ITフォーラム2018で学科展示
例年参加の産業会館でのITフォーラムにて電子情報工学科の展示を行いました。また、同会場のテクノフェアには小越先生の研究室も展示を行いました。


高久研究で開発している、フライトコントローラーの展示です。


演習part2、およびAVL木
前回、2分木へのデータ追加の説明と、演習課題を行っていたが、演習時間としては短いので、今日も前半講義で残り時間は演習とする。
2分木へのデータ追加と不均一な木の成長
先週の講義で説明していた、entry() では、データを追加すべき末端を探し、追加する処理であった。
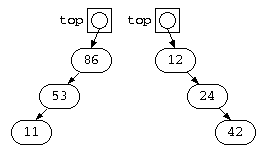
しかし、前回のプログラムで、以下のような順序でデータを与えたら、どのような木が出来上がるであろうか?
- 86, 53, 11 – 降順のデータ
- 12, 24, 42 – 昇順のデータ
この順序でデータが与えられると、以下のような木が出来上がってしまう。このような木では、データを探しても1回の比較でもデータ件数が1つ減るだけで、O(N)となってしまう。通常のデタラメな順序でデータが与えられれば、木はほぼ左右均等に成長するはずである。
AVL木
このような、不均一な木が出来上がっても、ポインタの繋ぎ変えで改善が可能となる。例えば、以下のような木では、赤の左側に偏っている。
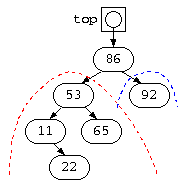
このような場合でも、最初、青の状態であっても、不均一な部分で赤のようなポインタの繋ぎ変えを行えば、木の段数を均一に近づけることができる。この例では、11,65,92の木が、右回転して 11 の木の位置が上がっている。(右回転)
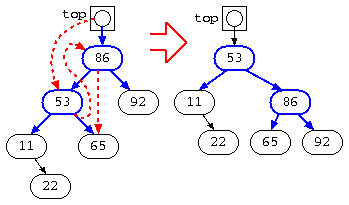
この様に、左右の枝の大きさが不均一な場所を見つけ、右回転(もしくは左回転)を行う処理を繰り返すことで、段数が均一な2分木に修正ができる。この様な処理でバランスの良い木に修正された木は、AVL木と呼ばれる。
理解確認
- 木の根からの段数を求める関数を作成せよ。
例えば、上のAVL木の説明の図であれば、4段なので4を返すこと。
// 木の段数を数える関数
_____ tree_depth( _______________ p ) {
if ( p == NULL ) {
return _____ ;
} else {
int d_L = ______________ ;
int d_R = ______________ ;
if ( d_L > d_R )
return _____ ;
else
return _____ :
}
}
void main() {
printf( "%d¥n" , tree_depth( top ) ) ;
}
デバッグのテクニック
課題のプログラムを作っているとき、動作に自信が無い時は、変数の中身を確認するための表示処理を埋め込むことが多い。しかし、プログラムが無事完成した後には、表示処理を消すことが多いだろう。この時、どのように命令を消すと良いのだろうか?
// /**/コメントで消す
void foo( int x ) {
/* printf( "%d" , x ) ; */
}
// "//"で消す
void foo( int x ) {
// printf( "%d" , x ) ;
}
void bar() { // "/**/"コメントは途中にコメントがあるとダメ
/*
a() ;
b() ; /* comment */
c() ;
d() ;
*/
}
void bar() { // "//"コメントは全行に入れる必要あり
// a() ;
// b() ;
// c() ;
// d() ;
}
では、効率のよいコメントアウトはどうするのか?
void bar() { // #if は、プリプロセッサで
#if 0 // 条件が偽の時は、#endifまでが消される。
a() ;
b() ;
c() ;
d() ;
#endif
}
一般的には、#if は、defined() と共に使われる。
#define DEBUG // 完成したら、#defineの前に//を入れる。
:
void bar() {
#if defined( DEBUG )
:
#endif
}
// 通常は、コンパイルオプションを使うのが普通
// gcc -DDEBUG bar.c
SQLと結合
SQLの基礎
前回の講義で、データベースでは、記録されているデータの読み書きは、SQL で行われ、射影・結合・選択を表す処理で構成されることを示した。SQL の機能を理解するために、同じ処理を C 言語で書いたらどうなるのかを示す。
SELECT S.業者番号 -- 必要とされるデータを抽出する射影 --
FROM S -- 複数のテーブルを組合せる結合 --
WHERE S.優良度 >= 20 ; -- 対象となるデータを選び出す選択 --
// 配列の個数を求める #define 文
#define sizeofarray(ARY) (sizeof(ARY) / sizeof(ARY[0]))
// C言語なら... S のデータを構造体宣言で書いてみる。
struct Table_S {
char 業者番号[ 6 ] ;
char 業者名[ 22 ] ;
int 優良度 ;
char 所在[ 16 ] ;
} S[] = {
{ "S1" , "ABC社" , 20 , "福井" } ,
:
} ;
// 結合
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
// 選択
