データベースシステムとして、最近は NoSQL (Not Only SQL) が注目されている。この中で、広く使われている物として、Google Firestore などが有名である。教科書以外の最近のデータベースの動向ということで、最後に NoSQL の説明を行う。
RAIDと分散
データの分散という意味の対比や、データベースの実際にデータが格納される HDD の故障対策という点で、最初に RAID の説明を行う。
ハードディスクの故障対策などで、複数の HDD にデータを保存することで、データのアクセス速度や故障時のリカバリ対策をする方式として RAID (Redundant Array of Inexpensive Disks) がある。
RAID0 – データを複数の HDD に分散して保存する方式。読み書き速度の向上のために用いる。
RAID1 – データを複数の HDD に同じように保存する方式。(ミラーリング) 壊れたディスクを交換するだけでリカバリができる。
RAID5 – データを複数の HDD に分散して保存。冗長性のための Parity 情報も分散して保存することで、HDD の 1つが壊れても復帰することができる。分散保存による読み書き速度向上も得られる。
RAID6 – データ誤り補正のデータを複数もたせて、分散保存
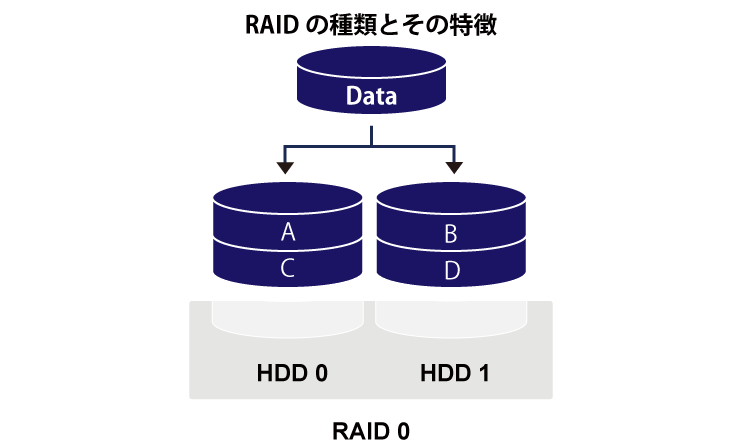
RAID0
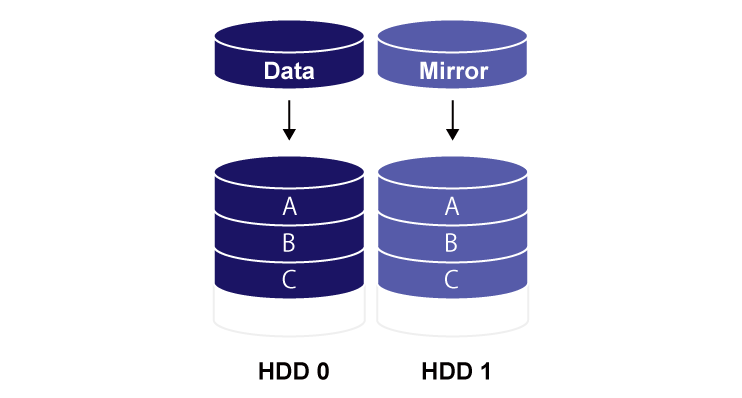
RAID1
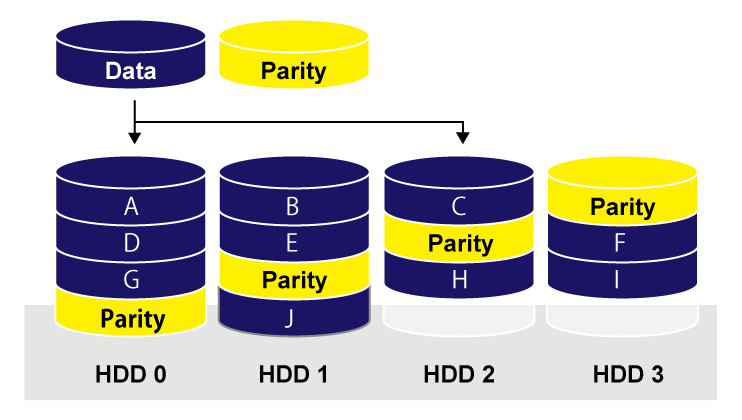
RAID5
リレーショナルデータベースシステムの問題
リレーショナルデータベースのシステムでは、大量の問い合わせに対応する場合、データのマスターとなるプライマリサーバに、そのデータの複製を持つ複数のセカンダリサーバを接続させる方式がとられる。しかしながら、この方式ではセカンダリサーバへのデータ更新を速やかにプライマリサーバに反映させる、さらにその結果が他のセカンダリサーバに反映させる必要があることから、大量のデータに大量の問い合わせがあるようなシステムでは、これらのデータ同期の性能が求められる。しかも、プライマリサーバが故障した場合の復旧なども考えると、こういったプライマリ・セカンダリ・サーバ構成での運用・管理は大変である。(Oracle では、後述のシャードの考え方を導入し、プライマリ・セカンダリ構成の問題の対応を行っている)
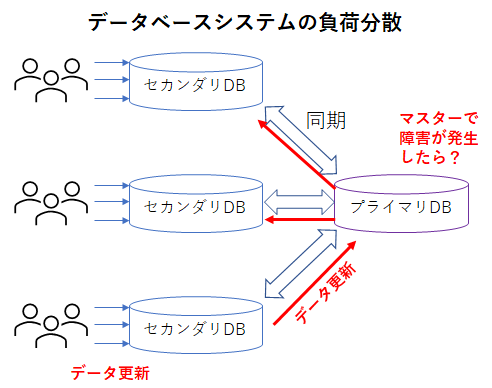
NoSQLの利点
NoSQLデータベースでは、データを複数のサーバー(異なるデバイスやネットワーク)に分散して保存し、同時にレプリケーション(複製)を行うことで可用性を高める。
