コンパイラと関数電卓プログラム(専攻科実験2018)
専攻科1年・生産システム実験1(後期)の「コンパイラと関数電卓プログラム」の説明は、昨年度資料と共通なのでリンクを記載しておく。
意思決定木と構文解析
意思決定木
意思決定木の説明ということで、yes/noクイズの例を示しながら、2分木になっていることを 説明しプログラムを紹介。
((意思決定木の例:うちの子供が発熱した時)) 38.5℃以上の発熱がある? no/ \yes 元気がある? むねがひいひい? yes/ \no no/ \yes 様子をみる 氷枕で病院 解熱剤で病院 速攻で病院
このような判断を行うための情報は、yesの木 と noの木の2つの枝を持つデータである。これは2分木と同じであり、このような処理は以下のように記述ができる。
struct Tree {
char *qa ;
struct Tree* yes ;
struct Tree* no ;
} ;
struct Tree* dtree( char *s ,
struct Tree* l , struct Tree* r )
{ struct Tree* n ;
n = (struct Tree*)malloc( sizeof( struct Tree ) ) ;
if ( n != NULL ) {
n->qa = s ;
n->yes = l ;
n->no = r ;
}
return n ;
}
void main() {
struct Tree* p =
dtree( "38.5℃以上の発熱がある?" ,
dtree( "胸がひぃひぃ" ,
dtree( "速攻で病院",NULL,NULL ) ,
dtree( "解熱剤で病院",NULL,NULL ) ) ,
dtree( "元気がある?" ,
dtree( "様子をみる",NULL,NULL ) ,
dtree( "氷枕で病院",NULL,NULL ) ) ) ;
struct Tree* d = p ;
while( d->yes != NULL || d->no != NULL ) {
printf( "%s¥n" , d->qa ) ;
scant( "%d" , &ans ) ;
if ( ans == 1 )
d = d->yes ;
else if ( ans == 0 )
d = d->no ;
}
printf( "%s¥n" , d->qa ) ;
}
コンパイラと言語処理系
高級言語で書かれたプログラムを計算機で実行するソフトウェアは、言語処理系と呼ばれる。その実行形式により
- インタプリタ(interpreter:翻訳)
- ソースプログラムの意味を解析しながら、その意味に沿った処理を行う
- コンパイラ(compiler:通訳)
- ソースプログラムから機械語を生成し、実行する際には機械語を実行
- トランスコンパイラ:ソースから他の言語のソースコードを生成し、それをさらにコンパイルし実行
- バイトコードインタプリタ:ソースからバイトコード(機械語に近いコードを生成)、実行時にはバイトコードの命令に沿った処理を行う
に分けられる。
コンパイラが命令を処理する際には、以下の処理が行われる。
- 字句解析(lexical analysys)
文字列を言語要素(token)に分解 - 構文解析(syntax analysys)
tokenの並び順に意味を反映した構造を生成 - 意味解析(semantics analysys)
命令に合わせた中間コードを生成 - 最適化(code optimization)
中間コードを変形して効率よいプログラムに変換 - コード生成(code generation)
実際の命令コードとして出力
バイトコードインタプリタとは
例年だと説明していなかったけど最近利用されるプログラム言語の特徴を説明。通常、コンパイラとかインタプリタの説明をすると、Java がコンパイラとか、JavaScript はインタプリタといった説明となる。しかし、最近のこういった言語がどのように処理されるのかは、特殊である。
