto EXIT ;
if ( i % 2 != 0 ) goto NEXT ;
printf( "%d " , i ) ;
NEXT: i++ ;
goto LOOP ; // 処理の範囲を字下げ(インデント)で強調
EXIT:
---------------------------------------------------
// C 言語で書けば
int i ;
for( i = 0 ; i < 10 ; i++ ) {
if ( i % 2 == 0 ) {
printf( "%d¥n" , i ) ;
}
}
---------------------------------------------------
! 構造化文法のFORTRANで書くと
integer i
do i = 0 , 9
if ( mod( i , 2 ) == 0 ) then
print * , i
end if
end do
このデータの構造化・処理の構造化により、プログラムの分かりやすさは向上し、このデータと処理をブロック化した書き方は「構造化プログラミング(Structured Programming)」 と呼ばれる。
雑談
ここで紹介した、最古の高級言語 Fortran や COBOL は、今でも使われている。Fortran は、スーパーコンピュータなどで行われる数値シミュレーションでは、広く利用されている。また COBOL は、銀行などのシステムでもまだ使われている。しかしながら、新システムへの移行で COBOL を使えるプログラマーが定年を迎え減っていることから、移行トラブルが発生している。特に、CASEツール(UMLなどの図をベースにしたデータからプログラムを自動生成するツール)によって得られた COBOL のコードが移行を妨げる原因となることもある。
この後、様々なプログラム言語が開発され、C言語などもできてきた。 一方で、シミュレーションのプログラム開発(例simula)では、 シミュレーション対象(object)に対して、命令するスタイルの書き方が生まれ、 データに対して命令するという点で、擬人法のようなイメージで直感的にも分かりやすかった。 これがオブジェクト指向プログラミング(Object Oriented Programming)の始まりとなる。略記するときは OOP などと書くことが多い。
この考え方を導入した言語の1つが Smalltalk であり、この環境では、プログラムのエディタも Smalltalk で記述したりして、オブジェクト指向がGUIのプログラムと親和性が良いことから、この考え方は多くのプログラム言語へと取り入れられていく。
C言語にこのオブジェクト指向を取り入れ、C++が開発される。さらに、この文法をベースとした、 Javaなどが開発されている。最近の新しい手続き型言語では、どれもオブジェクト指向の考えが使われている。
この授業の中ではオブジェクト指向プログラミングにおける、隠蔽化, 派生と継承, 仮想関数 などの概念を説明する。
構造体の導入
専攻科の授業では、電子情報以外の学科系の学生さんもいるので、まずは C 言語での構造体の説明を行う。
C++でのオブジェクト指向は、C言語の構造体の表記がベースになっているので、まずは構造体の説明。
// 構造体の宣言
struct Person { // Personが構造体につけた名前
char name[ 20 ] ; // 要素1
int phone ; // 要素2
} ; // 構造体定義とデータ構造宣言を
// 別に書く時は「;」の書き忘れに注意
// 構造体変数の宣言
struct Person saitoh ;
struct Person data[ 10 ] ;
// 実際にデータを参照 構造体変数.要素名
strcpy( saitoh.name , "t-saitoh" ) ;
saitoh.phone = 272925 ;
for( int i = 0 ; i < 10 ; i++ ) {
scanf( "%d%s" , data[ i ].name , &(data[ i ].phone) ) ;
}
構造体に慣れていない人のための課題
- 以下に、C言語の構造体を使った基本的なプログラムを示す。このプログラムでは、国語,算数,理科の3科目と名前の5人分のデータより、各人の平均点を計算している。このプログラムを動かし、以下の機能を追加せよ。レポートには プログラムリストと動作結果の分かる結果を付けること。
- 国語の最低点の人を探し、名前を表示する処理。
- 算数の平均点を求める処理。
#include <stdio.h>
struct Student {
char name[ 20 ] ;
int kokugo ;
int sansu ;
int rika ;
} ;
struct Student table[5] = {
// name , kokugo , sansu , rika
{ "Aoyama" , 56 , 95 , 83 } ,
{ "Kondoh" , 78 , 80 , 64 } ,
{ "Saitoh" , 42 , 78 , 88 } ,
{ "Sakamoto" , 85 , 90 , 36 } ,
{ "Yamagosi" ,100 , 72 , 65 } ,
} ;
int main() {
int i = 0 ;
for( i = 0 ; i < 5 ; i++ ) {
double sum = table[i].kokugo + table[i].sansu + table[i].rika ;
printf( "%-10.10s %3d %3d %3d %6.2lf\n" ,
table[i].name , table[i].kokugo , table[i].sansu , table[i].rika ,
sum / 3.0 ) ;
}
return 0 ;
}
値渡し,ポインタ渡し,参照渡し
C言語をあまりやっていない学科の人向けのC言語の基礎として、関数との値渡し, ポインタ渡しについて説明する。ただし、参照渡しについては電子情報の授業でも細かく扱っていない内容なので電子情報系学生も要注意。
オブジェクト指向のプログラムでは、構造体のポインタ渡し(というよりは参照渡し)を多用するが、その基本となる関数との値の受け渡しの理解のため、以下に値渡し・ポインタ渡し・参照渡しについて説明する。
ポインタと引数
値渡し(Call by value)
// 値渡しのプログラム
void foo( int x ) { // x は局所変数(仮引数は呼出時に
// 対応する実引数で初期化される。
x++ ;
printf( "%d¥n" , x ) ;
}
int main() {
int a = 123 ;
foo( a ) ; // 124
// 処理後も main::a は 123 のまま。
foo( a ) ; // 124
return 0 ;
}
このプログラムでは、aの値は変化せずに、124,124 が表示される。ここで、関数 foo() を呼び出しても、関数に「値」が渡されるだけで、foo() を呼び出す際の実引数 a の値は変化しない。こういった関数に値だけを渡すメカニズムは「値渡し」と呼ぶ。
値渡しだけが使われれば、関数の処理後に変数に影響が残らない。こういった処理の影響が残らないことは一般的に「副作用がない」という。
大域変数を使ったプログラム
でも、プログラムによっては、124,125 と変化して欲しい場合もある。どのように記述すべきだろうか?
