前回説明した仮想関数では、基底クラスから派生させたクラスを作り、そのデータが混在してもクラスに応じた関数(仮想関数)を呼び出すことができる。
この仮想関数の機能を逆手にとったプログラムの記述方法として、抽象クラス(純粋仮想基底クラス)がある。その使い方を説明する。
JavaのGUIにおける派生の使い方
先週の講義では、派生を使ったプログラミングは、GUI で使われていることを紹介したが、例として Java のプログラミングスタイルを少し紹介する。
例えば、Java で アプレット(ブラウザの中で動かすJavaプログラム)を作る場合の、最小のサンプルプログラムは、以下のようになる。
import java.applet.Applet; // C言語でいうところの、Applet 関連の処理を include import java.awt.Graphics; public class App1 extends Applet { // Applet クラスから、App1 クラスを派生 public void paint(Graphics g) { // 画面にApp1を表示する必要がある時に呼び出される。 g.drawString("Hello World." , 100 , 100); } }
この例では、ブラウザのGUIを管理する Applet クラスから、App1 というクラスを派生(extendsキーワード)し、App1 固有の処理として、paint() メソッドを定義している。GUI のプログラミングでは、本来ならマウスが押された場合の処理などを記述する必要があるが、このプログラムでは paint() 以外何も書かれていない。これはマウス処理などは、基底クラスのAppletのマウス処理が継承されるので、省略してもうまく動くようになっている。
純粋仮想基底クラス
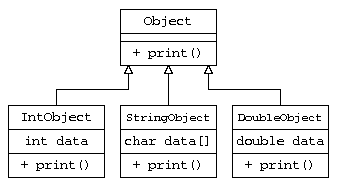
純粋仮想基底クラスとは、見かけ上はデータを何も持たないクラスであり、本来なら意味がないデータ構造となってしまう。しかし、派生クラスで要素となるデータと仮想関数で機能を与えることで、基底クラスという共通部分から便利な活用ができる。(実際には、型を区別するための型情報を持っている)
例えば、C言語であれば一つの配列に、整数、文字列、実数といった異なる型のデータを記憶させることは本来ならできない。しかし、以下のような処理を記載すれば、可能となる。
C言語では、1つの記憶域を共有するために共用体(union)を使うが、C++では仮想関数が使えるようになり、型の管理をプログラマーが行う必要のある「面倒で危険な」共用体を使う必要はなくなった。
// 純粋仮想基底クラス
class Object {
public:
virtual void print() const = 0 ;
// 中身の無い純粋基底クラスで、
// 仮想関数を記述しない時の書き方。
} ;
// 整数データの派生クラス
class IntObject : public Object {
private:
int data ;
public:
IntObject( int x ) {
data = x ;
}
virtual void print() const {
printf( "%d\n" , data ) ;
}
} ;
// 文字列の派生クラス
class StringObject : public Object {
private:
char data[ 100 ] ;
public:
StringObject( const char* s ) {
strcpy( data , s ) ;
}
virtual void print() const {
printf( "%s\n" , data ) ;
}
} ;
// 実数の派生クラス
class DoubleObject : public Object {
private:
double data ;
public:
DoubleObject( double x ) {
data = x ;
}
virtual void print() const {
printf( "%lf\n" , data ) ;
}
} ;
// 動作確認
int main() {
Object* data[3] = {
new IntObject( 123 ) ,
new StringObject( "abc" ) ,
new DoubleObject( 1.23 ) ,
} ;
for( int i = 0 ; i < 3 ; i++ ) { // 123
data[i]->print() ; // abc
} // 1.23 と表示
return 0 ;
} ;
このプログラムでは、純粋仮想基底クラスObjectから、整数IntObject, 文字列StringObject, 実数DoubleObject を派生させ、そのデータを new により生成し、Objectの配列に保存している。
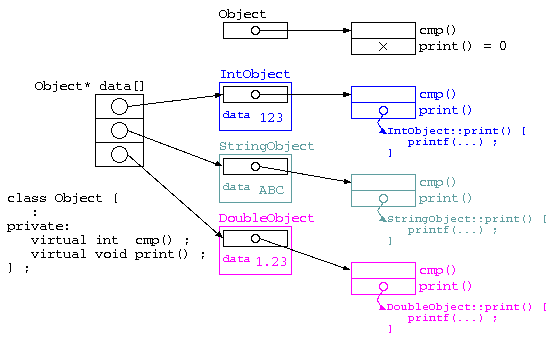
仮想関数を使うと、Object型の中に自動的に型情報が保存されるようになる。一般的な実装では、各派生クラス用の仮想関数のポインタテーブル(vtable)へのポインタが使われる。