(( Java の場合 )) foo.java (ソースコード) ↓ Java コンパイラ foo.class (中間コード) ↓ JRE(Java Runtime Engine)の上で 中間コードをインタプリタ方式で実行
あらかじめコンパイルされた中間コードを、JREの上で中間コードをインタプリタ的に実行するものは、バイトコードインタプリタ方式と呼ぶ。
ただし、JRE でのインタプリタ実行では遅いため、最近では JIT コンパイラにより、中間コードを機械語に変換してから実行する。
また、JavaScriptなどは(というか最近のインタプリタの殆どPython,PHP,Perl,…は)、一般的にはインタプリタに分類されるが、実行開始時に高級言語でかかれたコードから中間コードを生成し、そのバイトコードをインタプリタ的に動かしている。
しかし、インタプリタは、ソースコードがユーザの所に配布されて実行するので、プログラムの内容が見られてしまう。プログラムの考え方が盗まれてしまう。このため、変数名を短くしたり、空白を除去したり(…部分的に暗号化したり)といった難読化を行うのが一般的である。
トークンと正規表現(字句解析)
規定されたパターンの文字列を表現する方法として、正規表現(regular expression)が用いられる。
((正規表現の書き方)) 選言 「abd|acd」は、abd または acd にマッチする。 グループ化 「a(b|c)d」は、真ん中の c|b をグループ化 量化 パターンの後ろに、繰り返し何回を指定 ? 直前パターンが0個か1個 「colou?r」 * 直前パターンが0個以上繰り返す 「go*gle」は、ggle,gogle,google + 直前パターンが1個以上繰り返す 「go+gle」は、gogle,google,gooogle
正規表現は、sed,awk,Perl,PHPといった文字列処理の得意なプログラム言語でも利用できる。こういった言語では、以下のようなパターンを記述できる。
[文字1-文字2...] 文字コード1以上、文字コード2以下 「[0-9]+」012,31415,...数字の列 ^ 行頭にマッチ $ 行末にマッチ ((例)) [a-zA-Z_][a-zA-Z_0-9]* C言語の変数名にマッチする正規表現
構文とバッカス記法
言語の文法を表現する時、バッカス記法(BNF)が良く使われる。
((バッカス記法)) 表現 ::= 表現1... | 表現2... | 表現3... | ... ;
例えば、加減乗除記号と数字だけの式の場合、以下の様なBNFとなる。
((加減乗除式のバッカス記法))
加算式 ::= 乗算式 '+' 乗算式
| 乗算式 '-' 乗算式
| 乗算式
;
乗算式 ::= 数字 '*' 乗算式
| 数字 '/' 乗算式
| 数字
;
数字 ::= [0-9]+
;
上記のバッカス記法には、間違いがある。”1+2+3″を正しく認識できない。どこが間違っているだろうか?
このような構文が与えられた時、”1+23*456″と入力されたものを、“1,+,23,*,456”と区切る処理が、字句解析である。
また、バッカス記法での文法に合わせ、以下のような構文木を生成するのが構文解析である。
+ / \ 1 * / \ 23 456
理解度確認
- インタプリタ方式で、処理速度が遅い以外の欠点をあげよ。
- 情報処理技術者試験の正規表現,BNF記法問題にて理解度を確認せよ。
北陸イノベーショントライアルにてキャンパス部門優秀賞🎉

11月7日(火)に石川県立音楽堂で行われたHIT2018(第5回ビジネスモデル発見&発表会 北陸大会 および 起業家甲子園・起業家万博 北陸予選)に、福井高専の高専プロコンと専攻科学生による合同チームが参加し、キャンパス部門優秀賞と起業家甲子園挑戦権を獲得しました。

GROUP BY-HAVINGとCREATE VIEW
先週に引き続き、2つのSQLとそれと同じ処理のプログラム作成の課題に取り組む。
