ヒープ領域
リスト処理のようなプログラムでは、データを覚える領域は、関数が終わった後も使われる領域なので、局所変数のように「関数が終わったらそのデータの場所が不要になる」といったLast In First Out のようなスタックで管理することは難しい。
データを確保したメモリがどの時点まで使われるのか解らない場合、スタック構造を使うことはできない。こういったデータは、ヒープメモリ(ヒープ領域)を用いる。
C言語であれば、ヒープメモリの場所の確保には malloc() 関数が用いられ、不要となった時に free() 関数でメモリの開放が必要である。free() を忘れたプログラムが、ずっと動いた状態になると再利用されないメモリ領域が発生(メモリリーク)し、その領域が大量になると、他のプログラムに悪影響がでてくる。(最悪、仮想メモリの利用でスワッピングが多発するかもしれない)
#include <stdio.h>
#include <stdlib.h>
struct A { // class A {
int data ; // int data ;
} ; // }
int main() {
struct A * ptr = (struct A*)malloc( sizeof( struct A ) ) ;
// ptr = new A ;
ptr->data = 123 ;
// ptr.data = 123 ;
free( ptr ) ;
// Javaでは free() は不要
return 0 ;
}
C言語のmalloc() + free()は、Javaならnew … で記述するが free() に相当する処理は不要
import java.util.*;
class A {
int data ;
A( int x ) { this.data = x ; }
} ;
public class Main {
public static void main(String[] args) {
A a = new A( 123 ) ;
} // main が終わると、a が廃棄される
}
共有の発生したデータの扱い
C言語では、ヒープメモリの管理するには色々と複雑なことが発生する。
例えば、以下のようなリストの和集合のプログラムをC言語とJavaで示す。
このプログラムでは、リスト a, b の和集合を c に代入している。また、不要となったリストを捨てるために list_free() という関数を作成している。ただし Java では、不要となったメモリ領域の開放は不要だが、C言語との対比のために next に null を代入する処理で代用してある。
#include <stdio.h>
#include <stdlib.h>
struct List {
int data ;
struct List* next ;
} ;
struct List* newListNode( int x , struct List* p ) {
struct List* ans = (struct List*)malloc( sizeof( struct List ) ) ;
if ( ans != NULL ) {
ans->data = x ;
ans->next = p ;
}
return ans ;
}
void list_print( struct List* p ) {
for( ; p != NULL ; p = p->next )
printf( "%d " , p->data ) ;
printf( "\n" ) ;
}
int find( struct List* p , int key ) {
for( ; p != NULL ; p = p->next )
if ( p->data == key )
return 1 ;
return 0 ;
}
struct List* list_union( struct List* a , struct List* b ) {
struct List* ans = a ;
for( ; b != NULL ; b = b->next )
if ( !find( a , b->data ) )
ans = newListNode( b->data , ans ) ;
return ans ;
}
void list_free( struct List* p ) {
if ( p != NULL ) {
list_free( p->next ) ;
printf( "*%d " , p->data ) ;
free( p ) ;
}
}
int main(void){
struct List* a = newListNode( 11 , newListNode( 22 , NULL ) ) ;
struct List* b = newListNode( 11 , newListNode( 33 , NULL ) ) ;
struct List* c = list_union( a , b ) ;
list_print( a ) ;
list_print( b ) ;
list_print( c ) ;
list_free( c ) ;
list_free( b ) ;
list_free( a ) ;
return 0 ; // free(): double free detected in tcache 2
// Aborted (core dumped)
}
import java.util.*;
class ListNode {
int data ;
ListNode next ;
ListNode( int x , ListNode p ) {
this.data = x ;
