インターネットの情報量
インターネット上の情報量の話として、2010年度に281EB(エクサバイト)=281✕1018B(参考:kMGTPEZY)で、2013年度で、1.2 ZB(ゼタバイト)=1.2✕1021B という情報があった。ムーアの法則の「2年で2倍」の概算にも、それなりに近い。 では、今年2023年であれば、どのくらいであろうか?
- ムーアの法則でいけば、281EB(2010年)×213/2=25ZB(2023年)だけど
- 大塚商会の2016年度における2020年度の予測では…
- アメリカのIDCの2020/5月の発表では、59ZB!? — 165ZB??
しかし、これらの情報をGoogleなどで探す場合、すぐにそれなりに情報を みつけてくれる。これらは、どの様に実装されているのか?
Webシステムとデータベース
まず、指定したキーワードの情報を見つけてくれるものとして、 検索システムがあるが、このデータベースはどのようにできているのか?
Web創成期の頃であれば、Yahooがディレクトリ型の検索システムを構築してくれている。(ページ作者がキーワードとURLを登録する方式) しかし、ディレクトリ型では、自分が考えたキーワードではページが 見つからないことが多い。
そこで、GoogleはWebロボット(クローラー)による検索システムを構築した。 Webロボットは、定期的に登録されているURLをアクセスし、 そのページ内の単語を分割しURLと共にデータベースに追加する。 さらに、ページ内にURLが含まれていると、そのURLの先で、 同様の処理を再帰的に繰り返す。
これにより、巨大なデータベースが構築されているが、これを普通のコンピュータで実現すると、処理速度が足りず、3秒ルール or 5秒ルール (Web利用者は次のページ表示が3秒を越えると、次に閲覧してくれない)を実現するための能力が不足してしまう。だからこそ、これらを処理するには負荷分散が重要となる。
Webシステムの負荷分散
一般的に、Webシステムを構築する場合には、 1段:Webサーバ、2段:動的ページ言語、3段:データベースとなる場合も 多い。この場合、OS=Linux,Web=Apache,DB=MySQL,動的ページ生成言語=PHPの組合せによる、 LAMP構成とする場合も多い。
OS = Linux
[ Webサーバ 動的Web言語 データベース ]
User - - - - - Apache ----- PHP ----- MySQL
一方で、大量のデータを処理するDBでは、フロントエンド,セカンダリDB(スレーブDB),プライマリDB(マスタDB)のWebシステムの3段スキーマ構成となることも多い。
フロントエンドは、大量のWebユーザからの問合せを受ける部分であり、必要に応じてセカンダリDBに問合せを行う。
大量のユーザからの問合せを1台のデータベースシステムで捌くには処理の負荷が高い場合、複数のデータベースで負荷分散を行う。プライマリDBは、複数のデータベースシステムの原本となるべきデータを保存される。負荷分散の為に分散されたセカンダリDBは、プライマリDBと内容の同期をとりながらフロントエンドからの問合せに応答する。
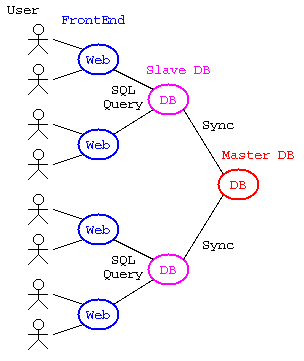
データベースシステム
データベースには、ファイル内のデータを扱うためのライブラリの BerkleyDB といった場合もあるが、複雑なデータの問い合わせを実現する 場合には、リレーショナル・データベース(RDB)を用いる。 RDBでは、データをすべて表形式であらわし、SQLというデータベース 問い合わせ言語でデータを扱う。 また、問い合わせは、ネットワーク越しに実現可能であり、こういった RDBで有名なものとして、Oracle , MySQL , PostgreSQL などがある。 単一コンピュータ内でのデータベースには、SQLite などがある。
リレーショナルデータベースの串刺し
|
このような表データでは、たとえば「みかん」の単価が変更になると、2行目,4行目を変更しなければいけなくなる。巨大な表の場合、これらの変更は大変。
そこで、この表を2つに分類する。
|
|
||||||||||||||||||||||||||||
必要に応じて、2つの表から、以下のような SQL の命令で、データを抽出する。
select 単価表.商品名, 単価表.単価, 販売表.個数, 単価表.単価*販売表.個数 from 単価表, 販売表 ; |
|||||||||||||||||||||||||||||
データベースに求められるのACID特性
データベースシステムと呼ばれるには、ACID特性が重要となる。(次に述べるデータベースが無かったら…を参照)
- A: 原子性 (Atomicity) – 処理はすべて実行するか / しない のどちらか。
- C: 一貫性 (Consistency) – 整合性とも呼ばれ、与えられたデータのルールを常に満たすこと。
- I: 独立性 (Isolation) – 処理順序が違っても結果が変わらない。それぞれの処理が独立している。
- D: 永続性 (Durability) – データが失われることがない(故障でデータが無くならないとか)
しかし、RDBでは複雑なデータの問い合わせはできるが、 大量のデータ処理のシステムでは、フロントエンド,セカンダリDB,プライマリDB の同期が問題となる。この複雑さへの対応として、最近は NoSQL(RDB以外のDB) が 注目されている。(例: Google の BigTable)
データベースが無かったら
これらのデータベースが無かったら、どのようなプログラムを作る 必要があるのか?
情報構造論ではC言語でデータベースっぽいことをしていたが、 大量のデータを永続的に扱うのであれば、ファイルへのデータの読み書き 修正ができるプログラムが必要となる。
こういったデータをファイルで扱う場合には、1件のデータ長が途中で 変化すると、N番目のデータは何処?といった現象が発生する。 このため、簡単なデータベースを自力で書くには、1件あたりのデータ量を 固定し、lseek() , fwrite() , fread() などの 関数でランダムアクセスのプログラムを書く必要がある。
また、データの読み書きが複数同時発生する場合には、排他処理(独立性)も 重要となる。例えば、銀行での預け金10万の時、3万入金と、2万引落としが 同時に発生したらどうなるか? 最悪なケースでは、 (1)入金処理で、残金10万を読み出し、 (2)引落し処理で、残金10万を読み出し、 (3)入金処理で10万に+3万で、13万円を書き込み、 (4)引落し処理で、残金10万-2万で、8万円を書き込み。 で、本来なら11万になるべき結果が、8万になるかもしれない。

さらに、コンピュータといってもハードディスクの故障などは発生する。 障害が発生してもデータの原子性や永続性を保つためには、バックアップや 障害対応が重要となる。