演習だけでは進度が少ないので、SQL で説明できなかった、GROUP BY-HAVING と CREATE VIEW の説明
GROUP BY HAVING
GROUP BY-HAVING では、指定されたカラムについて同じ値を持つレコードがグループ化される。SELECT 文に指定される集約関数は、グループごとに適用される。HAVING は、ある条件を満たす特定のグループを選択するための条件で、WHERE と違い、集約関数が使える。
SELECT SG.商品番号, SUM(SG.在庫量) FROM SG GROUP BY SG.商品番号 HAVING SUM(SG.在庫量) >= 500 ;
このSQLを実行すると、SG のテーブルから、商品番号が同じものだけをあつめてグループ化される。そのグループごとに在庫量のデータの合計SUMを集約し、500以上のデータが出力される。
CREATE VIEW
今までで述べてきたSQLでは、実際のテーブルを対象に、結合・選択・射影を行う命令であり、これは概念スキーマと呼ばれる、対象となるデータベース全体を理解したプログラマによって扱われる。
しかし、プログラムの分業化を行い、例えば結果の表示だけを行うプログラマにしてみれば、全てのデータベースの表を考えながらプログラムを作るのは面倒である。そこで、結合・選択・射影の演算の結果で、わかりやすい単純な表となったものであれば、初心者のデータベースプログラマでも簡単に結果を扱うことができる。このような外部スキーマを構成するための機能が、ビューテーブルである。
-- 優良業者テーブルを作る --
CREATE VIEW 優良業者 ( 業者番号 , 優良度 , 所在 )
AS SELECT S.業者番号, S.優良度, S.所在
FROM S
WHERE S.優良度 >= 15 ;
-- 優良業者テーブルから情報を探す --
SELECT *
FROM 優良業者
WHERE 優良業者.所在 = '福井' ;
ビューテーブルに対する SQL を実行すると、システムによっては予め実行しておいた CREATE VIEW の AS 以下の SQL の実行結果をキャッシュしておいて処理を行うかもしれない。システムによっては SQL の命令を 副クエリを組合せた SQL に変換し、処理を行うかもしれない。しかし、応用プログラマであれば、その SQL がどのように実行されるかは意識する必要はほとんど無いであろう。
ただし、ビューテーブルに対する 挿入・更新・削除といった演算を行うと、データによっては不整合が発生することもあるので注意が必要である。
debian で django を動かす
卒研で Django を debian なサーバで動かしたいので、メモ
Django をインストール
最初、起動に失敗したので、python3-pip を入れたら、無事に動き出した。
$ sudo aptitude install python3-django python3-pip
ユーザが Django を起動
$ cd # 自分のホームディレクトリに環境を構築 $ django-admin startproject myapp $ cd myapp $ python3 manage.py migrate $ python3 manage.py runserver 127.0.0.1:8000
卒研が進んで、うまく動くようになったら、service に登録して運用しよう。
専攻科交流会: お菓子デコレーション会
今週は3年生が研修旅行なので、真ん中の水曜は1,4年遠足(一応10kmウォーキング含む),2年研修(県内の企業見学),5年と専攻科は交流会となりました。私は、専攻科委員なので専攻科の交流会に参加しました。
お菓子デコレーション会

タイトル:「渋谷ハロウィーンでパリピに破壊される軽トラ」



SQLで集約関数と集合計算
特殊な条件演算子
WHERE 節の中で使える特殊な条件演算子を紹介する。
