専攻科インターンシップ報告会
今日、専攻科のインターンシップ報告会が開催されました。
 資料は、お世話になった企業の情報で問題があるかもしれないので、解像度を落とし雰囲気のみということで…
資料は、お世話になった企業の情報で問題があるかもしれないので、解像度を落とし雰囲気のみということで…2分探索木
配列やリスト構造のデータの中から、目的となるデータを探す場合、配列であれば2分探索法が用いられる。これにより、配列の中からデータを探す処理は、O(log N)となる。
// 2分探索法
int array[ 8 ] = { 11, 13 , 27, 38, 42, 64, 72 , 81 } ;
int bin_search( int a[] , int key , int L , int R ) {
// Lは、範囲の左端
// Rは、範囲の右端+1 (注意!!)
while( R > L ) {
int m = (L + R) / 2 ;
if ( a[m] == key )
return key ;
else if ( a[m] > key )
R = m ;
else
L = m + 1 ;
}
return -1 ; // 見つからなかった
}
void main() {
printf( "%d¥n" , bin_search( array , 0 , 8 ) ) ;
}
一方、リスト構造ではデータ列の真ん中のデータを取り出すのにO(N)の処理時間がかかるため、先頭からデータを探すため、O(N)となってしまい、極めて効率が悪い。リスト構造でもっとデータを高速に探すことはできないものか?
2分探索木
ここで、データを探すための効率の良い方法として、2分探索木(2分木)がある。以下の木のデータでは、分離する部分に1つのデータと、左の枝(下図赤)と右の枝(下図青)がある。
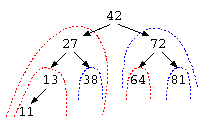
この枝の特徴は何だろうか?この枝では、中央のデータ例えば42の左の枝には、42未満の数字の枝葉が繋がっている。同じように、右の枝には、42より大きな数字の枝葉が繋がっている。この構造であれば、64を探したいなら、42より大きい→右の枝、72より小さい→左の枝、64が見つかった…と、いう風にデータを探すことができる。
特徴としては、1回の比較毎にデータ件数は、(N-1)/2件に減っていく。この方法であれば、O(log N)での検索が可能となる。これを2分探索木とよぶ。
このデータ構造をプログラムで書いてみよう。
struct Tree {
struct Tree* left ;
int data ;
struct Tree* right ;
} ;
// 2分木を作る補助関数
struct Tree* tcons( struct Tree* L ,
int d ,
struct Tree* R ) {
struct Tree* n = (struct Tree*)malloc(
sizeof( struct Tree ) ) ;
if ( n != NULL ) {
n->left = L ;
n->data = d ;
n->right = R ;
}
return n ;
}
// 2分探索木よりデータを探す
int tree_search( struct List* p , int key ) {
while( p != NULL ) {
if ( p->data == key )
return key ;
else if ( p->data > key )
p = p->left ;
else
p = p->right ;
}
return -1 ; // 見つからなかった
}
struct Tree* top = NULL ;
void main() {
top = tcons( tcons( tcons( NULL , 13 , NULL ) ,
27 ,
tcons( NULL , 38 , NULL ) ) ,
42 ,
tcons( tcons( NULL , 64 , NULL ) ,
72 ,
tcons( NULL , 81 , NULL ) ) ) ;
printf( "%d¥n" , tree_search( top , 64 ) ) ;
}
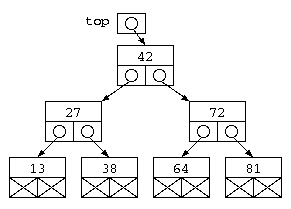
この方式の注目すべき点は、struct Tree {…} で宣言しているデータ構造は、2つのポインタと1つのデータを持つという点では、双方向リストとまるっきり同じである。データ構造の特徴の使い方が違うだけである。
2分木に対する処理
2分探索木に対する簡単な処理を記述してみよう。
// データを探す
int search( struct Tree* p , int key ) {
// 見つかったらその値、見つからないと-1
while( p != NULL ) {
if ( p->data == key )
return key ;
else if ( p->data > key )
p = p->left ;
else
p = p->right ;