this.next = p ;
}
}
public class Main {
public static void list_print( ListNode p ) {
for( ; p != null ; p = p.next )
System.out.print( p.data + " " ) ;
System.out.println() ;
}
public static boolean find( ListNode p , int key ) {
for( ; p != null ; p = p.next )
if ( p.data == key )
return true ;
return false ;
}
public static ListNode list_union( ListNode a , ListNode b ) {
ListNode ans = a ;
for( ; b != null ; b = b.next )
if ( !find( a , b.data ) )
ans = new ListNode( b.data , ans ) ;
return ans ;
}
public static void list_free( ListNode p ) {
if ( p != null ) {
list_free( p.next ) ;
System.out.print( "*" + p.data + " " ) ;
p.next = null ;
}
}
public static void main(String[] args) throws Exception {
ListNode a = new ListNode( 11 , new ListNode( 22 , null ) ) ;
ListNode b = new ListNode( 11 , new ListNode( 33 , null ) ) ;
ListNode c = list_union( a , b ) ; // 33,11,22
list_print( a ) ;
list_print( b ) ;
list_print( c ) ;
list_free( c ) ; System.out.println() ;
list_free( b ) ; System.out.println() ;
list_free( a ) ;
}
}
このプログラムを実行すると、c には和集合のリストが出来上がるが、33の先のデータは a とデータの一部を共有している。
この状態で、リスト全体を消すための list_free(c); list_free(b); list_free(a); を実行すると、list_free(c) の時点で a の先のリストは解放されている。このため、list_free(a) を実行すると、解放済みのデータ領域をさらに解放する処理が行われるが、すでに存在していないデータを消す処理が実行できない。
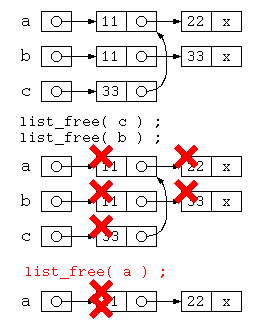 C言語のプログラムを動かすと、プログラム実行時にエラーが発生する。しかし、Java で書かれた「ほぼ同様」のプログラムは問題なく動作する。(以下に示す参照カウンタ法のおかげ)
C言語のプログラムを動かすと、プログラム実行時にエラーが発生する。しかし、Java で書かれた「ほぼ同様」のプログラムは問題なく動作する。(以下に示す参照カウンタ法のおかげ)
参照カウンタ法
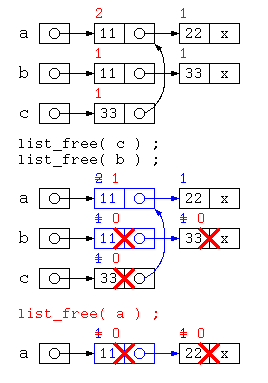
上記の問題は、a の先のリストが c の一部とデータを共有しているために発生する。この解決方法として簡単な方法では、参照カウンタ法が用いられる。
参照カウンタ法では、データを参照するポインタの数をデータと共に保存する。
- データの中にポインタ数を覚える参照カウンタを設け、データを生成した時に1とする。
- 処理の中で共有が発生すると、参照カウンタをカウントアップする。
- データを捨てる際には、参照カウンタをカウントダウンし、0になったら本当にそのデータを消す。
// 参照カウンタの説明用プログラム
class ListNode {
int refc ; // 参照カウンタ
int data ; // データ
ListNode next ; // 次のポインタ
ListNode( int x , ListNode p ) {
this.refc = 1 ; // 最初は参照カウンタ=1
this.data = x ;
this.next = p ;
}
} ;
public class Main {
public static ListNode copy( ListNode p ) {
p.refc++ ; // 共有が発生したら参照カウンタを増やす。
return p ;
}
// 集合和を求める処理
public static ListNode list_union( ListNode a , ListNode b )
{
ListNode ans = copy( a ) ;
// ~~~~~~~~~共有が発生するのでrefc++
for( ; b != null ; b = b.next )
if ( !find( ans , b.data ) )
ans = new ListNode( b.data , ans ) ;
return ans ;
}
public static void list_del( ListNode p ) { // 再帰で全廃棄
if ( p != null
&& --(p.refc) <= 0 ) { // 参照カウンタを減らし
// ~~~~~~~~~~