if ( S[i].優良度 >= 20 )
// 射影
printf( "%d¥n" , S[i].業者番号 ) ;
}
Sは、テーブル名であり、文脈上対象テーブルが明らかな場合、フィールド名の前の テーブルは省略可能である。
SELECT 業者番号 FROM S WHERE 優良度 >= 20 ;
WHERE 節で記述できる条件式では、= , <>(not equal) , < , > , <= , >= の比較演算子が使える。
直積と結合処理
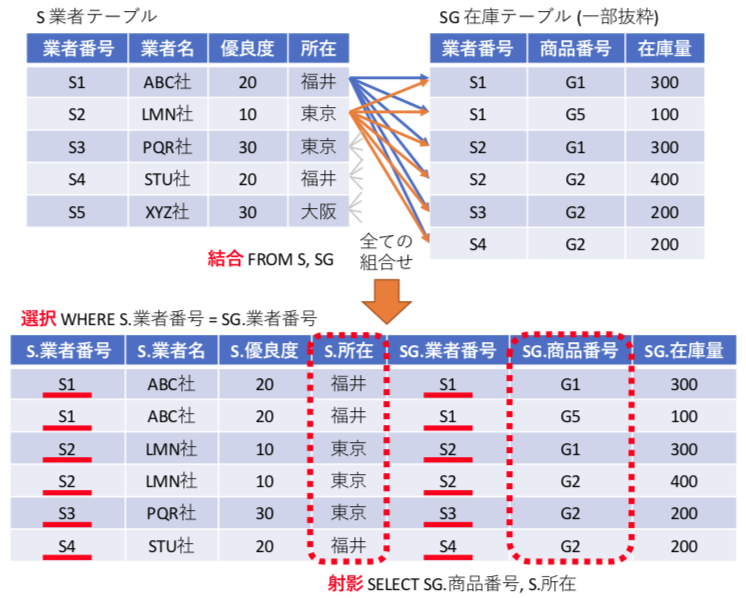
ここで、SQLの最も便利な機能は、直積による結合処理。複数の表を組み合わせる処理。単純な表形式の関係データベースで、複雑なデータを表現できる基本機能となっている。
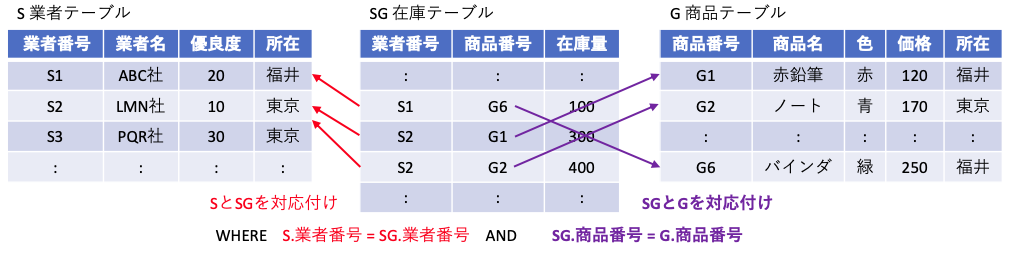
SELECT SG.商品番号 , S.所在 FROM S , SG WHERE SG.業者番号 = S.業者番号
上記の様に FROM 節に複数のテーブルを書くと、それぞれのテーブルの直積(要素の全ての組み合わせ)を生成する処理が行われる。この機能が結合となる。しかし、これだけでは意味がないので、通常は外部キーが一致するレコードでのみ処理を行うように、WHERE SG.業者番号 = S.業者番号 のような選択を記載する。最後に、結果として欲しいデータを抽出する射影を記載する。
// C言語なら
struct Table_S {
char 業者番号[ 6 ] ;
char 業者名[ 22 ] ;
int 優良度 ;
char 所在[ 16 ] ;
} S[] = {
{ "S1" , "ABC社" , 20 , "福井" } ,
:
} ;
struct Table_SG {
char 業者番号[ 6 ] ;
char 商品番号[ 6 ] ;
int 在庫量 ;
} = SG[] {
{ "S1" , "G1" , 300 } ,
:
} ;
// FROM S
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
// FROM SG
for( int j = 0 ; j < sizeofarray( SG ) ; j++ ) {
// WHERE S.業者番号 = SG.業者番号
if ( strcmp( S[i].業者番号 , SG[j].業者番号 ) == 0 ) {
// SELECT SG.商品番号 , S.所在
printf( "%s %s¥n" , SG[j].商品番号 , S[i].所在 ) ;
}
}
}
(1) i,jの2重forループが、FROM節の結合に相当し、(2) ループ内のif文がWHERE節の選択に相当し、(3) printfの表示内容が射影に相当している。
射影の処理では、データの一部分を抽出することから、1件の抽出レコードが同じになることもある。この際の重複したデータを1つにまとめる場合には、DISTINCT を指定する。
SELECT DISTINCT SG.商品番号, S.所在 FROM S, SG WHERE SG.業者番号 = S.業者番号 ;
上記のプログラムでは、データの検索は単純 for ループで記載しているが、内部で HASH などが使われていると、昇順に処理が行われない場合も多い。出力されるデータの順序を指定したい場合には、ORDER BY … ASC (or DESC) を用いる
SELECT SG.商品番号, S.所在 FROM S, SG WHERE SG.業者番号 = S.業者番号 ORDER BY S.所在 ASC ; -- ASC:昇順 , DESC:降順 --
表型のデータと串刺し
FROM に記載する直積のための結合では、2つ以上のテーブルを指定しても良い。
SELECT S.業者名, G.商品名, SG.在庫量
FROM S, G, SG
WHERE S.業者番号 = SG.業者番号 -- 外部キー業者番号の対応付け --
AND SG.商品番号 = G.商品番号 -- 外部キー商品番号の対応付け --
// 上記の処理をC言語で書いたら
struct Table_G {
char 商品番号[ 6 ] ;
char 商品名[ 22 ] ;
char 色[ 4 ] ;
int 価格 ;
char 所在[ 12 ] ;
} = G[] = {
{ "G1" , "赤鉛筆" , "青" , 120 , "福井" } ,
:
} ;
// FROM S (結合)
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
// FROM G (結合)
for( int j = 0 ; j < sizeofarray( G ) ; j++ ) {
// FROM SG (結合)
for( int k = 0 ; k < sizeofarray( SG ) ; k++ ) {
// WHERE S.業者番号 = SG.業者番号
// AND SG.商品番号 = G.商品番号 (選択)
if ( strcmp( S[i].業者番号 , SG[k].業者番号 ) == 0
&& strcmp( SG[k].商品番号 , G[j].商品番号 ) == 0 ) {
// 使用するフィールドを出力 (射影)
printf( "%s %s %d\n" ,
S[i].業者名 , G[j].商品名 , SG[k].在庫量 ) ;
}
}
}
}
 ここで結合と選択で実行している内容は、外部キーである業者番号を S から探す、商品番号を G から探している。この、外部キー対応しているものを探すという視点で、上記 C 言語のプログラムを書き換えると、以下のように表せる。