}
return -1 ;
}
// データを全表示
void print( struct Tree* p ) {
if ( p != NULL ) {
print( p->left ) ;
printf( "%d¥n" , p->data ) ;
print( p->right ) ;
}
}
// データ件数を求める
int count( struct Tree* p ) {
if ( p == NULL )
return 0 ;
else
return 1
+ count( p->left )
+ count( p->right ) ;
}
// データの合計を求める
int sum( struct Tree* p ) {
if ( p == NULL )
return 0 ;
else
return p->data
+ count( p->left )
+ count( p->right ) ;
}
// データの最大値
int max( struct Tree* p ) {
while( p->right != NULL )
p = p->right ;
return p->data ;
}
データベースの用語など
データベースの機能
データベースを考える時、利用者の視点で分類すると、(1) データベースの管理者(データベース全体の管理)、(2) 応用プログラマ(SQLなどを使って目的のアプリケーションに合わせた処理を行う)、(3) エンドユーザ(データベース処理の専門家でなく、DBシステムのGUIを使ってデータベースを操作する)となる。
データベース管理システム(DBMS)では、データとプログラムを分離してプログラムを書けるように、データ操作言語(SQL)で記述する。
また、データは独立して扱えるようにすることで、データへの物理的なアクセス方法があっても、プログラムの変更が不要となるようにします。
データベースは、利用者から頻繁に不定期にアクセスされる。このため、データの一貫性が重要となる。これらを満たすためには、(a) データの正当性の確認、(b) 同時実行制御(排他制御)、(c) 障害回復の機能が重要となる。
これ以外にも、データベースからデータを高速に扱えるためには、検索キーに応じてインデックスファイルを管理してくれる機能や、データベースをネットワーク越しに使える機能などが求められる。
データベースに対する視点
実体のデータをそれぞれの利用者からデータベースを記述したものはスキーマと呼ばれる。そのスキーマも3つに分けられ、これを3層スキーマアーキテクチャと呼ぶ。
- 外部スキーマ – エンドユーザからどんなデータに見えるのか
- 概念スキーマ – 応用プログラマからは、どんな表の組み合わせで見えるのか、表の中身はどんなものなのか。
- 内部スキーマ – データベース管理者から、どんなファイル名でどんな形式でどう保存されているのか
データモデル
データを表現するモデルには、いくつかのモデルがある。
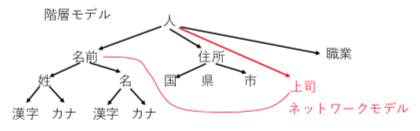
- 階層モデル – 木構造で枝葉に行くにつれて細かい内容
- ネットワークモデル – データの一部が他のデータ構造と関係している。
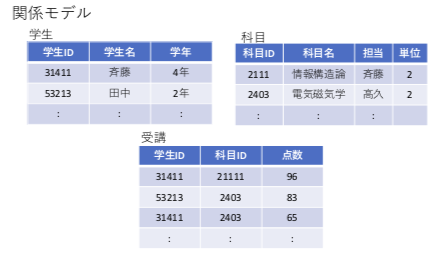
- 関係モデル – すべてを表形式で表す
データベースの基礎
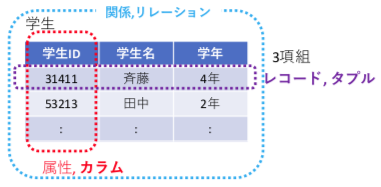
データベースは、1970年頃に、E.F.コッド博士によりデータベースのための数学的な理論が確立された。
- 集合 A, B – 様々なデータ
- 直積 A✕B = { (x,y) | x∈A , y∈B } 集合A,Bのすべての組み合わせ
- 関係 R(A,B) すべての組み合わせのうち、関係があるもの。直積A,Bの部分集合
例えば、A={ s,t,u } , B={ p,q } (定義域) なら、
A✕B = { (s,p) , (s,q) , (t,p) , (t,q) , (u,p) , (u,q) }
このうち、Aが名前(sさん,tさん,uさん)、Bが性別(p=男性,q=女性)を表すなら、
R(A,B) = { (s,p) , (t,q) , (u,p) } (例)
(例):(sさん,男性) , (tさん,女性) , (uさん,男性)
理解確認
- データベースにおける3層スキーマアーキテクチャについて説明せよ
- 集合A,Bが与えられた時、関係R(A,B) はどのようなものか、数学定義や実例をあげて説明せよ。
2018キャンパスリサーチ
今日は、福井高専の2回目のオープンキャンパス。夏の1回目は全学科の見学形式でしたが、今回は、2学科に絞って講座形式で専門的な体験をしてもらいます。
電子情報工学科では、IchigoJamを使ったプログラム体験です。


情報ネットワーク基礎・ガイダンス
シラバス:情報ネットワーク基礎
情報ネットワーク基礎では、インターネットがどのような仕組みなのか、どのようにして動いているのかを説明する。TCP/IPって何? IPアドレスって何? セキュリティって何?