... IN ... WHERE S.業者番号 IN ( 'S1' , 'S4' ) ; ... BETWEEN A AND B WHERE S.優良度 BETWEEN 50 AND 100 ; ... LIKE ... WHERE S.業者名 LIKE 'A_C社' ; _ は任意の1文字 ABC社 ADC社 WHERE S.業者名 LIKE 'A%社' ; % は任意の0~N文字 A社, AA社 ABC社 ... IS NULL WHERE S.業者名 IS NULL
集約関数
集約関数は、SQL の SELECT の射影部分で使える関数で、出力対象となった項目に対して、COUNT(),SUM(),AVG()といった計算を行うもの。
COUNT() - 項目の数 SUM() - 項目の合計 AVG() - 項目の平均 MAX() - 項目の最大値 MIN() - 項目の最低値 SELECT COUNT(SG.業者番号) FROM SG WHERE SG.優良度 > 100 ;
集合計算
複数の SQL の結果に対し、集合和, 集合積, 集合差などの処理を行う。
... UNION ... 集合和 ... EXPECT ... 集合差 ... INTERSECT ... 集合積 SELECT S.業者名 FROM S WHERE S.所在 = '福井' UNION SELECT S.業者名 FROM S WHERE S.所在 = '東京'
高専プロコン2018本戦で大活躍🎉
毎年開催されている高専プロコンの 第29回 阿南 大会(徳島県阿南市)で、課題部門・自由部門・競技部門に10月27日,28日にかけて参加しました。
今年は、課題部門特別賞や競技部門3位と、優秀な成果を残すことができました。
サバ×サバ -サバで時代を生き延びる- (課題部門)
今年の課題は、「ICT を活用した地域活性化」です。

ポーズでプログラミング−動きで動くロボット− (自由部門)

自軍パネル破壊はテンポロス (競技部門)

競技部門は、善戦し決勝トーナメントに進み、
準決勝までのこり3位🎉となりました。
大学、大学院説明会
福井高専で進学希望者向けの、大学・大学院説明会が開催されました。専攻科向けの説明会では、電子情報OBの方も説明に参加してくれました。






Ethernet と CSMA/CD方式
CSMA/CD方式
Ethernet では、1本の線を共有するバス型であり、複数の機器が同時に信号を出力すると、電圧の高低がおかしい状態となる(衝突,コリジョン)ため、同時に信号を出さない工夫が必要となる。ただし、他の人が信号線を使っていないことを確認してから、信号を出せばいいけど、確認から信号を出すまでの遅延により、衝突を避けるのは難しい。
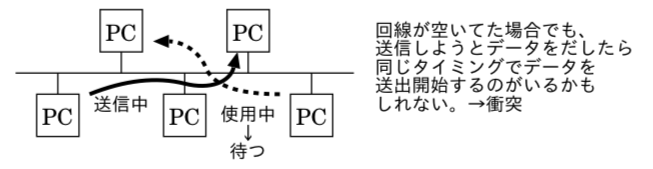
また、1本の線を共有する機器の数が増えてくると、衝突の発生の可能性が高まってくる。
これらの問題を解決するためのルールが CSMA/CD(Carrier Sense Multiple Access with Collision Detection)方式である。
- 機器は、信号を出す場合、信号線が空いている状態を待ち、出力を行う。
- もし、複数の機器が同時に信号を出した場合、電圧異常を検知したら衝突なので再送を試みる。
- 再送を行う場合には、乱数時間待つ。(機器が多い場合は、これでも衝突が起こるかもしれない)
- 乱数時間待っても信号線が空かない場合は、乱数時間の単位時間を倍にする。
どちらにしろ、バス共有する機器の台数が増えてくると、衝突の可能性は高まり、100台を越えるような状態は通信効率も悪くなる。
ただし、最近はスイッチングHUBで通信制御を行うことが一般的になり、CSMA/CD方式が使われることは減っている。
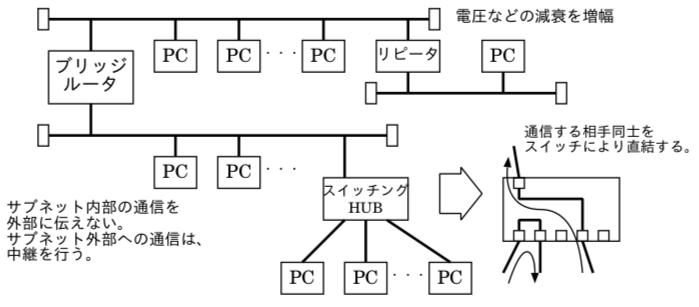
スイッチングHUB
*BASE-T のような、HUB による接続では、複数の機器が異なる機器どうしで通信をする場合、その通信路を時分割多重するのではなく、通信相手に応じて内部回路を直接つながるように接続するスイッチングHUB(以下SW-HUB)が普及している。