ここで結合と選択で実行している内容は、外部キーである業者番号を S から探す、商品番号を G から探している。この、外部キー対応しているものを探すという視点で、上記 C 言語のプログラムを書き換えると、以下のように表せる。
// FROM SG
for( int k = 0 ; k < sizeofarray( SG ) ; k++ ) {
// 外部キー SG.業者番号に対応するものを S から探す
for( int i = 0 ; i < sizeofarray( S ) ; i++ ) {
if ( strcmp( S[i].業者番号 , SG[k].業者番号 ) == 0 ) {
// 外部キー SG.商品番号に対応するものを G から探す
for( int j = 0 ; j < sizeofarray( G ) ; j++ ) {
if ( strcmp(SG[k].商品番号,G[j].商品番号) == 0 ) {
printf( "%s %s %d\n" ,
S[i].業者名,G[j].商品名,SG[k].在庫量 ) ;
}
}
}
}
}
このような、複数の表の実体と関係を対応付けた検索を、データベースの専門の人は「データを串刺しにする」という言い方をすることも多い。
また、SQL では、このようなイメージの繰り返し処理を、数行で分かりやすく記述できている。このプログラム例では、キーに対応するものを単純 for ループで説明しているが、SQL ではプライマリキーなら、B木やハッシュなどを用いた検索が行われるが、SQLの記述するときにはあまり考えなくて良い。
SQLの副問い合せ
前節の結合処理は時として効率が悪い。このような場合は、副問い合わせを用いる場合も多い。
SELECT S.業者名, S.所在
FROM S
WHERE S.業者番号 IN
( SELECT SG.業者番号
FROM SG
WHERE SG.商品番号 = 'G2'
AND SG.在庫量 >= 200 ) ;
まず、『◯ IN { … }』 の比較演算子は、◯が{…}の中に含まれていれば、真となる。また、SQLの中の (…) の中が副問い合わせである。
この SQL では、副問い合わせの内部には、テーブル S に関係する要素が含まれない。この場合、副問い合わせ(商品番号がG2で在庫量が200以上)は先に実行される。
{(S1,G2,200),(S2,G2,400),(S3,G2,200),(S4,G2,200)}が該当し、その業者番号の{S1,S2,S3,S4}が副問い合わせの結果となる。最終的に SELECT … FROM S WHERE S.業者番号 IN {‘S1′,’S2′,’S3′,’S4’} を実行する。
相関副問い合わせ
SELECT G.商品名, G.色, G.価格
FROM G
WHERE 'S4' IN
( SELECT SG.業者番号
FROM SG
WHERE SG.商品番号 = G.商品番号 ) ;
この副問い合わせでは、内部に G.商品番号 が含まれており、単純に()内を先に実行することはできない。こういった副問い合わせは、相関副問い合わせと呼ばれる。
処理は、Gのそれぞれの要素毎に、副問い合わせを実行し、その結果を使って WHERE節の判定を行う。WHERE節の選択で残った結果について、射影で商品名,色,価格が抽出される。
// 概念の説明用に、C言語風とSQL風を混在して記載する
for( int i = 0 ; i < sizeofarray( G ) ; i++ ) {
SELECT SG.業者番号 FROM SG
WHERE SG.商品番号 = G[i].商品番号 を実行
if ( WHERE 'S4' IN 副query の結果が真なら ) {
printf( ... ) ;
}
}
// 全てのG 副queryの結果 WHERE 射影
// G1 -> {S1,S2}
// G2 -> {S1,S2,S3,S4} -> ◯ -> (ノート,青,170)
// G3 -> {S1}
// G4 -> {S1,S4} -> ◯ -> (消しゴム,白,50)
// G5 -> {S1,S4} -> ◯ -> (筆箱,青,300)
// G6 -> {S1}
4年インターンシップ報告会
今日は、夏休みの間に実施されていた、4年のインターンシップ報告会がありました。短い時間での発表で、すべての体験を話す時間もなく、難しい所もありましたが、大切な経験を色々と聞くことができました。 さまざまな企業があり感想も色々ですが、個人的には「指導者の方に、現場にこそITの人材が必要」と言われたとの報告があり、いい経験をしていると思いました。
さまざまな企業があり感想も色々ですが、個人的には「指導者の方に、現場にこそITの人材が必要」と言われたとの報告があり、いい経験をしていると思いました。
2018高専祭・電子情報・学科展示
今年の高専祭では、各学科の学科展示が行われました。電子情報工学科では、プロジェクションマッピングなどの映像系の展示で面白いデモが楽しめました。
コエカタマルン
マイクで喋った内容がリアルタイムに文字になって流れます。
滝行〜SHUGYO〜
2分探索木にデータ追加と演習
2分探索木にデータを追加
前回の授業では、データの木構造は、補助関数 tcons() により直接記述していた。実際のプログラムであれば、データに応じて1件づつ木に追加するプログラムが必要となる。この処理は以下のようになるだろう。
struct Tree* top = NULL ;
// 2分探索木にデータを追加する処理
void entry( int d ) {
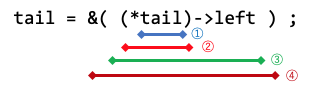