// 大域変数を使う場合
int x ;
void foo() {
x++ ;
printf( "%d¥n" , x ) ;
}
int main() {
x = 123 ;
foo() ; // 124
foo() ; // 125
return 0 ;
}
しかし、このプログラムは大域変数を使うために、間違いを引き起こしやすい。大域変数はどこでも使える変数であり、副作用が発生して間違ったプログラムを作る原因になりやすい。
// 大域変数が原因で予想外の挙動をしめす簡単な例
int i ;
void foo() {
for( i = 0 ; i < 2 ; i++ )
printf( "A" ) ;
}
int main() {
for( i = 0 ; i < 3 ; i++ ) // このプログラムでは、AA AA AA と
foo() ; // 表示されない。
return 0 ;
}
ポインタ渡し(Call by pointer)
C言語で引数を通して、呼び出し側の値を変化して欲しい場合は、変更して欲しい変数のアドレスを渡し、関数側では、ポインタ変数を使って受け取った変数のアドレスの示す場所の値を操作する。(副作用の及ぶ範囲を限定する) こういった、値の受け渡し方法は「ポインタ渡し」と呼ぶ。
// ポインタ渡しのプログラム
void foo( int* p ) { // p はポインタ
(*p)++ ;
printf( "%d¥n" , *p ) ;
}
int main() {
int a = 123 ;
foo( &a ) ; // 124
// 処理後 main::a は 124 に増えている。
foo( &a ) ; // 124
return 0 ; // さらに125と増える
}
ポインタを利用して引数に副作用を与える方法は、ポインタを正しく理解していないプログラマーでは、危険な操作となる。
参照渡し(Call by reference)
C++では、ポインタ渡しを極力使わないようにするために、参照渡しを利用する。ただし、ポインタ渡しも参照渡しも、機械語レベルでは同じ処理にすぎない。
// ポインタ渡しのプログラム void foo( int& x ) { // xは参照 x++ ; printf( "%d¥n" , x ) ; } int main() { int a = 123 ; foo( a ) ; // 124 // 処理後 main::a は 124 に増えている。 foo( a ) ; // 124 return 0 ; // さらに125と増える。 }
大きなプログラムを作る場合、副作用のあるプログラムの書き方は、間違ったプログラムの原因となりやすい。そこで関数の呼び出しを中心としてプログラムを書くものとして、関数型プログラミングがある。
オブジェクト指向とソフトウェア工学
オブジェクト指向プログラミングの最後の総括として、 ソフトウェア工学との説明を行う。
トップダウン設計とウォーターフォール型開発
ソフトウェア工学でプログラムの開発において、一般的なサイクルとしては、 専攻科などではどこでも出てくるPDCAサイクル(Plan, Do, Check, Action)が行われる。 この時、プログラム開発の流れとして、大企業でのプログラム開発では一般的に、 トップダウン設計とウォーターフォール型開発が行われる。
トップダウン設計では、全体の設計(Plan)を受け、プログラムのコーディング(Do)を行い、 動作検証(Check)をうけ、最終的に利用者に納品し使ってもらう(Action)…の流れで開発が行われる。設計(Plan)の中身は、要件定義や機能仕様や動作仕様…といった細かなフェーズになることも多い。 この場合、コーディングの際に設計の不備が見つかり設計のやり直しが発生すれば、 全行程の遅延となることから、前段階では完璧な設計が必要となる。 このような、上位設計から下流工程にむけ設計する方法は、トップダウン設計などと呼ばれる。また、処理は前段階へのフィードバック無しで次工程へ流れ、 川の流れが下流に向かう状態にたとえ、ウォーターフォールモデルと呼ばれる。

引用:Think IT 第2回開発プロセスモデル
このウォーターフォールモデルに沿った開発では、横軸時間、縦軸工程とした ガントチャートなどを描きながら進捗管理が行われる。

引用:Wikipedia ガントチャート
V字モデル
一方、チェック工程(テスト工程)では、 要件定義を満たしているかチェックしたり、基本設計や詳細設計が仕様を満たすかといったチェックが存在し、テストの前工程とそれぞれ対応した機能のチェックが存在する。 その各工程に対応したテストを経て最終製品となる様は、V字モデルと呼ばれる。