list_del( p.next ) ; // 0ならば本当に消す
free( p ) ;
}//~~~~~~~~~ Javaでは存在しない関数(説明用)
}
public static void main(String[] args) throws Exception {
ListNode a = new ListNode( 11 , new ListNode( 22 , null ) ) ;
ListNode b = new ListNode( 11 , new ListNode( 33 , null ) ) ;
ListNode c = list_union( a , b ) ;
// a,b,cを使った処理
// 処理が終わったのでa,b,cを捨てる
list_del( c ) ;
list_del( b ) ;
list_del( a ) ;
}
ただし、Java ではこういった処理を記述しなくても、内部で参照カウンタ法を実行しているため、このような処理を書く必要はない。
unix i-nodeで使われている参照カウンタ
unixのファイルシステムの基本的構造 i-node では、1つのファイルを別の名前で参照するハードリンクという機能がある。このため、ファイルの実体には参照カウンタが付けられている。unix では、ファイルを生成する時に参照カウンタを1にする。ハードリンクを生成すると参照カウンタをカウントアップ”+1″する。ファイルを消す場合は、基本的に参照カウンタのカウントダウン”-1″が行われ、参照カウンタが”0″になるとファイルの実体を消去する。
以下に、unix 環境で 参照カウンタがどのように使われているのか、コマンドで説明していく。
$ echo a > a.txt
$ ls -al *.txt
-rw-r--r-- 1 t-saitoh t-saitoh 2 12月 21 10:07 a.txt
~~~ # ここが参照カウンタの値
$ ln a.txt b.txt # ハードリンクでコピーを作る
$ ls -al *.txt
-rw-r--r-- 2 t-saitoh t-saitoh 2 12月 21 10:07 a.txt
-rw-r--r-- 2 t-saitoh t-saitoh 2 12月 21 10:07 b.txt
~~~ # 参照カウンタが増えているのが分かる
$ rm a.txt # 元ファイルを消す
$ ls -al *.txt
-rw-r--r-- 1 t-saitoh t-saitoh 2 12月 21 10:07 b.txt
~~~ # 参照カウンタが減っている
$ ln -s b.txt c.txt # シンボリックリンクでコピーを作る
$ ls -al *.txt
-rw-r--r-- 1 t-saitoh t-saitoh 2 12月 21 10:07 b.txt
lrwxrwxrwx 1 t-saitoh t-saitoh 5 12月 21 10:10 c.txt -> b.txt
$ rm b.txt # 元ファイルを消す
$ ls -al *.txt
lrwxrwxrwx 1 t-saitoh t-saitoh 5 12月 21 10:10 c.txt -> b.txt
$ cat c.txt # c.txt は存在するけどその先の実体 b.txt は存在しない
cat: c.txt: そのようなファイルやディレクトリはありません
ガベージコレクタ
では、循環リストの発生するようなデータで、共有が発生するような場合には、どのようにデータを管理すれば良いだろうか?
最も簡単な方法は、「処理が終わっても使い終わったメモリを返却しない」方法である。ただし、このままでは、メモリリークの発生でメモリを無駄に使ってしまう。
そこで、廃棄処理をしないまま、ゴミだらけになってしまったメモリ空間を再利用するのが、ガベージコレクタである。
ガベージコレクタは、貸し出すメモリ空間が無くなった時に起動され、
- すべてのメモリ空間に、「不要」の目印をつける。(mark処理)
- 変数に代入されているデータが参照している先のデータは「使用中」の目印をつける。(mark処理)
- その後、「不要」の目印がついている領域は、だれも使っていないので回収する。(sweep処理)
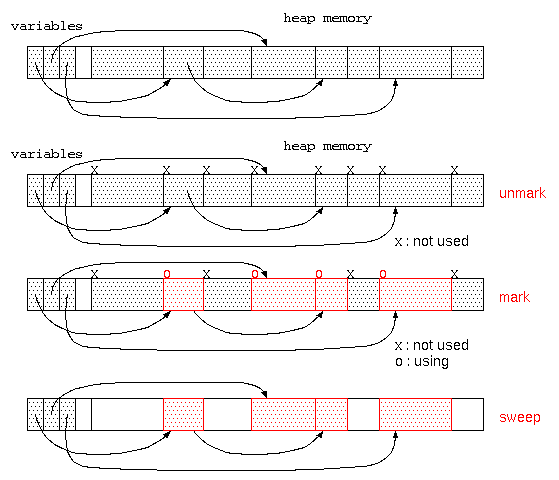
この方式は、マークアンドスイープ法と呼ばれる。ただし、このようなガベージコレクタが動く場合は、他の処理ができず処理が中断されるので、コンピュータの操作性という点では問題となる。
最近のプログラミング言語では、参照カウンタとガベージコレクタを取り混ぜた方式でメモリ管理をする機能が組み込まれている。このようなシステムでは、局所変数のような関数に入った時点で生成され関数終了ですぐに不要となる領域は、参照カウンタで管理し、大域変数のような長期間保管するデータはガベージコレクタで管理される。
大量のメモリ空間で、メモリが枯渇したタイミングでガベージコレクタを実行すると、長い待ち時間となることから、ユーザインタフェースの待ち時間に、ガベージコレクタを少しづつ動かすなどの方式もとることもある。
ガベージコレクタが利用できる場合、メモリ管理を気にする必要はなくなってくる。しかし、初心者が何も気にせずプログラムを書くと、使われないままのメモリがガベージコレクタの起動まで放置され、場合によっては想定外のタイミングでのメモリ不足による処理速度低下の原因となる場合もある。手慣れたプログラマーであれば、素早くメモリを返却するために、使われなくなった変数には積極的に null を代入するなどのテクニックを使う。他にも、関数内の局所変数も関数を抜ける際に不要となり、参照カウンタにより速やかにメモリを返却できる。