リスト構造
リスト構造は、データと次のデータへのポインタで構成され、必要に応じてメモリを確保することで、配列の上限が制限にならないようにする。また、次のデータへのポインタでつなげているため、途中へのデータ挿入が簡単にできるようにする。
まずは、メモリ確保とポインタをつなげるイメージを確実に理解してもらうために、1つ1つのデータをポインタでつなげる処理を示す。
#include <stdio.h>
#include <stdlib.h>
// List構造の宣言
struct List {
int data ; // データ保存部
struct List* next ; // 次のデータへのポインタ
} ;
int main() {
struct List* top ; // データの先頭
struct List* p ;
// (1)
top = (struct List*)malloc( sizeof( struct List ) ) ;
top->data = 111 ;
// (2)
top->next = (struct List*)malloc( sizeof( struct List ) ) ;
top->next->data = 222 ;
// (3)
top->next->next = (struct List*)malloc( sizeof( struct List ) ) ;
top->next->next->data = 333 ;
top->next->next->next = NULL ; // 末尾データの目印
for( p = top ; p != NULL ; p = p->next ) {
printf( "%d¥n" , p->data ) ;
}
return 0 ;
}
 このようなメモリーの中のポインタの指し示す番地のイメージを、具体的な番地の数字を書いてみると、以下のような図で表せる。先頭の111が入った部分が1000番地であったなら、topというポインタには1000番地が入っている。
このようなメモリーの中のポインタの指し示す番地のイメージを、具体的な番地の数字を書いてみると、以下のような図で表せる。先頭の111が入った部分が1000番地であったなら、topというポインタには1000番地が入っている。
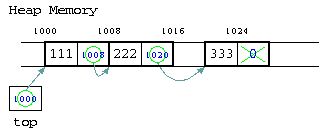
NULLって何?
前回の授業で説明した、次の配列の添え字の番号を使う方式では、データの末尾を示すためには、-1 を使った。-1 は、配列の添え字で通常ありえない値であり、次のデータはないという目印とした。
同じように、C言語では、通常あり得ないポインタとして、0 番地を示す NULL が定義されている。
#define NULL 0
補助関数
上記のプログラムでは、(struct…)malloc(sizeof(…))を何度も記載し、プログラムが分かりにくいので、以下に示す補助関数を使うと、シンプルに記載できる。
struct List* cons( int x , struct List* n ) {
struct List* ans ;
ans = (struct List*)malloc( sizeof( struct List ) ) ;
if ( ans != NULL ) {
ans->data = x ;
ans->next = n ;
}
return ans ;
}
int main() {
struct List* top ;
top = cons( 111 , cons( 222 , cons( 333 , NULL ) ) ) ;
:
return 0 ;
}
補助関数の名前の cons は、constructor の略であり、古くから使われている List Processor(LISP)※ というプログラム言語でのリスト(セル)を生成する関数が cons 。
typedefを使った書き方
List構造の宣言は、古い書き方では typedef を使うことも多い。typedef は、型宣言において新しい型の名前をつける命令。
// typedef の使い方 // typedef 型宣言 型名 ; typedef unsigned int uint32 ; // 符号なし32bit整数をシンプルに書きたい uint32 x = 12345 ; typedef struct LIST { // 構造体のタグ名と新しくつける型名と重複できない int data ; // のでこの時点のタグ名は "LIST" としておく struct LIST* next ; } List ; List* cons( int x , List* n ) { // C++なら struct List { ... } ; と書く List* ans ; // だけでこういう表記が可能 ans = (List*)malloc( sizeof( List ) ) ; : ((略)) } int main() { List* top ; top = cons( 111 , cons( 222 , cons( 333 , NULL ) ) ) ; : ((略)) }最近のC言語(C++)では、構造体のタグ名がそのまま型名として使えるので、こういう書き方をする必要はなくなってきている。
// 最近のC++なら... struct List { public: int data ; List* next ; public: List( int x , List* n ) : data( x ) , next( n ) {} } ; int main() { List* top = new List( 1 , new List( 2 , new List( 3 , NULL ) ) ) ; : }LISP※と関数型プログラミング言語