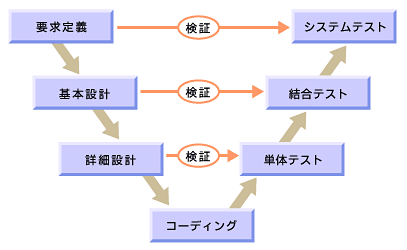
引用:@IT Eclipseテストツール活用の基礎知識
しかし、ウォーターフォールモデルでは、(前段階の製作物の不備は修正されるが)前段階の設計の不備があっても前工程に戻るという考えをとらないため、全体のPDCAサイクルが終わって次のPDCAサイクルまで問題が残ってしまう。巨大プロジェクトで大量の人が動いているだから、簡単に方針が揺らいでもトラブルの元にしかならないことから、こういった手法は大人数での巨大プロジェクトでのやり方である。
ボトムアップ設計とアジャイル開発
少人数でプログラムを作っている時(あるいはプロトタイプ的な開発)には、 部品となる部分を完成させ、それを組合せて全体像を組み上げる手法もとられる。 この方法は、ボトムアップ設計と呼ばれる。このような設計は場当たり的な開発となる場合があり設計の見直しも発生しやすい。
また、ウォーターフォールモデルでは、前工程の不備をタイムリーに見直すことができないが、 少人数開発では適宜前工程の見直しが可能となる。 特にオブジェクト指向プログラミングを実践して隠蔽化が正しく行われていれば、 オブジェクト指向によるライブラリの利用者への影響を最小にしながら、ライブラリの内部設計の見直しも可能となる。 このような外部からの見た挙動を変えることなく内部構造の改善を行うことはリファクタリングと呼ばれる。
一方、プログラム開発で、ある程度の規模のプログラムを作る際、最終目標の全機能を実装したものを 目標に作っていると、全体像が見えずプログラマーの達成感も得られないことから、 機能の一部分だけ完成させ、次々と機能を実装し完成に近づける方式もとられる。 この方式では、機能の一部分の実装までが1つのPDCAサイクルとみなされ、 このPDCAサイクルを何度も回して機能を増やしながら完成形に近づける方式とも言える。 このような開発方式は、アジャイルソフトウェア開発と呼ぶ。 一つのPDCAサイクルは、アジャイル開発では反復(イテレーション)と呼ばれ、 短い開発単位を反復し製品を作っていく。この方法では、一度の反復後の実装を随時顧客に見てもらうことが可能であり、顧客とプログラマーが一体となって開発が進んでいく。
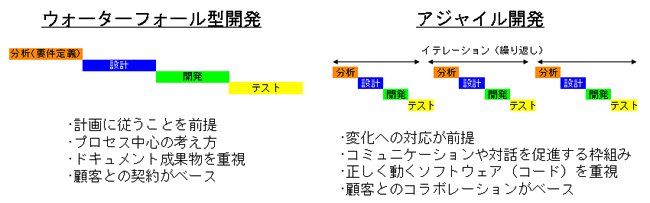
引用:コベルコシステム
エクストリームプログラミング
アジャイル開発を行うためのプログラミングスタイルとして、 エクストリームプログラミング(Xp)という考え方も提唱されている。 Xpでは、5つの価値(コミュニケーション,シンプル,フィードバック,勇気,尊重)を基本とし、 開発のためのプラクティス(習慣,実践)として、 テスト駆動開発(コーディングでは最初に機能をテストするためのプログラムを書き、そのテストが通るようにプログラムを書くことで,こまめにテストしながら開発を行う)や、 ペアプログラミング(2人ペアで開発し、コーディングを行う人とそのチェックを行う人で役割分担をし、 一定期間毎にその役割を交代する)などの方式が取られることが多い。
リーン・ソフトウェア開発は、トヨタ生産方式を一般化したリーン生産方式をソフトウェア開発に導入したもの。ソフトウェアでよく言われる話として「完成した機能の64%は使われていない」という分析がある。これでは、開発に要する人件費の無駄遣いとみることもできる。そこで、品質の良いものを作る中で無駄の排除を目的とし、本当にその機能は必要かを疑いながら、優先順位をつけ実装し、その実装が使われているのか・有効に機能しているのかを評価ながら開発をすすことが重要であり、リーン生産方式がソフトウェア開発にも取り込まれていった。
伽藍(がらん)とバザール
これは、通常のソフトウェア開発の理論とは異なるが、重要な開発手法の概念なので「伽藍とバザール」を紹介する。
伽藍(がらん)とは、優美で壮大な寺院のことであり、その設計・開発は、優れた設計・優れた技術者により作られた完璧な実装を意味している。バザールは有象無象の人の集まりの中で作られていくものを意味している。
たとえば、伽藍方式の代表格である Microsoft の製品は、優秀なプロダクトだが、中身の設計情報などを普通の人は見ることはできない。このため潜在的なバグが見つかりにくいと言われている。