struct Tree** tail = &top ;
while( *tail != NULL ) {
if ( (*tail)->data == d ) // 同じデータが見つかった
break ;
else if ( (*tail)->data > d )
tail = &( (*tail)->left ) ; // 左の枝に進む
else
tail = &( (*tail)->right ) ; // 右の枝に進む
}
if ( (*tail) == NULL )
*tail = tcons( NULL , d , NULL ) ;
}
int main() {
char buff[ 100 ] ;
int x ;
while( fgets( buff , sizeof( buff ) , stdin ) != NULL )
if ( sscanf( buff , "%d" , &x ) != 1 )
break ;
entry( x ) ;
return 0 ;
}
このプログラムでは、struct Tree** tail というポインタへのポインタ型を用いている。tail が指し示す部分をイメージするための図を以下に示す。
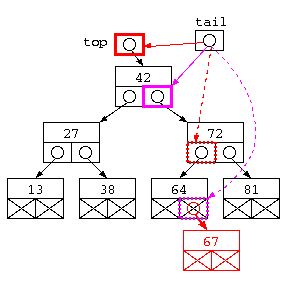
理解確認
- 関数entry() の14行目の if 判定を行う理由を説明せよ。
- 同じく、8行目の tail = &( (*tail)->left ) の式の各部分の型について説明せよ。
- sscanf() の返り値を 1 と比較している理由を説明せよ。
- entry() でデータを格納する処理時間のオーダを説明せよ。
// 前述プログラムは、データ追加先が大域変数なのがダサい。 // 局所変数で追加処理ができるように、したいけど... void entry( struct Tree* top , int d ) { struct Tree** tail = &top ; while( *tail != NULL ) { : // 上記の entry() と同じとする } void main() { // 追加対象の top は局所変数 struct Tree* top = NULL ; char buff[ 100 ] ; int x ; while( fgets(buff,sizeof(buff),stdin) != NULL ) { if ( sscanf( buff , "%d" , &x ) != 1 ) break ; entry( top , x ) ; } }上記のプログラム↑は動かない。なぜ?
このヒントは、このページ末尾に示す。
演習課題
以下のようなデータを扱う2分探索木のプログラムを作成せよ。以下の箇条書き番号の中から、(出席番号 % 3+1)のデータについてプログラムを作ること。
- 名前(name)と電話番号(phone)
- 名前(name)と誕生日(year,mon,day)
- 名前(name)とメールアドレス(mail)
プログラムは以下の機能を持つこと。
- 1行1件でデータを入力し、2分木に追加できること。
- 全データを昇順(or降順)で表示できること。
- 検索条件を入力し、目的のデータを探せること。
レポートでは、(a)プログラムリスト,(b)その説明,(c)動作検証結果,(d)考察 を記載すること。考察のネタが無い人は、このページの理解確認の内容について記述しても良い。
// プログラムのおおまかな全体像の例
struct Tree {
//
// この部分を考えて
// 以下の例は、名前と電話番号を想定
} ;
struct Tree* top = NULL ;
void tree_entry( char n[] , char ph[] ) {
// n:名前,ph:電話番号 を追加
}
void tree_print( struct Tree* p ) {
// 全データを表示
}
struct Tree* tree_search_by_name( char n[] ) {
// n:名前でデータを探す
}
int main() {
char name[ 20 ] , phone[ 20 ] ;
char buff[ 1000 ] ;
struct Tree* p ;
// データを登録する処理(空行を入力するまで繰り返し)
while( fgets( buff , sizeof( buff ) , stdin ) != NULL ) {
if ( sscanf( buff , "%s%s" , name , phone ) != 2 )
break ; // 入力で、2つの文字列が無い場合はループを抜ける
tree_entry( name , phone ) ;
}
// 全データの表示
tree_print( top ) ;
// データをさがす
while( fgets( buff , sizeof( buff ) , stdin ) != NULL ) {
if ( sscanf( buff , "%s" , name ) != 1 )
break ; // 入力で、1つの文字列が無い場合はループを抜ける
if ( (p = tree_search_by_name( name )) == NULL )
printf( "見つからない¥n" ) ;
else
printf( "%s %s¥n" , p->name , p->phone ) ;
}
return 0 ;
}
動かないプログラムのヒント
// 前述プログラムは、データ追加先が大域変数なのがダサい。
// 局所変数で追加処理ができるように、したいけど...