バス型通信では、1本の線を共有するため、同じネットワーク内の別機器間の通信は、傍受することができる(タッピング)。しかし、SW-HUB の場合、機器同士が直接つながるので、傍受するのが困難であり、セキュリティ的にも望ましい。
データリンク層とMACアドレス
前述のように、1つのバス型接続のネットワーク内部には、同時に設置できる機器の数には限界がある。このため、小さなネットワークに分割したもの(サブネット)を、ブリッジやルータで接続し、隣接するサブネットにサブネット内の通信情報が出ないように分割することを行う。
Ethernetに接続する機器は、機器ごとにユニークな番号(MACアドレス)を持っている。このMACアドレスは、8bit✕6個の48bitの値で、メーカー毎に割振られた範囲の値を、機器ごとに異なる値がついている。
通信は、一般的に1500byte程のパケットを単位として送受信が行われる。サブネット内の通信では、自分宛のパケットかどうかをMACアドレスを見て受け取る。これらのレイヤーは、データリンク層と呼ばれる。
旧式のHUB(Dumb HUB)は、電気的に信号を増幅するだけなので、物理層(レイヤー1)だけで通信を行う。
スイッチングHUBは、MACアドレスを見て通信相手を判断(データリンク層/レイヤー2)する。最近では、SW-HUBのコネクタ毎に、パケットにタグを付加することで、1本のネットワーク経路に仮想的な複数のネットワークを構築するタグV-LANといった方式を使う場合もある。このような機能を持つSW-HUBは特にレイヤ2スイッチとも呼ばれる。
ブリッジとルータ
サブネット分割されたネットワークをつなぐためには、ブリッジやルータが使われる。ブリッジは、MACアドレスを見て、通信相手がどちらのサブネットにいるか判断してパケットを通過させる(レイヤー2)。ルータは、IPアドレス(次の講義で解説予定)をみて、パケットの送り先を判断する。(ネットワーク層/レイヤー3)
無線LANと暗号化
無線LAN(通称 WiFi)は、IEEE 802.11 にて規格が定められている。無線LANは、使う通信周波数で、2.4GHz帯を使うものと、最近増えてきた5GHz帯のものに分けられる。
- IEEE802.11a 5GHz帯を使う、最大54Mbps
- IEEE802.11b 2.4GHz帯を使う、最大11Mbps
- IEEE802.11g 2.4GHz帯を使う、最大54Mbps
- IEEE802.11n 2.4GHz/5GHzを使う、最大600Mbps
- IEEE802.11ac 5GHz帯を使う、最大6.9GBps
2.4GHz帯は、電子レンジで使う電波の周波数と重なるため、電波干渉を受けやすい。5GHz帯は、障害物の影響を受けやすい。
無線LANに接続する場合には、接続先(アクセスポイント)に付けられた名前(SSID)と、SSIDに割り振られたパスワードが必要となる。ただし無線は、電波で信号を飛ばすため、近くに行くだけで通信を傍受できる。このため、データの暗号化が必須となる。この暗号化は、そのアルゴリズムにより解読の困難さが変わる。
- WEP 64bit / 128bit – すでに古い暗号化で専用ソフトを使うとすぐに解読される可能性が高い。使うべきではない。
- WPA/WPA2 – 現時点の主流。
無線LANでは、車でセキュリティの甘いアクセスポイント(暗号化無しやWEPを使うAP)を探し、その無線LANを使ってクラッキングなどをおこなう場合も多い。(ウォードライビング)
勝手に無線LANを使われないようにするために一般的には、(1)アクセスポイントに接続できる機器をMACアドレス(機器に割り当てられた48bitの固有値)で制限したり、(2)SSIDのステルス化(APが出す電波にSSIDを入れない方式)を行う場合も多い。ただし、これらの制限をかけても専用の機器を使えば通信は傍受可能。