これに対しバザール方式の代表格の Linux は、インターネット上にソースコードが公開され、誰もがソースコードに触れプログラムを改良してもいい(オープンソース)。その中で、新しい便利な機能を追加しインターネットに公開されれば、良いコードは生き残り、悪いコードは自然淘汰されていく。
このオープンソースを支えているツールとしては、プログラムの変更履歴やバージョン管理を行う分散型バージョン管理システム git が有名であり、Linux のソフトウェア管理などで広く利用されている。。
オープンソースライセンス
バザール方式は、オープンソースライセンスにより成り立っていて、このライセンスが適用されていれば、改良した機能はインターネットに公開する義務を引き継ぐ。このライセンスの代表格が、GNU パブリックライセンス(GPL)であり、公開の義務の範囲により、BSD ライセンス、Apacheライセンスといった違いがある。
| コピーレフト型 | GNU ライセンス(GPL) | 改変したソースコードは公開義務, 組み合わせて利用で対応箇所の開示。 |
|
| 準コピーレフト型 | LGPL, Mozilla Public License | 改変したソースコードは公開義務。 | |
| 非コピーレフト型 | BSDライセンス, Apacheライセンス | ソースコードを改変しても必ずしもすべてを公開しなくてもいい。 |
GPLライセンスのソフトウェアを組み込んで製品を開発した場合に、ソースコード開示を行わないとGPL違反となる。大企業でこういったGPL違反が発生すると、大きな風評被害による損害をもたらす場合がある。
UMLと振る舞い図
前回の講義で説明した構造図に続いて、処理の流れを説明するための振る舞い図の説明。
講義の後半は、UML作成のレポートの課題時間とする。
振る舞い図
参考資料をもとに振る舞い図の説明を行う。
ユースケース図

ユーザなど外部からの要求に対する、システムの振る舞いを表現するための活用事例や機能を表す図がユースケース図。 システムを構築する際に、最初に記述するUMLであり、システムに対する処理要件の全体像や機能を理解するために記述する。 ユーザや外部のシステムは、アクターとよび人形の絵で示す。楕円でシステムに対する具体的な処理をユースケースとして楕円で記述する。 関連する複数のユースケースをまとめて、サブジェクトとして示す場合もある。
アクティビティ図

処理順序を記述するための図にはフローチャートがあるが、上から下に処理順序を記述するため、縦長の図になりやすい。また、四角枠の中に複雑なことを書けないので、UMLではアクティビティ図を用いる。
初期状態●から、終了状態◉までの手順を示すためのものがアクティビティ図。 フローチャートに無い表現として、複数の処理を並行処理する場合には、フォークノードで複数の処理を併記し、最終的に1つの処理になる部分をマージノードで示す。 通常の処理は、角丸の長方形で示し、条件分岐はひし形で示す。
ステートチャート図(状態遷移図)

ステートチャート図は、処理内部での状態遷移を示すための図。 1つの状態を長丸長方形で示し、初期状態●から終了状態◉までを結ぶ。 1つの状態から、なんらかの状態で他の状態に遷移する場合は、分岐条件となる契機(タイミング)とその条件、およびその効果(出力)を「契機[条件]/効果」で矢印に併記する。 複数の状態をグループ化して表す場合もある。
シーケンス図

複数のオブジェクトが相互にやり取りをしながら処理が進むようなもののタイミングを記述するためのものがシーケンス図。 上部の長方形にクラス/オブジェクトを示し、その下に縦軸にて時系列の処理の流れの線(Life Line)を描く。 オブジェクトがアクティブな状態は、縦長の長方形で示し、そのLife Line間を、やり取り(メッセージ)の線で相互に結ぶ。 メッセージは、相手側からの返答を待つような同期メッセージは、黒塗り三角矢印で示す。 返答を待たない非同期メッセージは矢印で示し、返答は破線で示す。
コミュニケーション図
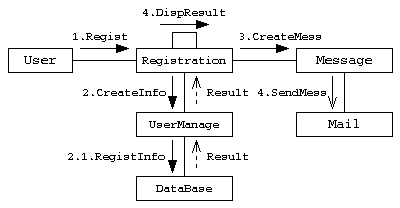
クラスやオブジェクトの間の処理とその応答(相互作用)と関連の両方を表現する図。
応答を待つ同期メッセージは -▶︎、非同期メッセージは→で表す。複数のオブジェクト間のやりとりの相互作用を表現する。
タイミング図
タイミング図は、クラスやオブジェクトの時間と共に状態がどのように遷移するのかを表現する図。
状態変化の発生するタイミングや、時間的な遅れや時間的な制約を図で明記するために使われる。
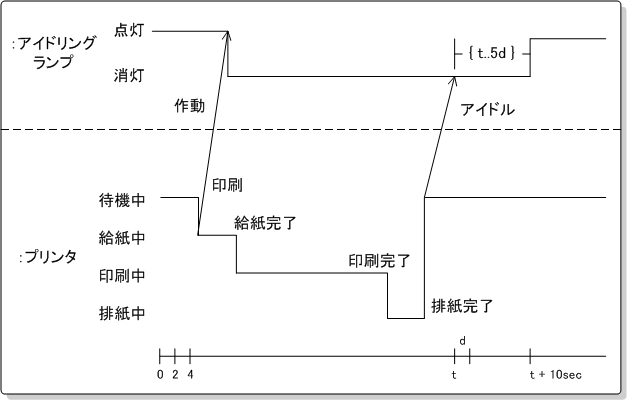
IT専科・UML入門より引用