Javaなどのオブジェクト指向言語では、全てのクラス階層のスーパークラスとして、Object を持つように作られている。
様々な型に適用できるプログラム
次に、純粋仮想基底クラスの特徴を応用したプログラムの作り方を説明する。
例えば、以下のような最大選択法で配列を並び替えるプログラムがあったとする。
int a[5] = { 11, 55, 22, 44, 33 } ;
void my_sort( int array[] , int size ) {
for( int i = 0 ; i < size - 1 ; i++ ) {
int max = i ;
for( int j = i + 1 ; j < size ; j++ ) {
if ( array[j] > array[max] )
max = j ;
}
int tmp = array[i] ;
array[i] = array[max] ;
array[max] = tmp ;
}
}
int main() {
my_sort( a , 5 ) ;
}
しかし、この整数を並び替えるプログラムがあっても、文字列の並び替えや、実数の並び替えがしたい場合には、改めて文字列用並び替えの関数を作らなければいけない。しかも、ほとんどが同じような処理で、改めて指定された型のためのプログラムを作るのは面倒である。
C言語のデータの並び替えを行う、qsort() では、関数ポインタを用いることで、様々なデータの並び替えができる。しかし、1件あたりのデータサイズや、データ実体へのポインタを正しく理解する必要がある。
#include <stdio.h> #include <stdlib.h> int a[ 4 ] = { 11, 33, 22, 44 } ; double b[ 3 ] = { 1.23 , 5.55 , 0.11 } ; // 並び替えを行いたいデータ専用の比較関数を作る。 // a>bなら+1, a=bなら0, a<bなら-1を返す関数 int cmp_int( int* pa , int* pb ) { // int型用コールバック関数 return *pa - *pb ; } int cmp_double( double* pa , double* pb ) { // double型用コールバック関数 if ( *pa == *pb ) return 0 ; else if ( *pa > *pb ) return 1 ; else return -1 ; } int main() { // C言語の怖さ qsort( a , 4 , sizeof( int ) , // このあたりの引数を書き間違えると (int(*)(void*,void*)) cmp_int ) ; // とんでもない目にあう。 qsort( b , 3 , sizeof( double ) , (int(*)(void*,void*)) cmp_double ) ; }このように、自分が作っておいた関数のポインタを、関数に渡して呼び出してもらう方法は、コールバックと呼ぶ。
JavaScript などの言語では、こういったコールバックを使ったコーディングがよく使われる。// コールバック関数 f を呼び出す関数 function exec_callback( var f ) { f() ; } // コールバックされる関数 foo() function foo() { console.log( "foo()" ) ; } // foo() を実行する。 exec_callback( foo ) ; // 無名関数を実行する。 exec_callback( function() { console.log( "anonymous" ) ; } ) ;
任意のデータを並び替え
class Object {
public:
virtual void print() const = 0 ;
virtual int cmp( Object* ) = 0 ;
} ;
// 整数データの派生クラス
class IntObject : public Object {
private:
int data ;
public:
IntObject( int x ) {
data = x ;
}
virtual void print() const {
printf( "%d\n" , data ) ;
}
virtual int cmp( Object* p ) {
int pdata = ((IntObject*)p)->data ; // 本当はこのキャストが危険
return data - pdata ; // ↓安全な実装したいなら↓
} // IntObject* pi = dynamic_cast<IntObject*>(p) ;
} ; // return pi != NULL ? data - pi->data : 0 ;
// 文字列の派生クラス
class StringObject : public Object {
private:
char data[ 100 ] ;
public:
StringObject( const char* s ) {
strcpy( data , s ) ;
}
virtual void print() const {
printf( "%s\n" , data ) ;
}