あなたが使っているネットワーク機能は?
共有:ネットワークプリンタ、ファイル共有…
(ハードウェアや情報を共有)
分散:大量のコンピュータで負荷分散、リスク分散…
(仕事を分散し全体で高速化, 沢山のコンピュータの1台が壊れても全体は動く)
ネットワークの歴史
昔のコンピュータは、開発にお金がかかるため1台のコンピュータを全員で使うもの(TSS: Time Sharing System)だった。冷戦の時代、軍の重要な処理を行うコンピュータでは、コンピュータのある所に核攻撃を加えられ、軍の機能がすべて動かなくなることは問題だった。1970年頃にアメリカ国防総省ARPANETがインターネットの原型(TCP/IP)を作る。
1980年代には、パソコンがインターネットで繋がるようになる(LAN)。1990年代には、LANどうしを遠隔地接続をするWANが発達。欧州原子核研究機構(CERN)で、ティム・バーナーズ=リーがWorld Wide Web/httpを開発(1989)。1995年、マイクロソフトの家庭用パソコンのOS Windows95の普及と共にWWWが普及する。
※1980年代:パソコン通信、1997年:weblog,1998年:Google検索、1999年:2ch、2002年:SNSの誕生、2006年:Twitter,Facebook(一般開放)
コンピュータインタフェースとネットワーク(物理層)
ネットワークにおける情報伝達において、伝送媒体(電気信号,光)にて0/1を伝えるための取り決めは、物理層という。まずは、コンピュータと機器の接続について考えると、シリアル通信とパラレル通信に分類できる。
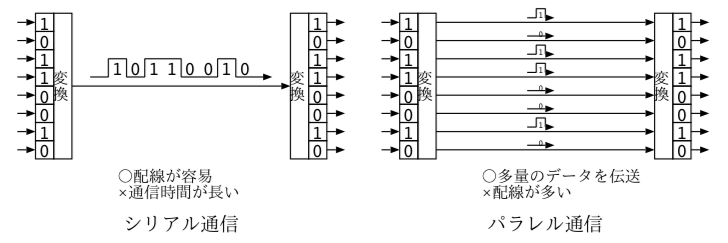
通信の高速化に伴い、伝送の配線はコンデンサやインダクタンスを考慮したインピーダンスマッチングが重要となる。このため、高速通信のインタフェース両端は終端抵抗(ターミネータ)が必要だった。
パラレル通信の例:パラレルポート(プリンタ用)IEEE 1284、ハードディスクATA(IDE)、計測器GP-IB
シリアル通信の例:RS-232C、USB1.1、IEEE1394(FireWire)、USB2.0、USB3.0、Ethernet
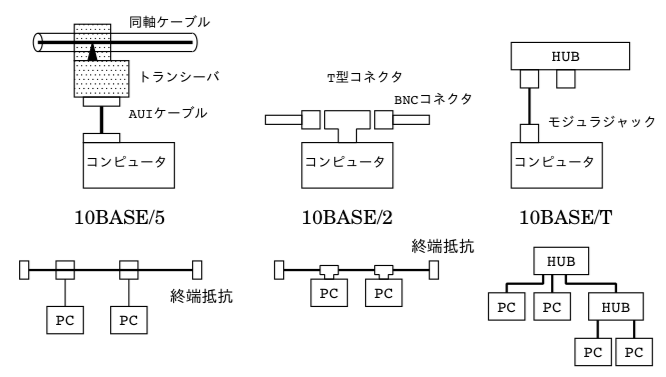
Ethernetの種別
- 10Mbit/sec通信
- 10BASE/5 – ケーブルに針を刺して増設
- 10BASE/2 – T型BNCケーブルで延長
- 10BASE/T – HUBで分配(終端抵抗などの問題はHUBが解決してくれる)
- 100BASE-T
- 1000BASE-T ギガビット
- 10000BASE , 10GBase
理解確認
- ネットワークにおける共有と分散について例をあげて説明せよ。
- TSSのような通信によるコンピュータと、TCP/IPによる通信網を比べ何がどう良いのか?