LISPの歴史は長く、最古のFORTRAN,COBOLに次ぐ3番目ぐらいに遡る。最初は、人工知能※※(AI)のプログラム開発のための関数型プログラミング言語として作られた。特徴として、データもプログラムもすべてリスト構造(S式)で表すことができ、プログラムは関数型に基づいて作られる。
関数型プログラミングは、Ruby や Python でも取り入れられている。関数型プログラミングは、処理を関数をベースに記述することで「副作用を最小限にすることができ」、極端な話をすればループも再帰呼出しの関数で書けばいい…。
LISPの処理系は、最近では Scheme などが普通だが、プログラムエディタの Emacs は、内部処理が LISP で記述されている。
古いAI※※と最近のAIの違い
最近では、AI(Artificial Intelligence) という言葉が復活してきたが、LISP が開発された頃の AI と最近注目されている AI は、微妙に異なる点がある。
LISPが開発された頃の AI は、関数型のプログラム言語で論理的思考を表現することが目標であった。頭脳を左脳と右脳の違いで表現することが多いが、どちらかというと「分析的で論理的に優れ、言語力や計算機能が高い」とされる左脳を作り出すようなもの。しかしながら、この時代では、漠然としたパターンを認識したりするような「感覚的、直感的な能力に優れ総合判断力を司る右脳」のような処理は苦手であった。
しかしながら、最近注目されている AI は、脳神経を真似たニューラルネットワークから発展した機械学習やディープラーニングという技法により今まで難しかった右脳の機能を実現することで、左脳と右脳の機能を兼ね備えたものとなっている。
将棋のプログラミングで例えるなら、左脳(古いAI)に例えられるのが正確に先の手を読む機能であり、右脳に例えられる機能が大局観(全体の良し悪しを見極める判断能力)といえる。
簡単なリスト処理の例
先に示したリスト構造について簡単なプログラム作成を通して、プログラミングに慣れてみよう。
// 全要素を表示する関数
void print( struct List* p ) {
for( ; p != NULL ; p = p->next )
printf( "%d " , p->data ) ;
printf( "¥n" ) ;
}
// データ数を返す関数
int count( struct List* p ) {
int c = 0 ;
for( ; p != NULL ; p = p->next )
c++ ;
return c ;
}
int main() {
struct List* top = cons( 111 , cons( 444 , cons( 333 , NULL ) ) ) ;
print( top ) ;
printf( "%d¥n" , count( top ) ) ;
return 0 ;
}
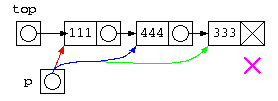
リスト処理を自分で考えて作成
以下のようなプログラムを作ってみよう。意味がわかって慣れてくれば、配列の部分の for の回し方が変わっただけということに慣れてくるだろう。
// 全要素の合計
int sum( struct List* p ) {
// sum( top ) → 888
自分で考えよう
}
// リストの最大値を返す
int max( struct List* p ) {
// max( top ) → 444 (データ件数0の場合0を返す)
自分で考えよう
}
// リストの平均値を返す
double mean( struct List* p ) {
// (111+444+333)/3=296.0
自分で考えよう
}
// リストの中から指定した値の場所を返す
int find( struct List* p , int key ) {
// find( top , 444 ) = 1 (先頭0番目)
// 見つからなかったら -1
自分で考えよう
}
再帰呼び出しでリスト処理
リスト処理の応用のプログラムを作るなかで、2分木などのプログラミングでは、リスト処理で再帰呼出しを使うことも多いので、先に示したプログラムを再帰呼び出しで書いたらどうなるであろうか?
// 全データを表示
void print( struct List* p ) {
if ( p == NULL ) {
printf( "¥n" ) ;
} else {
printf( "%d " , p->data ) ;
print( p->next ) ; // 末尾再帰
}
}
// データ数を返す関数
int count( struct List* p ) {
if ( p == NULL )
return 0 ;
else
return 1 + count( p->next ) ; // 末尾再帰
}
// 全要素の合計
int sum( struct List* p ) {
// sum( top ) → 888
自分で考えよう
}
// リストの最大値を返す
int max( struct List* p ) {
// max( top ) → 444 (データ件数0の場合0を返す)
自分で考えよう
}
// リストの中から指定した値を探す。
int find( struct List* p , int key ) {
// find( top , 444 ) = 1
// 見つかったら1 , 見つからなかったら 0
自分で考えよう
}
理解度確認
上記プログラム中の sum() , max() , find() を再帰呼び出しをつかって記述せよ。