データが登録済みかどうかを判定する処理を作るために、登録された値を配列に次々と値を追加保存する場合、どのようにプログラムを記述するだろうか?
配列にデータを追加
次々と与えられた値を保存していくのであれば、Java であれば下記のようなコードが一般的であろう。
でも、ArrayList とはどのようにデータを覚えているのだろうか? なぜ 宣言は ArrayList<Integer> array であって ArrayList<int> array で宣言するとエラーが出るのであろうか?
import java.util.*;
public class Main {
public static void main(String[] args) throws Exception {
// ArrayList は連続アドレス空間に保存してくれる可変長配列
// ランダムアクセスをする場合に向いている
ArrayList<Integer> array = new ArrayList<Integer>() ;
array.add( 11 ) ;
array.add( 2 ) ;
array.add( 333 ) ;
for( Integer i : array ) {
System.out.println( i ) ;
}
}
}
このような ArrayList のようなデータ構造の仕組みを考えるために、最も単純な配列でプログラムを作ってみる。
末尾に追加
import java.util.*;
public class Main {
static int[] array = new int[ 10 ] ;
static int size = 0 ;
public static void add( int x ) {
array[ size ] = x ;
size++ ;
}
public static void main(String[] args) throws Exception {
add( 11 ) ;
add( 2 ) ;
add( 333 ) ;
for( int i = 0 ; i < size ; i++ )
System.out.println( array[i] ) ;
}
}
同じ処理をC言語で書いてみる。
#include <stdio.h>
int array[ 10 ] ;
int size = 0 ;
void add( int x ) { // if ( size < array.length ) ... の判定が必要かも
array[ size ] = x ;
size++ ;
}
int main() {
add( 11 ) ;
add( 2 ) ;
add( 333 ) ;
for( int i = 0 ; i < size ; i++ )
printf( "%d\n" , array[ i ] ) ;
return 0 ;
}
しかし、このプログラムでは、最初に宣言した要素数10個を越えてデータを保存できないし、配列溢れさせないためには要素数の上限チェックも必要となるだろう。
昇順に並べながら途中に要素を追加
前述のプログラムでは、配列の末尾の場所を size で覚えておき、末尾にデータを追加していた。でも、配列に保存されている値の中から目的の値が含まれているか検索したいのであれば、配列に要素を昇順に保存しておいて2分探索法を使うのが一般的であろう。では、前述のプログラムを昇順で保存するにはどうすべきか?
最も簡単な方法で書くのであれば、下記のようなコードになるかもしれない。
public static void add( int x ) {
int i ;
for( i = 0 ; i < size ; i++ ) { // ここは2分探索で書けば O( log N ) にできるかも
if ( array[ i ] > x )
break ;
}
// for( int j = i ; j < size ; j++ ) // 途中に挿入は、コレじゃダメ?