- シリアル通信とパラレル通信、それぞれの利点欠点は?
- 10BASE/5,10BASE/2,10BASE/Tのそれぞれの問題点は?
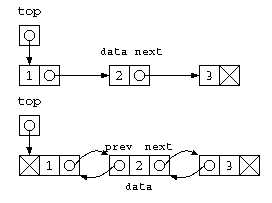
双方向リスト
単純リストから双方向リストへ
ここまで説明してきた単純リストは、次のデータへのポインタを持つ。ここで、1つ後ろのデータ(N番目からN+1番目)をアクセスするのは簡単だけど、1つ前のデータ(N-1番目)を参照しようと思ったら、先頭から(N-1)番目を辿るしかない。でも、これは O(N) の処理であり時間がかかる処理。
ではどうすればよいのか?
この場合、一つ前のデータの場所を覚えているポインタがあれば良い。
// 双方向リストの宣言
struct BD_List {
struct BD_List* prev ; // 1つ前のデータへのポインタ
int data ;
struct BD_List* next ; // 次のデータへのポインタ
} ;
このデータ構造は、双方向リスト(bi-directional list)と呼ばれる。では、簡単なプログラムを書いてみよう。双方向リストのデータを簡単に生成するための補助関数から書いてみる。
// リスト生成補助関数
struct BD_List* bd_cons( struct BD_List* p ,
int d ,
struct BD_List* n ) {
struct BD_List* ans ;
ans = (struct BD_List*)malloc(
sizeof( struct BD_List ) ) ;
if ( ans != NULL ) {
ans->prev = p ;
ans->data = d ;
ans->next = n ;
}
return ans ;
}
void main() {
struct BD_List* top ;
struct BD_List* p ;
// 順方向のポインタでリストを生成
top = bd_cons( NULL , 1 ,
bd_cons( NULL , 2 ,
bd_cons( NULL , 3 , NULL ) ) ) ;
// 逆方向のポインタを埋める
top->next->prev = top ;
top->next->next->prev = top->gt;next ;
// リストを辿る処理
for( p = top ; p->next != NULL ; p = p->next )
printf( "%d\n" , p->data ) ;
for( ; p->prev != NULL ; p = p->prev )
printf( "%d\n" , p->data ) ;
}
双方向リストの関数作成
以上の説明で、双方向の基礎的なプログラムの意味が分かった所で、練習問題。
先のプログラムでは、1,2,3 を要素とするリストを、ナマで記述していた。実際には、どんなデータがくるか分からないし、指定したポインタ p の後ろに、データを1件挿入する処理 bd_insert( p , 値 ) , また、p の後ろのデータを消す処理 bd_delete( p ) を書いてみよう。
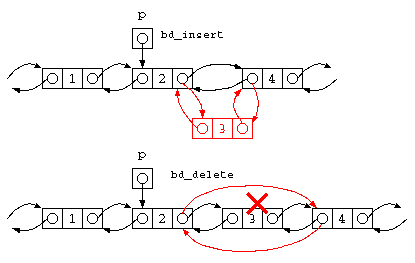
// 双方向リストの指定場所 p の後ろに、値 d を要素とするデータを挿入せよ。
void bd_insert( struct BD_List* p , int d ) {
struct BD_List*n = bd_cons( p , d , p->next ) ;
if ( n != NULL ) {
p->next->prev = n ;
p->next = n ;
}
}
// 双方向リストの指定場所 p の後ろのデータを消す処理は?
void bd_delete( struct BD_List* p ) {
struct BD_List* d = p->next ;
d->next->prev = p ;
p->next = d->next ;
free( d ) ;
}
// この手のリスト処理のプログラムでは、命令の順序が重要となる。
// コツとしては、修正したい箇所の遠くの部分を操作する処理から
// 書いていくと間違いが少ない。
番兵と双方向循環リスト
前述の bd_insert() だが、データの先頭にデータを挿入したい場合は、どう呼び出せば良いだろうか?
bd_insert() で、末尾にデータを挿入する処理は、正しく動くだろうか?