// ちなみに、こう書くと動く
// Tree*を返すように変更
struct Tree* entry( struct Tree* top , int d ) {
:
// 最初の entry と同じ
:
return top ;
}
void main() {
// 追加対象のポインタ
struct Tree* top = NULL ;
while( ... ) {
:
// entry() の返り値を top に代入
top = entry( top , x ) ;
}
}
fgets()とsscanf()による入力の解説
前述のプログラムの入力では、fgets() と sscanf() による処理を記載した。この関数の組み合わせが初見の人も多いと思うので解説。
// scanf() で苦手なこと -------------------------//
// scanf() のダメな点
// (1) 何も入力しなかったら...という判定が難しい。
// (2) 間違えて、abc みたいに文字を入力したら、
// scanf()では以後の入力ができない。(入力関数に詳しければ別だけどさ)
int x ;
while( scanf( "%d" , &x ) == 1 ) {
entry( x ) ;
}
// scanf() で危険なこと -------------------------//
// 以下の入力プログラムに対して、10文字以上を入力すると危険。
// バッファオーバーフローが発生する。
char name[ 10 ] ;
scanf( "%s" , name ) ;
// 安全な入力 fgets() ---------------------------//
// fgets() は、行末文字"¥n"まで配列 buff[]に読み込む。
// ただし、sizeof(buuf) 文字より長い場合は、途中まで。
char buff[ 100 ] ;
while( fgets( buff , sizeof( buff ) , stdin ) != NULL ) {
// buff を使う処理
}
// 文字列からデータを抜き出す sscanf() -------------//
// sscanf は、文字列の中から、データを抜き出せる。
// 入力が文字列であることを除き、scanf() と同じ。
char str[] = "123 abcde" ;
int x ;
char y[10] ;
sscanf( str , "%d%s" , &x , y ) ;
// x=123 , y="abcde" となる。
// sscanf() の返り値は、2 (2個のフィールドを抜き出せた)
理解確認
- 標準入力からの1行入力関数 gets() 関数が危険な理由を説明せよ。
出席確認をFormsで
先日、防災訓練での安否確認の訓練を、Office365の一斉メールと、Forms を使った安否確認により行った。しかし、回答数は50%ほどで、このままでは災害などの場合に、担任が半数の学生には電話をかける手間が発生し、迅速な安否確認とはならない。
問題点は、Office365 の利用に慣れていないのが原因。ということで、先生や学生も含め Office365 の利用普及をしたいので、例えば「授業の出席確認」をスマホ&Formsで実施するためのメモを記載。
Formsで出席確認のアンケート入力をする方法
Office365を起動し、画面左上のメニューより Forms を起動する。
新しいアンケートフォームを作る時は、新しいフォームを選び、アンケートの質問に名前をつける。
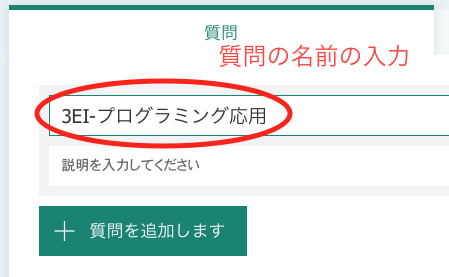
出席を取るのであれば、回答者のメールアドレスと回答時間が自動的に記録されるので、これを元に学生を特定できるけど、クラス内出席番号を回答してもらうと、集計が簡単。
出席番号の入力欄を作る

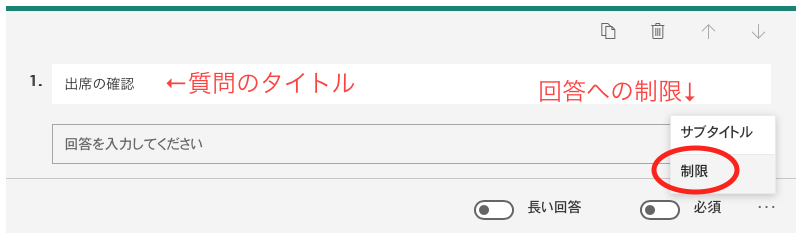