// array[ j + 1 ] = array[ j ] ;
for( int j = size - 1 ; j >= i ; j-- ) // 途中にデータを入れるために要素を1つ後ろに移動
array[ j + 1 ] = array[ j ] ;
array[ i ] = x ;
size++ ;
}
void add( int x ) {
int i ;
for( i = 0 ; i < size ; i++ ) {
if ( array[ i ] > x )
break ;
}
// for( int j = i ; j < size ; j++ )
// array[ j + 1 ] = array[ j ] ;
for( int j = size - 1 ; j >= i ; j-- )
array[ j + 1 ] = array[ j ] ;
array[ i ] = x ;
size++ ;
}
このプログラムでは、for( i … ) の処理でデータを挿入すべき場所を見つけ、for( int j … ) の繰り返しでデータを1つ後ろにずらしてから要素を加えている。
for( i … ) の処理は、このプログラムでは O( N ) となっているが、2分探索法を用いれば O( log N ) に改善ができるかもしれない。しかし、for( int j… ) の処理は、データを1つ後ろにずらす必要があるため O( N ) の処理が必要となる。
ここで、途中にデータを追加する処理の効率を改善することを考える。
リスト構造の導入
以下のデータ構造では、配列にデータと次のデータの場所を覚えることで、一見デタラメな順序に保存されているようにみえるが、next[] に次の値の保存されている場所が入っている。
import java.util.*;
public class Main { // 0 1 2 3 4 5
static int[] data = new int[] { 11 , 55 , 22 , 44 , 33 , 0 , 0 , 0 , 0 , 0 } ;
static int[] next = new int[] { 2 , -1 , 4 , 1 , 3 , 0 , 0 , 0 , 0 , 0 } ;
static int size = 5 ;
static int top = 0 ;
static void insert( int n , int x ) {
data[ size ] = x ;
next[ size ] = next[ n ] ;
next[ n ] = size ;
size++ ;
}
public static void main(String[] args) throws Exception {
for( int idx = top ; idx >= 0 ; idx = next[ idx ] )
System.out.println( data[ idx ] ) ;
insert( 2 , 25 ) ;
for( int idx = top ; idx >= 0 ; idx = next[ idx ] )
System.out.println( data[ idx ] ) ;
}
}
#include <stdio.h>
int data[ 10 ] = { 11 , 55 , 22 , 44 , 33 , 0 , 0 , 0 , 0 , 0 } ;
int next[ 10 ] = { 2 , -1 , 4 , 1 , 3 , 0 , 0 , 0 , 0 , 0 } ;
int size = 5 ;
int top = 0 ;
void insert( int n , int x ) {
data[ size ] = x ;
next[ size ] = next[ n ] ;
next[ n ] = size ;
size++ ;
}
int main() {
for( int idx = top ; idx >= 0 ; idx = next[ idx ] )
printf( "%d\n" , data[ idx ] ) ;
insert( 2 , 25 ) ;
for( int idx = top ; idx >= 0 ; idx = next[ idx ] )
printf( "%d\n" , data[ idx ] ) ;
return 0 ;
}
このようなデータ構造であれば、データ自体は末尾に保存しているが、次の値が入っている場所を修正することで途中にデータを挿入することができる。この方法であれば、途中にデータを入れる場合でもデータを後ろにずらすような処理が不要であり、O(1)で途中にデータを挿入できる。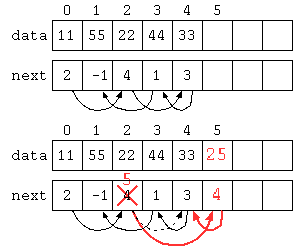
このプログラムでは、配列の当初の長さを超えてデータを格納することはできない。
リスト構造 ListNode
前述の data と next で次々とデータを続けて保存するために、リスト構造(連結リスト)を定義する。
import java.util.*;
class ListNode {
int data ;
ListNode next ;
ListNode( int d , ListNode nx ) {
this.data = d ;
this.next = nx ;
}
} ;
public class Main {
public static void main(String[] args) throws Exception {
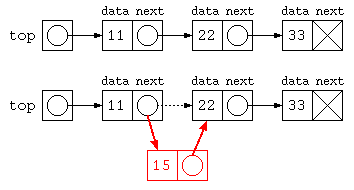
ListNode top = new ListNode( 11 , new ListNode( 22 , new ListNode( 33 , null ) ) ) ;
for( ListNode p = top ; p != null ; p = p.next )
System.out.println( p.data ) ;
top.next = new ListNode( 15 , top.next ) ;
for( ListNode p = top ; p != null ; p = p.next )
System.out.println( p.data ) ;
}
}
#include <stdio.h>
#include <stdlib.h>
struct ListNode {
int data ;