同じく、bd_delete() だが、データの先頭のデータを消したい場合は、どう呼び出せば良いだろうか?
また、データを消す場合、最後の1件のデータが消えて、データが0件になる場合、bd_delete() は正しく動くだろうか?
こういった問題が発生した場合、データが先頭・末尾で思ったように動かない時、0件になる場合に動かない時、特別処理でプログラムを書くことは、プログラムを読みづらくしてしまう。そこで、一般的には 循環リストの時にも紹介したが、番兵(Sentinel) を置くことが多い。
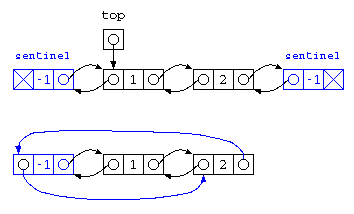
しかし、先頭用の番兵、末尾用の番兵を2つ用意するぐらいなら、循環リストにした方が便利となる。このような双方向リストでの循環した構造は、双方向循環リスト(bi-directional ring list)と呼ばれる。
この双方向循環リストを使うと、(1)先頭にデータを挿入(unshift)、(2)先頭のデータを取り出す(shift)、(3)末尾にデータを追加(push)、(4)末尾のデータを取り出す(pop)、といった処理が簡単に記述できる。この4つの処理を使うと、単純リスト構造で説明した、待ち行列(queue)やスタック(stack) が実現できる。この特徴を持つデータ構造は、先頭・末尾の両端を持つ待ち行列ということで、deque (double ended queue) とも呼ばれる。
理解確認
- 双方向リストとはどのようなデータ構造か図を示しながら説明せよ。
- 双方向リストの利点と欠点はなにか?
- 番兵を用いる利点を説明せよ。
- deque の機能と、それを実現するためのデータをリストを用いて実装するには、どうするか?
- 双方向リストが使われる処理の例としてどのようなものがあるか?
2018データベース・ガイダンス
シラバス:2018年度データベースシラバス
インターネットの情報量
インターネット上の情報量の話として、2010年度に281EB(エクサバイト)=281✕1018B(参考:kMGTPEZY)で、今日改めて探したら、2013年度で、1.2 ZB(ゼタバイト)=1.2✕1021B という情報があった。ムーアの法則2年で2倍の概算にも、それなりに近い。 では、今年2018年であれば、どのくらいであろうか?
そして、これらの情報をGoogleなどで探す場合、すぐにそれなりに情報を みつけてくれる。これらは、どの様に実装されているのか?
Webシステムとデータベース
まず、指定したキーワードの情報を見つけてくれるものとして、 検索システムがあるが、このデータベースはどのようにできているのか?
Web創成期の頃であれば、Yahooがディレクトリ型の検索システムを構築 してくれている。(ページ作者がキーワードとURLを登録する方式) しかし、ディレクトリ型では、自分が考えたキーワードではページが 見つからないことが多い。
そこで、GoogleはWebロボット(クローラー)による検索システムを構築した。 Webロボットは、定期的に登録されているURLをアクセスし、 そのページ内の単語を分割しURLと共にデータベースに追加する。 さらに、ページ内にURLが含まれていると、そのURLの先で、 同様の処理を再帰的に繰り返す。
これにより、巨大なデータベースが構築されているが、これを少ない コンピュータで実現すると、処理速度が足りず、3秒ルール/5秒ルール (Web利用者は次のページ表示が3秒を越えると、次に閲覧してくれない) これを処理するには負荷分散が重要となる。
一般的に、Webシステムを構築する場合には、 1段:Webサーバ、2段:動的ページ言語、3段:データベースとなる場合も 多い。この場合、OS=Linux,Web=Apache,DB=MySQL,動的ページ生成言語=PHPの組合せで、 LAMP構成とする場合も多い。
一方で、大量のデータを処理するDBでは、フロントエンド,スレーブDB,マスタDBのWebシステムの3段スキーマ構成となることも多い。
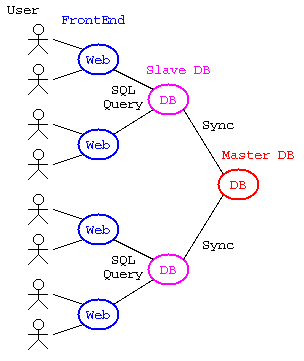
データベースシステム
データベースには、ファイル内のデータを扱うためのライブラリの、 BerkleyDBといった場合もあるが、複雑なデータの問い合わせを実現する 場合には、リレーショナル・データベース(RDB)を用いる。 RDBでは、データをすべて表形式であらわし、SQLというデータベース 問い合わせ言語でデータを扱う。 また、問い合わせは、ネットワーク越しに実現可能であり、こういった RDBで有名なものとして、Oracle , MySQL , PostgreSQL などがある。 単一コンピュータ内でのデータベースには、SQLite などがある。
データベースシステムと呼ばれるには、ACID特性が重要となる。