UMLの概要と構造図
前回の授業でUMLの概要について説明を行ったが、専攻科の休講日だったようなので、UMLの概要をおさらいした後、UMLの構造図の説明を行う。
UML(Unified Modeling Language)記法が生まれるまで
巨大なプロジェクトでプログラムを作る場合、対象となるシステムを概念として表現する場合、オブジェクト指向分析(OOA: Object Oriented Analysis)やオブジェクト指向設計(OOD: Object Oriented Design)とよばれるソフトウェア開発方法が重要となる。(総称して OOAD – Object Oriented Analysis and Design)
これらの開発方法をとる場合、(1)自分自身で考えを整理したり、(2)グループで設計を検討したり、(3)ユーザに仕様を説明したりといった作業が行われる。この時に、自分自身あるいはチームメンバーあるいはクライアントに直感的に図を用いて説明する。この時の図の書き方を標準化したものが UML であり、(a)処理の流れを説明するための振る舞い図(以前であればフローチャートやPAD)と、(b)データ構造を説明するための構造図を用いる。
UMLは、ランボーによるOMT(Object Modeling Technique どちらかというとOOA中心)と、 ヤコブソンによるオブジェクト指向ソフトウェア工学(OOSE)を元に1990年頃に 発生し、ブーチのBooch法(どちらかというとOOD中心)の考えをまとめ、 UML(Unified Modeling Language)としてでてきた。
UMLでよく使われる図を列記すると、以下の物が挙げられる。
- 構造図
- クラス図
- コンポーネント図
- 配置図
- オブジェクト図
- パッケージ図
- 振る舞い図
- アクティビティ図
- ユースケース図
- ステートチャート図(状態遷移図)
- 相互作用図
- シーケンス図
- コミュニケーション図(コラボレーション図)
UMLを正しく使うことができるようになれば、UMLで仕様書を書けばそれがそのままプログラムになることが理想的な姿かもしれない。ソフトウェア開発やソフトウェアの保守にソフトウェアツールを利用することは、CASE(Computer Aided Software Engineering)と呼ばれ、そのようなツールをCASEツールと呼ぶ。地元福井の永和システムマネジメントでは、astar* というCASEツールを開発している。
UMLの構造図の書き方の説明。 詳しくは、参考ページのUML入門などが、分かりやすい。
クラス図
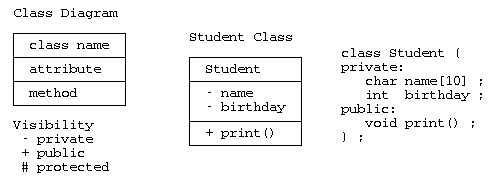
クラス図は、構造図の中の基本的な図で、 枠の中に、上段:クラス名、中段:属性(要素)、下段:メソッド(関数)を記載する。 属性やメソッドの可視性を示す場合は、”-“:private、”+”:public、”#”:protected 可視性に応じて、”+-#”などを記載する。
関連
クラスが他のクラスと関係がある場合には、その関係の意味に応じて、直線や矢印で結ぶ。
(a)関連(association):単純に関係がある場合、
(b)集約(aggregation):部品として持つが、弱い結びつき。関係先が消滅しても別に存在可能。(has-a)
(c)コンポジション(composition):部品として持つが強い結びつき。関係先と一緒に消滅。(has-a)
(d)依存(dependency):依存関係にあるだけ
(e)派生(generalization):派生・継承した関係(is-a)
(f)実現(realization): Javaでのinterfaceによる多重継承
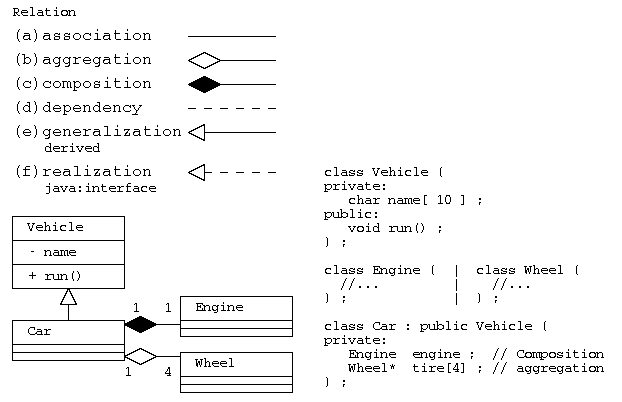
上図の例では、乗り物クラスVehicleから自動車Carが派生し(CarからVehicleへの三角矢印―▷)、 自動車は、エンジン(Engine)を部品として持つ(EngineからCarへのひし形矢印―◆)。エンジンは車体と一緒に廃棄なら、コンポジション(C++であれば部品の実体を持つ)で実装する。
自動車は、同じく車輪(Wheel)を4つ持つが、自動車を廃棄してもタイヤは別に使うかもしれないので、集約(部品への参照を持つ)で実装する(WheelからCarへのひし形矢印―◇)。 集約で実装する場合は、C++などであれば、ポインタで部品を持ち、部品の廃棄(delete)は、別に行うことになる。