ListNode* next ;
} ;
ListNode* newListNode( int d , ListNode* nx ) {
ListNode* _this = new ListNode() ;
if ( _this != NULL ) {
_this->data = d ;
_this->next = nx ;
}
return _this ;
}
int main() {
ListNode* top = newListNode( 11 , newListNode( 22 , newListNode( 33 , NULL ) ) ) ;
for( ListNode* p = top ; p != NULL ; p = p->next )
printf( "%d\n" , p->data ) ;
top->next = newListNode( 15 , top->next ) ;
for( ListNode* p = top ; p != NULL ; p = p->next )
printf( "%d\n" , p->data ) ;
return 0 ;
}
Javaのジェネリクス
Javaのジェネリクス(C++のテンプレート)を使って書いてみた。ジェネリクスは、クラスやメソッドにおいて、特定の型を指定することなく動作するコードを記述することができる機能。これにより、型安全性を保ちながら、コードの再利用性と柔軟性を向上させることがでる。
import java.util.*; class ListNode<T> { T data ; ListNode<T> next ; ListNode( T d , ListNode<T> n ) { this.data = d ; this.next = n ; } } ; public class Main { public static void main(String[] args) throws Exception { // var 宣言は型推論で、右辺のデータ型を自動的に選択してくれる。 // itop は整数型のリスト var itop = new ListNode<Integer>( 11 , new ListNode<Integer>( 22 , new ListNode<Integer>( 33 , null ) ) ) ; // new List<int>( 11 , ... ) と書くと、<>の中は reference しか使えないと言われる。 for( var p = itop ; p != null ; p = p.next ) System.out.println( p.data ) ; // stop は文字列型のリスト var stop = new ListNode<String>( "aa" , new ListNode<String>( "bb" , new ListNode<String>( "cc" , null ) ) ) ; for( var p = stop ; p != null ; p = p.next ) System.out.println( p.data ) ; } }前述のプログラムをJavaのジェネリッククラスで記述
import java.util.*; public class Main { public static void main(String[] args) throws Exception { // LinkedList は上記のリスト構造で保存される。 // 途中に要素の追加削除を行ったり、シーケンシャルアクセスに向いたデータ構造 var top = new LinkedList<Integer>() ; top.add( 11 ) ; top.add( 22 ) ; top.add( 33 ) ; for( int i : top ) // 11 22 33 System.out.println( i ) ; top.add( 1 , 15 ) ; for( int i : top ) // 11 15 22 33 System.out.println( i ) ; } }
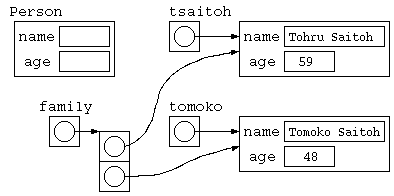
クラスの宣言とコンストラクタ・メソッド
import java.util.*;
// クラス宣言
class Person {
// データ構造
String name ;
int age ;
// コンストラクタ(データ構造を初期化する関数)
Person( String n , int x ) {
this.name = n ; // this は対象となるデータそのものを指す
this.age = x ; // 対象が明言されていれば、this は省略可能
}
// データを扱うメソッド
void print() { // データを表示
System.out.println( this.name + "," + this.age ) ;
}
boolean sameAge( Person x ) { // 同じ年齢か判断するメソッド
return this.age == x.age ;
}
} ;
public class Main {
public static void main(String[] args) throws Exception {
Person tsaitoh = new Person( "Tohru Saitoh" , 59 ) ;
Person tomoko = new Person( "Tomoko Saitoh" , 48 ) ;
tsaitoh.print() ; // Tohru Saitoh, 59
tomoko.print() ; // Tomoko Saitoh,48
if ( tsaitoh.sameAge( tomoko ) ) {
// sameAge( Person x ) では、
// this = tsaitoh , x = tomoko となって呼び出される
System.out.println( "同じ年齢ですよ" ) ;
}
Person[] family = new Person[ 2 ] ;
family[0] = tsaitoh ;
family[1] = tomoko ;
for( int i = 0 ; i < 2 ; i++ )
family[ i ].print() ;
}
}こ
このプログラムのデータ構造は下記のような状態。