virtual int cmp( Object* p ) {
char* pdata = ((StringObject*)p)->data ;
return strcmp( data , pdata ) ; // 文字列比較関数
}
} ;
// 実数の派生クラス
class DoubleObject : public Object {
private:
double data ;
public:
DoubleObject( double x ) {
data = x ;
}
virtual void print() const {
printf( "%lf\n" , data ) ;
}
virtual int cmp( Object* p ) {
double pdata = ((DoubleObject*)p)->data ;
if ( data == pdata )
return 0 ;
else if ( data > pdata )
return 1 ;
else
return -1 ;
}
} ;
// Objectからの派生クラスでcmp()メソッドを
// 持ってさえいれば、どんな型でもソートができる。
void my_sort( Object* array[] , int size ) {
for( int i = 0 ; i < size - 1 ; i++ ) {
int max = i ;
for( int j = i + 1 ; j < size ; j++ ) {
if ( array[j]->cmp( array[max] ) > 0 )
max = j ;
}
Object* tmp = array[i] ;
array[i] = array[max] ;
array[max] = tmp ;
}
}
// 動作確認
int main() {
Object* idata[3] = {
new IntObject( 11 ) ,
new IntObject( 33 ) ,
new IntObject( 22 ) ,
} ;
Object* sdata[3] = {
new StringObject( "abc" ) ,
new StringObject( "defghi" ) ,
new StringObject( "c" ) ,
} ;
my_sort( idata , 3 ) ; // 整数のソート
for( int i = 0 ; i < 3 ; i++ )
idata[i]->print() ;
my_sort( sdata , 3 ) ; // 文字列のソート
for( int i = 0 ; i < 3 ; i++ )
sdata[i]->print() ;
return 0 ;
} ;
このような方式でプログラムを作っておけば、新しいデータ構造がでてきてもソートのプログラムを作らなくても、比較専用の関数 cmp() を書くだけで良い。
ただし、この並び替えの例では、Object* を IntObject* に強制的に型変換している。
また、このプログラムでは、データを保管するために new でポインタを保管し、データの比較をするために仮想関数の呼び出しを行うことから、メモリの使用効率も処理効率でもあまりよくない。
こういう場合、最近の C++ ではテンプレート機能が使われる。
template <typename T> void my_sort( T a[] , int size ) { for( int i = 0 ; i < size - 1 ; i++ ) { int max = i ; for( int j = i + 1 ; j < size ; j++ ) { if ( a[j] > a[max] ) max = j ; } T tmp = a[i] ; a[i] = a[max] ; a[max] = tmp ; } } int main() { int idata[ 5 ] = { 3, 4, 5 , 1 , 2 } ; double fdata[ 4 ] = { 1.23 , 0.1 , 3.4 , 5.6 } ; // typename T = int で int::mysort() が作られる my_sort( idata , 5 ) ; for( int i = 0 ; i < 5 ; i++ ) printf( "%d " , idata[i] ) ; printf( "\n" ) ; // typename T = double で double::mysort() が作られる my_sort( fdata , 4 ) ; for( int i = 0 ; i < 4 ; i++ ) printf( "%lf " , fdata[i] ) ; printf( "\n" ) ; return 0 ; }C++のテンプレート機能は、my_sort( int[] , int ) で呼び出されると、typename T = int で、整数型用の my_sort() の処理が自動的に作られる。同じく、my_sort( double[] , int ) で呼び出されると、typename = double で 実数型用の my_sort() が作られる。
テンプレート機能では、各型用のコードが自動的に複数生成されるという意味では、出来上がったコードがコンパクトという訳ではない。