WWWとhttp
WWWとは、ティム・バーナーズ=リーによって作られたサービスであり、元々は研究データの論文やデータの共有のために作られた。この際のWebサーバのデータのやり取りのためのプロトコルがhttp(Hyper Text Transfer Protocol)であり、ポート番号80のTCPを用いたものであり、最近では通信を暗号化したhttps(ポート番号443)も多く使われる。
httpでは、文字データの中に画像や音声といった情報に加え、他のデータへのリンクを埋め込むことができる HTML(Hyper Text Markup Language) のデータがやりとりされる。このHTML形式のデータを表示するためのソフトは、ブラウザと呼ばれる。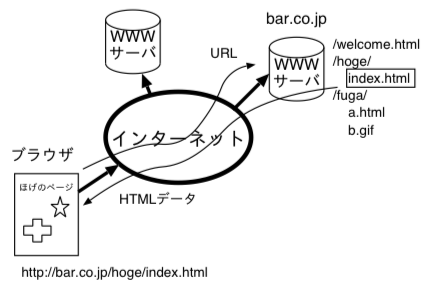
URL
WWWのデータの場所を示すものが、URL(Uniformed Resource Locator)であるが、最近ではインターネットが複雑化しLocator という表現が難しいため、URI(Uniformed Resource Identifier)と呼ぶようになってきた。
URLは基本的に、スキーマ://コンピュータ名/サーバ内ファイル位置 といった文字で構成される。URL は、HTTP だけでなく、インターネットの情報の場所を記述するために使われており、httpやhttps以外にも使う。

最近のブラウザは、スキーマ欄の”https://”やコンピュータ名の先頭の”www.”を省略することができる。また http は暗号通信を使わず危険であることから、警告メッセージが表示されたり、可能であれば https の通信に切り替えを試みられる。
http (Hyper Text Transfer Protocol) の流れ
httpのサーバ(Webサーバ)とブラウザでは、以下のような手順で処理が行われる。例えば http://www.ei.fukui-nct.ac.jp/~t-saitoh/index.html のページが表示されるまでを考えると、
- ブラウザのURL欄に、目的サイトのURLを入力。
- 基本的には、スキーマ欄に記載されたプロトコル(http)名から、ポート番号と通信方法(http)を決める。一般的な http 通信では、ポート番号には 80 を使う。
- コンピュータ名部分(www.ei.fukui-nct.ac.jp)を DNS に問合せして、得られたIPアドレスのコンピュータに接続。
- httpの最も簡単な GET メソッドでは、Webサーバに、サーバ内のファイル位置(/~t-saitoh/index.html)を伝えると、Webサーバは応答ヘッダ情報と応答本文の指定された場所のファイルの内容を返送する。(下図参照)
- HTML形式のデータが指定された場合、ブラウザはその HTML をどの様に表示するか判断しながら表示する。

このような予め保存されているWebページを返送する場合は静的ページと呼ばれる。サーバのデータベースなどを参照しながらページ内容を返送する場合は、動的ページと呼ばれ、Webサーバ内部でプログラムを動作させ、その結果のデータをブラウザに返す。
![]()
動的ページを生成するためのプログラム言語としては、様々な方法がある。(バックエンド言語)
- 言語 Perl による CGI(Common Gateway Interface)
- Webに特化した言語PHP

- サーバで 言語 Java を使ってページデータを生成(Apache Tomcat)
- サーバで 言語 JavaScript を使ってページデータを生成(Node.js)
![]()
また、最近のブラウザでは JavaScript を使って、Webページに表示される内容を動的に変化させることが多い。(フロントエンド)
https
httpでは、通信が平文で行われるため、同じサブネット内であれば通信内容を盗み見られる可能性がある。この通信を暗号化しながら行われるものが https である。ポート番号には一般的に 443 が使われる。暗号化通信は次週以降に説明を行う。
サーチエンジン
インターネットでは、大量のWebページが出現してきたため、自分の目的に応じてWebページを探す機能が必要となってきた。このような目的のWebページを検索してくれるシステムは、サーチエンジンと呼ばれる。
ディレクトリ型
最初に現れた検索システムは、ページ作者が自分のページのURLと内容となるキーワードをサーチエンジンに登録しておき、内容のカテゴリー別に、ページの紹介文章が表示されるディレクトリ型であった。(初期のYahoo)
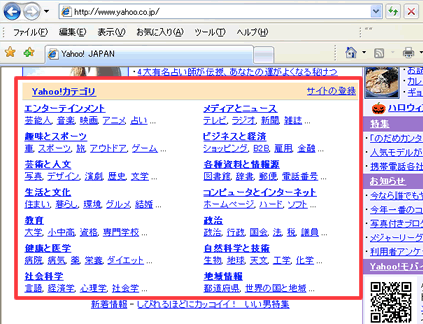
しかし、登録するキーワード以外の文字で探そうとすると、情報を見つけることができない。
ロボット型
これらの問題を解決すべく登場したのが、Google のようなロボット型サーチエンジンである。
ロボット型の検索システムでは、クローラーとかロボット(あるいはボット)とか呼ばれるプログラムを使い、Webページの内容をダウンロードし、そこに記載された文字を使ってURLのデータベースを作成する。
- 与えられた URL の先のページをダウンロードする。
- ページ内の文字を単語に切り分けして、それぞれの単語とURLを関連付けてデータベースに保存
- ページ内にリンクが含まれていたら、そのURLで、この作業を再帰的に繰り返す。
サーチエンジンで検索が行われると、クローラーの処理で作られたデータベースに問い合わせ、見つかったURLの情報を表示する。
Googleなどでは、多くのユーザが探したいページを提供するために、たくさん使われている単語を重要語としたり、たくさんのページからリンクされているページを表示順上位に表示するような工夫をしている。
ページランキングを上げるためのWebページの工夫をすることを、SEO (Search Engine Optimization) という。しかし逆にページランキングを不当に上げようと特殊なテクニックのページ作りをする人もいるが、最近では不当なページ作りは逆にランキングが落とされるようになっている。
理解度確認
- URLが与えられてページが見れるまでに行われることを説明せよ。
- サーチエンジンのディレクトリ型とロボット型の違いを説明せよ。