- A: 原子性 (Atomicity) – 処理はすべて実行するか / しない のどちらか。
- C: 一貫性 (Consistency) – 整合性とも呼ばれ、与えられたデータのルールを常に満たすこと。
- I: 独立性 (Isolation) – 処理順序が違っても結果が変わらない。それぞれの処理が独立している。
- D: 永続性 (Durability) – データが失われることがない(故障でデータが無くならないとか)
しかし、RDBでは複雑なデータの問い合わせはできるが、 大量のデータ処理のシステムでは、フロントエンドDB,スレーブDB,マスタDB の同期が問題となる。この複雑さへの対応として、最近は NoSQL が 注目されている。
データベースが無かったら
これらのデータベースが無かったら、どのようなプログラムを作る 必要があるのか?
情報構造論ではC言語でデータベースっぽいことをしていたが、 大量のデータを永続的に扱うのであれば、ファイルへのデータの読み書き 修正ができるプログラムが必要となる。
こういったデータをファイルで扱う場合には、1件のデータ長が途中で 変化すると、N番目のデータは何処?といった現象が発生する。 このため、簡単なデータベースを自力で書くには、1件あたりのデータ量を 固定し、lseek() , fwrite() , fread() などの 関数でランダムアクセスのプログラムを書く必要がある。
また、データの読み書きが複数同時発生する場合には、排他処理も 重要となる。例えば、銀行での預け金10万の時、3万入金と、2万引落としが 同時に発生したらどうなるか? 最悪なケースでは、 (1)入金処理で、残金10万を読み出し、 (2)引落し処理で、残金10万を読み出し、 (3)入金処理で10万に+3万で、13万円を書き込み、 (4)引落し処理で、残金10万-2万で、8万円を書き込み。 で、本来なら11万になるべき結果が、8万になるかもしれない。
さらに、コンピュータといってもハードディスクの故障などは発生する。 障害が発生してもデータの一貫性を保つためには、バックアップや 障害対応が重要となる。
ポインタと番地の理解
リスト構造とかのプログラミングでは、ポインタが使われるが、番地とポインタをうまく理解していないと、どのような処理をしているのか理解しづらいはず。
今回の補講では、ポインタを理解してもらう。
以下では、ポインタを使った処理(前半)を見て、ポインタの動きを考える。理解できていなければ、同じ処理をポインタ無し、番地を意識させる memory[] 配列による記述(後半)で、動きを追って2つのプログラムが同じ挙動を表している…という説明の繰り返しで、ポインタの理解を図る。
単純な変数の加算
プログラムで、「 c = a + b ; 」と書いてあったら、メモリの「変数aの番地の中身」と「変数bの番地の中身」を加えて、結果を「変数cの番地」に保存する。
// 変数 a と 変数b の加算
int a = 11 ;
int b = 22 ;
int c ;
c = a + b ;
// 同じ処理をメモリの番地のイメージを示す。
int memory[ 1000 ] = { 0 , 0 , 0 , 11 , 22 , 0 , 0 } ;
#define ADDR_A 3
#define ADDR_B 4
#define ADDR_C 5
memory[ ADDR_C ] = memory[ ADDR_A ] + memory[ ADDR_B ] ;
ポインタのイメージ
// ポインタの処理
int a = 11 ;
int b = 22 ;
int*p ;
p = &a ;
(*p)++ ;
p = &b ;
(*p)++ ;
// 同じ処理をメモリ番地のイメージで
int memory[ 1000 ] = { 0 , 0 , 0 , 11 , 22 , 0 , 0 } ;
#define ADDR_A 3
#define ADDR_B 4
int p ; // int *p ;
p = ADDR_A ; // p = &a ;
memory[ p ]++ ; // (*p)++ ;
p = ADDR_B ; // p = &b ;
memory[ p ]++ ; // (*p)++ ;
ポインタ渡し
// ポインタ引数による値の交換
void swap( int*x , int*y ) {
int tmp = *x ;
*x = *y ;
*y = tmp ;
}
void main() {
int a = 11 ;
int b = 22 ;
swap( &a , &b ) ;
}
// 同じ処理をメモリ番地のイメージで。
int memory[ 1000 ] = { 0 , 0 , 0 , 11 , 22 , 0 , 0 } ;