多くの分散型NoSQLでは、特定の1台に依存しない「リーダーレス」や「マルチマスター」に近い構成をとることで、単一障害点を排除する。一部のサーバーが故障しても、他のサーバーに保持されたコピー(複製)を用いてサービスを継続できるため、システム全体が停止することはない。
リレーショナルデータベース(RDB)が大量のアクセスを受ける場合、データの整合性維持や障害対応、スケーラビリティ(負荷に応じた性能拡張)が課題となる。これに対しNoSQLは、データを分散配置する設計とすることで、サーバーを追加するだけで処理能力を向上させることが可能となる。
NoSQLはデータモデルによって主に4つに分類される。
- キーバリューストア型(KVS): 最もシンプルで、一意のキーに対して値を保存
- ドキュメント指向型: JSONのような構造でデータを保存(Firestoreなど)
- カラム指向型: 列単位でデータを管理し、大規模な集計向き
- グラフ型: データ間の「つながり」を管理
これらの方式では、SQLのような複雑なテーブル結合(JOIN)が苦手となるが、Firestoreのサブコレクションや、データの持ち方を工夫する(非正規化)ことで、高速なデータ取得を実現している。
Google の Firestore
NoSQLのデータベースを構築したのは、Google が先駆けであった。現在、このGoogle の NoSQL のシステムは、Firestore として利用されている。(データベースはFireBase)
FireStore では、データをシャードと呼ばれる単位に分割し、インデックスやキーに応じて異なるサーバーへ分散して配置する。
データの可用性を高めるために同じシャードを複数のサーバーに複製(レプリケーション)する時には、その際に生じるデータの不整合を解決するため、Firestoreでは正確な時間情報(TrueTime)を活用し、複数のノード間で合意を取りながら一貫性を保った処理を行う。
Firestoreはドキュメント指向型のデータベースであり、すべてのデータは「ドキュメント」と「コレクション」という単位で管理される。
- ドキュメント: 従来のリレーショナルデータベースにおける「レコード」に相当し、スキーマレスなJSON形式(フィールドと値のペア)でデータを保持する。
- コレクション: ドキュメントをまとめるコンテナであり、各ドキュメントは一意のキー(ドキュメントID)によって識別される。
- 階層構造: ドキュメント内にはさらにサブコレクションを作成することができ、関連するデータを親子関係のような階層構造で効率的に整理することが可能。