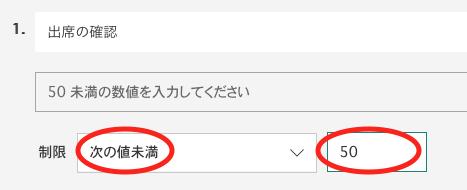
テキストの解答欄を作る
出席を取るだけではもったいないので、授業中学生に質問をして、その回答を Forms で回答してもらうようにしている。かといって、説明する内容に応じて質問項目を毎回の授業で作れない場合も多いので、
- 回答内容を選ぶメニューと、
- 答えを回答する欄(もしくは質問する欄)
を作っておく
![]()
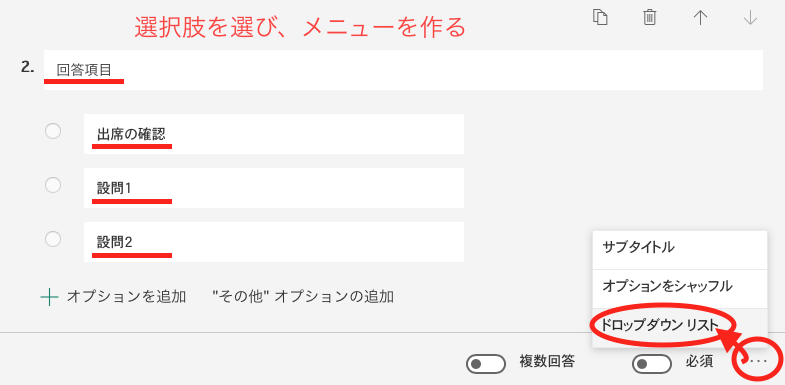
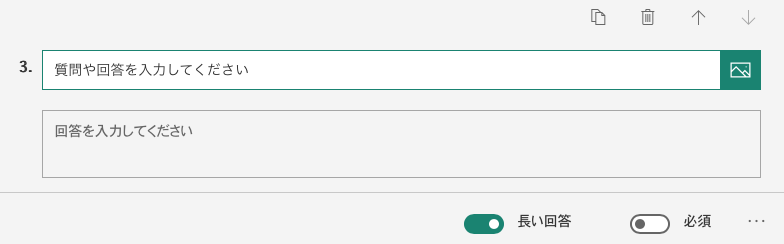
最終的な回答画面の例

SQLの基本
先週の、関係データベースの導入説明を終えて、実際のSQLの説明。
キー
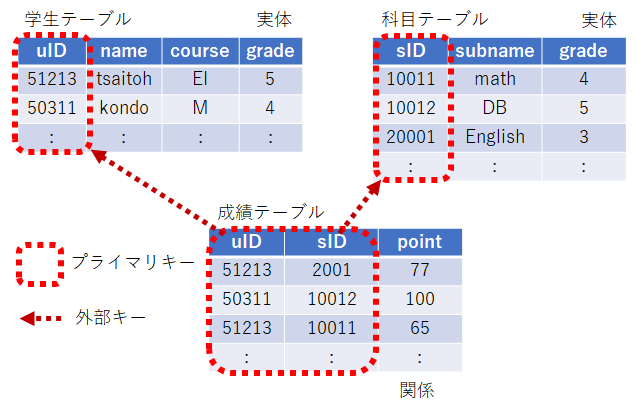
表形式のテーブルの中の各レコードを一意的に指定できるカラムはキーと呼ばれる。
キーは単独であるとは限らず、成績の評価結果であれば、学生と科目をキーとして成績というカラムが1つに絞られる場合もある。
キーのうち、データを一意に識別するためのキーは、プライマリーキーと呼ばれる。以下の例であれば、uID,sID がプライマリーキーである。一方、成績のテーブルでは、uID, sID は、学生,科目のキーとなっている。このようなキーは外部キーと呼ばれる。点数pointは、uID, sID により一意に決まるが、例えば成績の uID に、学生のテーブルに存在しないものが指定されてはいけない。こういった制約は外部キー制約と呼ばれる。
SQLの命令
SQL で使われる命令は、以下のものに分類される。
- データ定義言語 – CREATE, DROP, ALTER 等
- データ操作言語 – INSERT, UPDATE, DELETE, SELECT 等
- データ制御言語 – GRANT, REVOKE 等 (その他トランザクション制御命令など)
create user
データベースを扱う際の create user 文は、DDL(Data Definition Language)で行う。
CREATE USER ユーザ名
IDENTIFIED BY "パスワード"
grant
テーブルに対する権限を与える命令。
GRANT システム権限 TO ユーザ名 データベースシステム全体に関わる権限をユーザに与える。 (例) GRANT execute ON admin.my_package TO saitoh GRANT オブジェクト権限 ON オブジェクト名 TO ユーザ名 作られたテーブルなどのオブジェクトに関する権限を与える。 (例) GRANT select,update,delete,insert ON admin.my_table TO saitoh REVOKE オブジェクト権限 ON オブジェクト名 TO ユーザ名 オブジェクトへの権限を剥奪する。
create table
実際にテーブルを宣言する命令。構造体の宣言みたいなものと捉えると分かりやすい。
CREATE TABLE テーブル名 ( 要素名1 型 , 要素名2 型 ... ) ; PRIMARY KEY 制約 型の後ろに"PRIMARY KEY"をつける、 もしくは、要素列の最後に、PRIMARY KEY(要素名,...)をつける。 これによりKEYに指定した物は、重複した値を格納できない。 型には、以下の様なものがある。(Oracle) CHAR( size) : 固定長文字列 / NCHAR国際文字 VARCHAR2( size ) : 可変長文字列 / NVARCHAR2... NUMBER(桁) :指定 桁数を扱える数 BINARY_FLOAT / BINARY_DOUBLE : 浮動小数点(float / double) DATE : 日付(年月日時分秒) SQLiteでの型 INTEGER : int型 REAL : float/double型 TEXT : 可変長文字列型 BLOB : 大きいバイナリデータ DROP TABLE テーブル名 テーブルを削除する命令