#define ADDR_A 3
#define ADDR_B 4
void swap( int x , int y ) { // void swap( int*x , int*y ) {
int tmp = memory[ x ] ; // int tmp = (*x) ;
memory[ x ] = memory[ y ] ; // (*x) = (*y) ;
memory[ y ] = tmp ; // (*y) = tmp ;
} // }
void main() {
swap( ADDR_A , ADDR_B ) ; // swap( &a , &b ) ;
}
上記のポインタの説明では、番地をintで表現しているから、型の概念が曖昧になりそう。
本当は、以下のように pointer 型を使って説明したいけど、補講の学生に typedef は、混乱の元だろうな。ひとまず、ここまでのポインタのイメージを再学習するネタを見てもらってからなら、typedef int pointer してもいいかな?typedef int pointer ; void swap( pointer x , pointer y ) { int tmp = memory[ x ] ; memory[ x ] = memory[ y ] ; memory[ y ] = tmp ; }プログラミングでは、型の理解が重要。たとえ、Python,Ruby といった型宣言の無い言語でも、どんなデータなのかを意識して書く必要がある。
理解の確認
// 以下のプログラムの実行結果は?
void foo( int x ) {
x++ ;
}
void bar( int*p ) {
(*p)++ ;
}
void main() {
int a = 111 ;
foo( a ) ; // a の中身は?
bar( &a ) ; // a の中身は?
}
// 同じ処理を
typedef int pointer ;
int memory[ 1000 ] = { 0 , 0 , 0 , 111 , 0 , 0 } ;
#define ADDR_A 3
void foo( int x ) {
_______________________ ;
}
void bar( pointer p ) {
_______________________ ;
}
void main() {
foo( ________________ ) ; // memory[ ADDR_A ] の中身は?
bar( ________________ ) ; // memory[ ADDR_A ] の中身は?
}
ポインタと配列
// ポインタの移動
int sum = 0 ;
int array[ 3 ] = { 11 , 22 , 33 } ;
int*p ;
p = array ;
sum += *p ;
p++ ;
sum += *p ;
p++ ;
sum += *p ;
// 同じ処理をメモリ番地のイメージで
typedef int pointer ;
int memory[ 1000 ] = { 0 , 0 , 0 , 11 , 22 , 33 , 0 , 0 } ;
#define ADDR_SUM 2
#define ARRAY 3
pointer p ; // int*p ;
p = ARRAY ; // p = array ;
memory[ ADDR_SUM ] += memory[ p ] ; // sum += (*p) ;
p++ ; // p++ ;
memory[ ADDR_SUM ] += memory[ p ] ; // sum += (*p) ;
p++ ; // p++ ;
memory[ ADDR_SUM ] += memory[ p ] ; // sum += (*p) ;
理解の確認
整数配列にデータが並んでいる。数字は0以上の数字で、データ列の後ろには必ず0が入っているものとする。配列の先頭から0を見つけるまでの値を合計する関数を作れ。
int sum( int*p ) {
s = 0 ;
for( __________ ; __________ ; __________ ) {
____________________ ;
}
return s ;
}
int array_a[ 4 ] = { 11 , 22 , 33 , 0 } ;
int array_b[ 5 ] = { 4 , 3 , 2 , 1 , 0 } ;
void main() {
printf( "%d\n" , sum( array_a ) ) ; // 66 を表示
printf( "%d\n" , sum( brray_b ) ) ; // 10 を表示
printf( "%d\n" , sum( array_a + 1 ) ) ; // 何が表示される?