Javaなどのプログラム言語では、オブジェクトはデータの実体へのポインタで扱われるため、コンポジションと集約を区別して表現することは少ない。
is-a 、has-a の関係
前の課題でのカモノハシクラスで、羽や足の情報をどう扱うべきかで、悩んだ場合と同じように、 クラスの設計を行う場合には、部品として持つのか、継承として機能を持つのか悩む場合がある。 この場合には、“is-a”の関係、“has-a”の関係で考えると、部品なのか継承なのか判断しやすい。
たとえば、上の乗り物(Vehicle)クラスと、車(Car)のクラスは、”Car is-a Vehicle” といえるので、is-a の関係。 “Car is-a Engine”と表現すると、おかしいことが判る。 車(Car)とエンジン(Engine)のクラスは、”Car has-a Engine”といえるので、has-a の関係となる。 このことから、CarはVehicleからの派生であり、Carの属性としてEngineを部品として持つ設計となる。
ER図
UMLではないが、オブジェクト図に近いものとしてER図がある。これはリレーショナルデータベースの設計が正しいか確認しながら設計するための図で、Entity(実体)とRelation(関連)を相互に線で結んだもので、最近のER図の書き方は、かなりクラス図の書き方に似ている。
オブジェクト図
クラス図だけで表現すると、複雑なクラス関係では、イメージが分かりづらい場合がでてくる。 この場合、具体的な値を図に書き込んだオブジェクトで表現すると、説明がしやすい場合がある。 このように具体的な値で記述するクラス図は、オブジェクト図と言う。 書き方としては、クラス名の下に下線を引き、中段の属性の所には具体的な値を書き込んで示す。
その他の構造図
パッケージ図
パッケージ図は、クラス図をパッケージ毎に分類して記載する図。 パッケージのグループを、フォルダのような図で記載する。

IT専科から引用
コンポーネント図とコンポジット構造図
コンポジット構造図は、クラスやコンポーネントの内部構造を示すもので、コンポーネント図は、複数のクラスで構成される処理に、 インタフェースを用意し、あたかも1つのクラスのように扱ったもの。 接続するインタフェースを飴玉と飴玉を受けるクチのイメージで、提供側を◯───で表し、要求側を⊃──で表す。
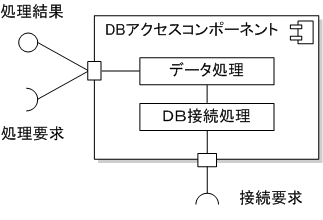
IT専科から引用
配置図
配置図は、システムのハードウェア構成や通信経路などを表現するための図。 ハードウェアは直方体の絵で表現し、 デバイスの説明は、”≪device≫”などを示し、実行環境には、”≪executionEnvironment≫” などの目印で表現する。
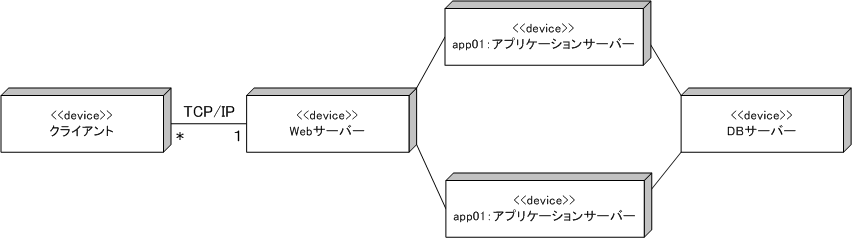
IT専科から引用
UMLの概要
巨大なプロジェクトでプログラムを作成する場合、設計の考え方を図で示すことは、直感的な理解となるため重要であり、このために UML がある。以下にその考え方と記述方法を説明していく。
プログラムの考え方の説明
今まで、プログラムを人に説明する場合には、初心者向けの方式としてフローチャートを使うのが一般的であろう。しかし、フローチャートは四角の枠の中に説明を書ききれないことがあり、使い勝手が悪い。他には、PAD と呼ばれる記述法もある。この方法は、一連の処理を表す縦棒の横に、処理を表す旗を並べるようなイメージで記載する。
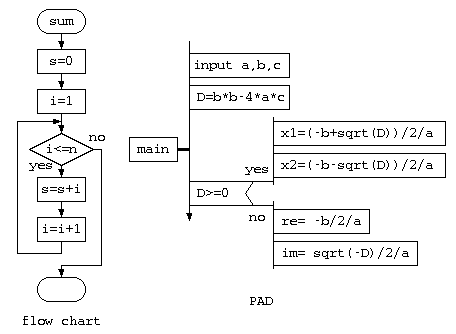
しかし、これらの記法は、手順を記載するためのものであり、オブジェクト指向のようなデータ構造を説明するための図が必要となってきた。
個人的な経験では、企業にてプログラムを作っていた頃(1990年頃)、UML などの考え方は普及していなかった。処理を説明するためのフローチャートでも、通信関係のプログラムでは、送信側と受信側の相互関係を説明する場合、フローチャートでは相互のタイミングなどの説明は困難であった。また、通信では、リトライ・タイムアウトといった状態も発生するが、その場合だと状態遷移図なども併記する必要があり、フローチャートの限界を感じていた。
また、データ構造については、オブジェクト指向も普及前であればデータ要素の一覧表が中心であった。プログラム書式(コーディングスタイル)などの統一もされていないので、同じチーム内で誤解などを解消するための意思統一が重要であった。
プログラムのドキュメント
学生のみなさんは、プログラムの説明の文書はどのように残しているだろうか?