insert,update,delete
指定したテーブルに新しいデータを登録,更新,削除する命令
INSERT INTO テーブル名 ( 要素名,... ) VALUES ( 値,... ) ; 要素に対応する値をそれぞれ代入する。 UPDATE テーブル名 SET 要素名=値 WHERE 条件 指定した条件の列の値を更新する。 DELETE FROM テーブル名 WHERE 条件 指定した条件の列を削除する。
select
データ問い合わせは、select文を用いる、 select文は、(1)必要なカラムを指定する射影、(2)指定条件にあうレコードを指定する選択、 (3)複数のテーブルの直積を処理する結合から構成される。
SELECT 射影 FROM 結合 WHERE 選択 (例) SELECT S.業者番号 FROM S WHERE S.優良度 > 30 ;
理解確認
- キー・プライマリキー・外部キーについて説明せよ。
- 上記説明中の、科目テーブルにふさわしい create table 文を示せ。
- select文における、射影,結合,選択について説明せよ。
Ethernet LANとWAN接続
前回の物理層のLANの話に引き続き、WANの話を説明。
バス接続(LAN)と転送速度
基本的な Ethernet の接続では、1本の通信路を共有するバス型接続のため、1本の信号線をパケット単位の通信の短い時間に区切って、送信を交代しながら行う時分割多重方式で行い通信を行う。
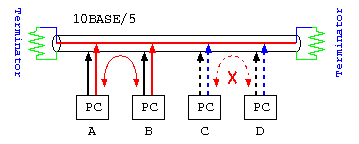
例えば、4台のパソコンで、A-B間、C-D間で同時に通信を行おうとすると、A-Bの通信中は、通信路が使用中のため、C-D間の通信はできない。このため、A-B間、C-D間の通信をパケットを送る毎に交代しながら通信路を利用する。
-
- 10BASE/5の PC-AとPC-Bの間で、音楽CD1枚のデータ(700MB)をを送る場合、通信時間はどの位かかるか?
- →答え:
700M[byte] = 5.6G[bit] なので、10M[bit/sec]で送ると、560[sec]
- →答え:
- 同じく、A-B間、C-D間で同時に送る場合は、通信時間はどのくらいかかるか?
- →答え:
同時に通信ができないので、通信路を切り替えながら送るため、倍の時間がかかる。よって、1120[sec]
- →答え:
- 10BASE/5の PC-AとPC-Bの間で、音楽CD1枚のデータ(700MB)をを送る場合、通信時間はどの位かかるか?
HUBを使った通信路、10BASE/T, 100BASE-T, *BASE-T では、HUBの内部構造に注意が必要。基本的には、見かけ上は木構造のように分配しているように見えるけど、内部はバス型の通信路に変わりはない。10BASE/T を利用している頃は、HUBは高価であり単純なバス型接続のHUB(Dumb HUB)であれば、C-D間通信中は、E-F間通信ができない。
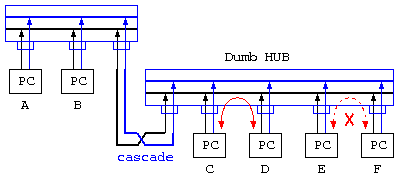
しかしこれでは、通信速度が無駄になるので、最近はスイッチングHUBが利用される。このHUBは、通信相手に応じてHUB内部の通信路を切り分けるので、A-B間通信中でも、C-D間通信が可能となる。
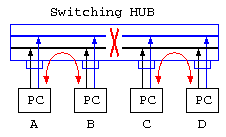
理解確認
- 2つのDumb HUBで、A,B,C,D,E,Fのコンピュータが繋がっている時、A-C間、B-D間で音楽CD700MBのデータを送る場合、通信時間はどうなる?
電話線接続
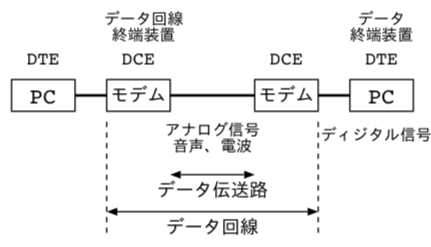
同じ敷地内のネットワーク接続のLANどうしを、ネットワークで相互接続するWAN(Wide Area Network)では、昔は電話線を用いていた。電話は、本来音声を伝えるためのものであるため、0/1のデジタル信号を、音の信号に変換(変調)し、受信側は音をデジタル信号に(復調)する。これらを行う機器は、変復調装置(モデム)と呼ばれる。