}
リスト構造
では、最後のシメということで、リスト構造でのポインタのイメージの確認。
// リストを次々たどる処理
struct List {
int data ;
struct List* next ;
} ;
struct List* cons( int x , struct List* p ) {
struct List* ans =
(struct List*)malloc( sizeof( struct List ) ) ;
if ( ans != NULL ) {
ans->data = x ;
ans->next = p ;
}
return ans ;
}
void main() {
struct List* top =
cons( 11 , cons( 22 , cons( 33 , NULL ) ) ) ;
struct List* p ;
for( p = top ; p != NULL ; p = p->next ) {
printf( "%d¥n" , p->data ) ;
}
}
// メモリのイメージで
typedef int pointer ;
int memory[ 1000 ] = {
0 , 0 ,
22 , 6 ,
11 , 2 ,
33 , 0 ,
0 , 0 ,
} ;
#define OFFSET_DATA 0
#define OFFSET_NEXT 1
void main() {
pointer p ;
for( p = 4 ; p != 0 ; p = memory[ p + OFFSET_NEXT ] ) {
printf( "%d¥n" , memory[ p + OFFSET_DATA ] ) ;
}
}
授業アンケート(前期修了)
2018年度前期修了科目の授業アンケート。
オブジェクト指向プログラミング(専攻科)
専攻科オブジェクト指向は、80.5 で前年度ともあまり変わらないポイント。
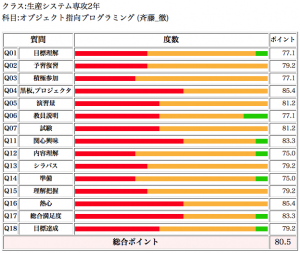
板書については、Webに授業資料を公開しながらの授業であったため、評価が高かった。興味と関心についても評価が高い一方で、内容理解についてはポイントも低く、レポートなどを見ていると、プログラミングが苦手な人の参加も多かったように思う。もう少し理解に割く時間を増やしても良かったかもしれない。準備についての評価が低い。Web資料も準備しながらなので、準備はもう少し高いことを期待していた。
情報制御基礎(3年学際科目)
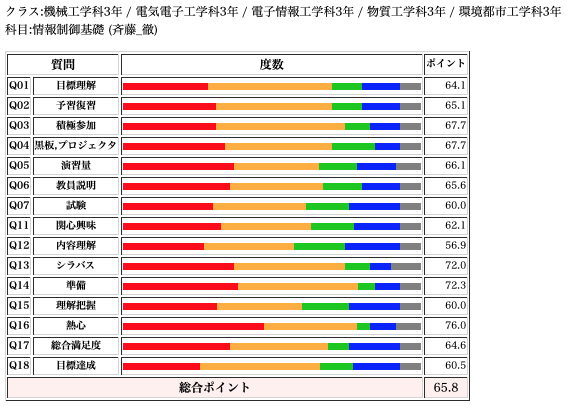
今年初めて実施の学際科目で、他学科の学生も受講する内容。このため、プログラミング経験の浅いM,C,Bの学生には、厳しい内容だった。しかし、情報制御という授業でプログラミング無しで、簡単なデータ処理を行うために2重forループも分からないのでは、授業で教える内容が無い。最初のガイダンスで、選択科目だしプログラミングが苦手なら受講を避けるようにすべきだったと思う。
学科サイトを安全に保護されたページに
最近のWebページでの SSL 接続必須の状況の中、メジャーなブラウザは https 接続が不完全だと、ページURL横の🔒マークが表示されなくなってきている。
その中で、学科のページも https の SSL 鍵なども登録していたけど、久々にページを確認したら🔒マークが消えている。原因は、サイドメニューにプロコン公式ページへのリンクのためのバナー画像を http で表示させていた。かといって、プロトコル欄を https に変更したら、プロコンのサイトが SSL 鍵が公式でなかった。
プロコンのページは電子情報では興味を持つ人も多いので、バナーアイコンをコピーしておくことにした。
![]()