私が仕事をしていた頃は、プログラムと別にドキュメントをワープロで残そうとすると、プログラム変更に合わせて編集することが難しく、プログラムとドキュメントの乖離が発生する。このため、プログラムの中にコメントの形で残すことが重要であった。特にデータ構造の説明は、ヘッダファイルの中に大量のコメントで残すことが多かった。
TeXを改発した Knuth は、文芸的プログラミングとして、プログラム中にドキュメントを併記するための WEB を同時に開発している。このシステムでは、プログラムとドキュメントを併記したソースプログラムから、ドキュメントを取り出すプログラムと、ソースコードを取り出すプログラムがあり、情報の一体性を高めている。
最近では、プログラムのエディタで Markdown という、マークアップ言語でドキュメントを残す場合も多いだろう。これであれば、プレーンテキストで書いたドキュメントを、HTMLやLaTeXといった読みやすいドキュメントに変換も容易である。
UML記法が生まれるまで
巨大なプロジェクトでプログラムを作る場合、対象となるシステムを表現する場合、オブジェクト指向分析(Object Oriented Analysis)やオブジェクト指向設計(Object Oriented Design)とよばれるソフトウェア開発方法が重要となる。(総称して OOAD – Object Oriented Analysis and Design)
これらの開発方法をとる場合、(1)自分自身で考えを整理したり、(2)グループで設計を検討したり、(3)ユーザに仕様を説明したりといった作業が行われる。この時に、自分自身あるいはチームメンバーあるいはクライアントに直感的に図を用いて説明する。この時の図の書き方を標準化したものが UML であり、(a)処理の流れを説明するための振る舞い図(フローチャートやPAD)と、(b)データ構造を説明するための構造図を用いる。
UMLは、ランボーによるOMT(Object Modeling Technique どちらかというとOOA中心)と、 ヤコブソンによるオブジェクト指向ソフトウェア工学(OOSE)を元に1990年頃に 発生し、ブーチのBooch法(どちらかというとOOD中心)の考えをまとめ、 UML(Unified Modeling Language)としてでてきた。
UMLでよく使われる図を列記すると、以下の物が挙げられる。
- 構造図
- クラス図
- コンポーネント図
- 配置図
- オブジェクト図
- パッケージ図
- 振る舞い図
- アクティビティ図
- ユースケース図
- ステートチャート図(状態遷移図)
- 相互作用図
- シーケンス図
- コミュニケーション図(コラボレーション図)
その他の関連雑談のためのリンク
- CASE(Computer Aided Software Engineering) – ソフトウェア設計の GUI
- astar* – ソフトウェア設計ツール(永和システムマネジメント)
- 中国・インド・フィリピンにソフトウェア開発をアウトソーシングして分かったこと
- Git – 分散型バージョン管理システム
派生や集約と多重継承
派生や継承について、一通りの説明が終わったので、データ構造(クラスの構造)の定義の方法にも様々な考え方があり、どのように実装すべきかの問題点を考えるための説明を行う。その中で特殊な継承の問題についても解説する。
動物・鳥類・哺乳類クラス
派生や継承を使うと、親子関係のあるデータ構造をうまく表現できることを、ここまでの授業で示してきた。
しかしながら、以下に述べるような例では、問題が発生する。
// 動物クラス
class Animal {
private:
char name[ 10 ] ;
public:
Animal( const char s[] ) {
strcpy( name , s ) ;
}
const char* get_name() const { return name ; }
virtual void move() = 0 ;
virtual void birth() = 0 ;
} ;
// 鳥類クラス
class Bird : public Animal {
public:
Bird( const char s[] ) : Animal( s ) {}
virtual void move() {
printf( "%s fry.\n" , get_name() ) ;
}
virtual void birth() {
printf( "%s lay egg.\n" , get_name() ) ;
}
} ;
// 哺乳類クラス
class Mammal : public Animal {
public:
Mammal( const char s[] ) : Animal( s ) {}
virtual void move() {
printf( "%s walk.\n" , get_name() ) ;
}
virtual void birth() {
printf( "%s lay baby.\n" , get_name() ) ;
}
} ;
int main() {
Bird chiken( "piyo" ) ;
chiken.move() ;
chiken.birth() ;
Mammal cat( "tama" ) ;
cat.move() ;
cat.birth() ;
return 0 ;
}
ここで、カモノハシを作るのであれば、どうすれば良いだろうか?
鳥類・哺乳類とは別にカモノハシを作る(いちばん無難な方法)
class SeaBream : public Animal {
public:
Mammal( const char s[] ) : Animal( s ) {}
virtual void move() {
printf( "%s walk.\n" , get_name() ) ;
}
virtual void birth() {
printf( "%s lay egg.\n" , get_name() ) ;
}
} ;
この例では、簡単な処理だが、move() の中身が複雑であれば、改めて move() を宣言するのではなく、継承するだけの書き方ができないだろうか?