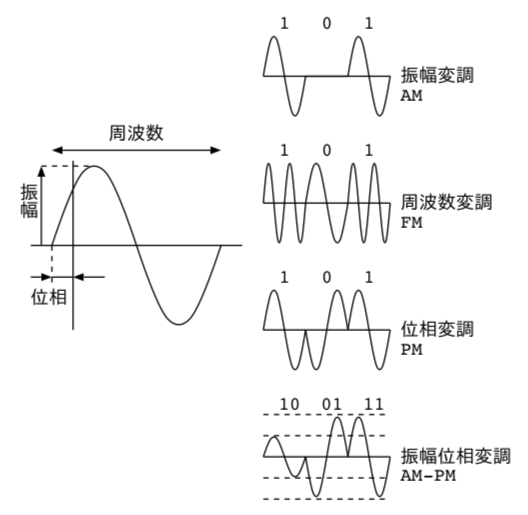
変調の際には、0/1信号を、音の強弱(振幅変調/AM),音程の高低(周波数変調/FM),位相の前後(位相変調/PM)の組み合わせによって、送受信を行う。
当初は、300bps程度であったが、最終的には64Kbps 程度の通信速度が得られた。
これらの通信速度の改善のため、電話線にデジタル信号で送る ISDN , 電話線の音の信号の高帯域を使った通信 ADSLなどが用いられた。
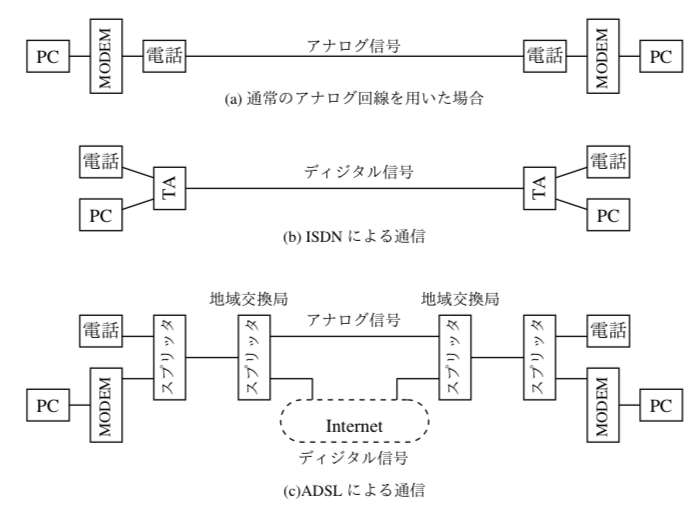
最近では、光ファイバによる FTTH(Fiber To The Home) により 1Gbps を越える通信が可能となっている。
通信速度の理解と、古い時代の通信速度を体験してもらうため、試しに「2000ドット✕1500ドットのRGB画像(1ドット3byte)のデータ(無圧縮)を、9600bps で通信したら、どの程度の時間を要するか、いくらかかるのか?」を計算してみよう。ちなみに2000年頃は、携帯電話では、1Kbyteあたり10円の通信料がかかった。
→答え:
データ量 2000✕1500✕3✕8 [bit] = 72 M[bit]
通信速度 9600[bps] であれば、72 M / 9600 = 7500[sec] = 約2時間
通信費 72M[bit]/8/1000 = 9000[Kbyte]、
通信料金 9000[Kbyte]=9000[パケット]、1パケット(1KB)10円だから90,000円 😥
# 320✕240✕RGB(16bit)で圧縮で1/5であれば、それでも100円超え
J-PHONE(J-SH04,200年発売)で始めてカメラ付き携帯が登場
ネットワークトポロジ
ネットワークに機器を接続する形態をネットワークトポロジと言う。
1本の線を共有するバス型、機器どうしがリング型に接続するリング型、中央の機器を通して接続されるスター型が基本となる。
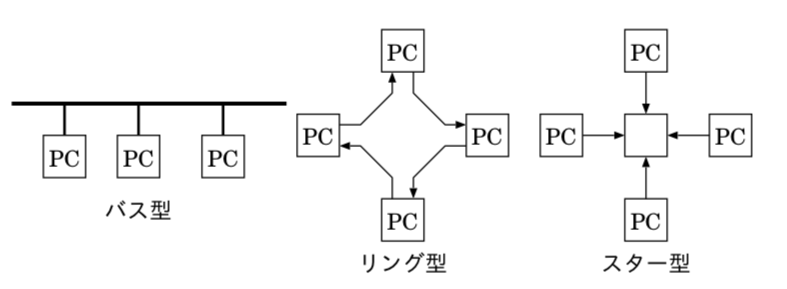
基本的に、Ethernet は 1本の線を機器で共有するバス型。ただし、10BASE-T,100BASE-TX などの HUB で繋がることから、HUB を中心に広がるスター型とも言える。それぞれれのネットワークは相互につながることから、木の枝状に見えるものはツリー型と呼ばれる。また、上流ネットワークでは、機器が故障した場合に一切の通信ができなくなるのは問題があるため、複数のネットワークで相互に接続される。この場合、網が絡むような構造になることから、ネットワーク型と呼ばれる。
講義録の答え隠し
WordPressの講義録を見せながらの授業だけど、考えてもらいたい時に答えも含めすべて記載してあると、悩んでもらえない。この対応として以前は、JavaScript を使って非表示/表示をさせていたけど、WordPressのビジュアルエディタが、タグの onclick=”javascript処理” を消してくれるため、編集に注意が必要だった。
CSSだけで表示を隠したいので、mouse over(:hover) を使うようにしてみた。
/* 隠したい所は、<div class="hidden-hover">隠すテキスト</div> */
.hidden-hover {
color: #EEE;
background-color: #EEE;
}
.hidden-hover:hover {
color: #000;
background-color: #AFA;
}
授業で理解度の確認で、この問題解いて…の結果を Forms でリアルタイムに返答させたけど、解かせて回答させるとなると、答え見ちゃうよなぁ….。この程度の隠し方では、正解しか帰ってこない。見せ方をもっと変えないとダメだな。
授業前に、hover で隠している部分を コメントアウトして、授業後に戻すぐらいしないとダメだな。