多重継承を使う方法(ダイヤモンド型継承が発生する)
C++ には、複数のクラスから、派生する多重継承という機能がある。であれば、鳥類と哺乳類から進化したのだから、以下のように書きたい。
// 多重継承 鳥(Bird)と哺乳類(Mammal) から SeaBeam を作る
class SeaBream : public Bird , public Mammal {
//
} ;
しかし、カモノハシに move() を呼び出すと、鳥類の move() と哺乳類の move() のどちらを動かすか曖昧になる。
また「派生」は、基底クラスと派生クラスの両方のデータを持つデータ構造を作る。このため、単純に多重継承を行うと、カモノハシのクラスでは、派生クラスは親クラスのデータ領域と、派生クラスのデータ領域を持つため、鳥類の name[] と、哺乳類の name[] を二つ持つことになる。多重継承による”ダイヤモンド型継承”の問題
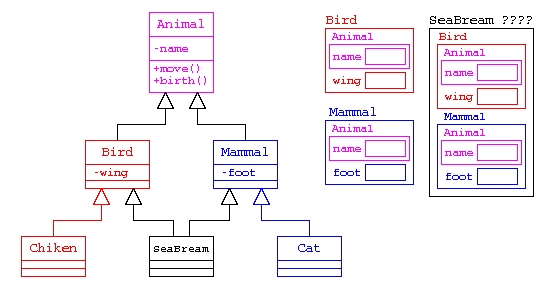
足と羽のクラスを作る場合(本来は多重継承で実装すべきではない)
以下に、足と羽のクラスを作ったうえで、多重継承を行うプログラム例を示す。
しかし、この例では、相変わらずカモノハシのクラスを多重継承で実装すると、ダイヤモンド型継承の問題が残る。
class Animal {
private:
char name[ 10 ] ;
public:
Animal( const char s[] ) {
strcpy( name , s ) ;
}
const char* get_name() const { return name ; }
virtual void move() = 0 ;
} ;
// 羽
class Wing {
public:
const char* move_method() { return "fly" ; }
} ;
//
class Leg {
public:
const char* move_method() { return "walk" ; }
} ;
class Bird : public Animal , public Wind {
public:
Bird( const char s[] ) : Animal( s ) {}
virtual void move() {
printf( "%s %s.\n" , get_name() , move_method() ) ;
}
} ;
class Mammal : public Animal , public Leg {
public:
Mammal( const char s[] ) : Animal( s ) {}
virtual void move() {
printf( "%s %s.\n" , get_name() , move_method() ) ;
}
} ;
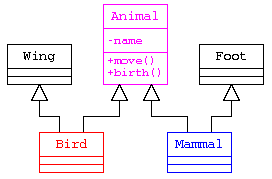
継承を使うべきか、部品として持つべきか
ただし、ここで述べた方式は、UML による設計の際に改めて説明を行うが、is-a , has-a の関係でいうなら、
- Bird is a Animal. – 鳥は動物である。
- “Bird has a Animal” はおかしい。
- 鳥は、動物から派生させるのが正しい。
- Bird has a Wing. – 鳥は羽をもつ。
- “Bird is a Wing” はおかしい。
- 鳥は、羽を部品として持つべき。
であることから、Wing は 継承で実装するのではなく、集約もしくはコンポジションのような部品として実装すべきである。
このカモノハシ問題をどうしても多重継承で実装したいのなら、C++では、以下のような方法で、ダイヤモンド型の継承問題を解決できる。
class Animal {
private:
char name[ 10 ] ;
public:
Animal( const char s[] ) {
strcpy( name , s ) ;
}
const char* get_name() const { return name ; }
virtual void move() = 0 ;
virtual void birth() = 0 ;
} ;
// 鳥類クラス
class Bird : public virtual Animal {
public:
Bird( const char s[] ) : Animal( s ) {}
virtual void move() {
printf( "%s fry.\n" , get_name() ) ;
}
virtual void birth() {
printf( "%s lay egg.\n" , get_name() ) ;
}
} ;
// 哺乳類クラス
class Mammal : public virtual Animal {
public:
Mammal( const char s[] ) : Animal( s ) {}
virtual void move() {
printf( "%s walk.\n" , get_name() ) ;
}
virtual void birth() {
printf( "%s lay baby.\n" , get_name() ) ;
}
} ;
class SeaBream : public virtual Bird , virtual Mammal {
public:
SeaBream( const char s[] ) : Animal( s ) {}
void move() {
Mammal::move() ;
}
void birth() {
Bird::birth() ;
}
} ;
ただし、多重継承は親クラスの情報と、メソッドを継承する。この場合、通常だと name[] を二つ持つことになるので、問題が発生する。そこで、親クラスの継承に virtual を指定することで、ダイヤモンド型継承の 2つの属性をうまく処理してくれるようになる。
しかし、多重継承は処理の曖昧さや効率の悪さもあることから、採用されていないオブジェクト指向言語も多い。特に Java は、多重継承を使えない。その代わりに interface という機能が使えるようになっている。
多重継承を使える CLOS や Python では、適用するメソッドやインスタンス変数の曖昧さについては親クラスへの優先度を明確にできる機能がある。曖昧さの問題を避けるのであればクラス限定子”::”を使うべきである。