sizeof(long int)
C言語のプログラミングで、型によってどの程度の数を記憶できるのかを説明することが多い。
注意して欲しい点としては、int型(32bit) = -231〜0〜231-1のあと、64bit を扱う場合はどう宣言するか。
今までは、long int は 実装により 32bit かもしれないし、64bit かもしれないので、64bit を使いたい場合は「gcc なら long long int 型を使って…」と説明していた。
しかし、説明資料を作っていたら、long int=32bit と思っていたけど、64bitだった。
改めて、最近の状況を確認したら、
- OSが “x86” なら long int = 32bit , long long int = 64bit
- OSが “x86_64” なら long int = 64bit , long long int = 64bit
なのね。
size_t 型
ちなみに、C言語では、malloc( ) に渡すメモリサイズなどは、2GB(231)を超える場合も想定する必要がある。このため、int で不具合が出る場合/出ない場合でプログラムを書き換えることがないように、size_t 型が定義されている。
実際には、以下のような typedef が #include <stdio.h>などの中で宣言されている。
((32bit)) typedef int size_t ; ((64bit)) typedef long long int size_t ;
ポインタの先には何がある?
学生さんから「ポインタの先には何があるの?」との質問があった。
私が「そのポインタの型のデータ」と答えると、さらに「ポインタはメモリの場所。でもメモリには int や char や double といった色んなデータがある。そんな色々なデータの中からデータを取り出すんだから、そこにはどんなデータが入っているのか判らないとデータを取り出せないんじゃ?」と疑問をぶつけてきた。
なるほど、本当の疑問点が見えてきた。
最近のPython等の動的型付け言語の場合
# ポインタの質問だから、C言語の場合を答えればいいんだけど…
最近の Python , PHP といった変数が型を持たない「動的型付け言語」は、まさに質問の通り。データを取り出すためには、型の情報が必要。こういう言語は、基本型以外のデータはすべて参照型(要はポインタ)なので、変数の指し示す先には型情報とそのデータがペアで保存されているので、その型情報をみてデータを取り出している。
C言語の場合(静的型付け言語)
C言語では、ポインタは単なるメモリの場所を表すだけ。ポインタの先にはデータがある。(だからデータしかないって!)
メモリからデータを読み出すときに、int 4byte で取り出すのか、 double 8byte で取り出すかどうやってわかるの?と思うかもしれないけど、そのポインタの変数がどういう型へのポインタで定義されているかプログラムを読めばわかる。それに従って取り出せばいい。こういう言語は「静的型付け言語」という。
となると「じゃあ int のデータを char として読めるの?」と思うかもしれないけど「読めるよ!」
#include <stdio.h>
int main() {
// 型を偽って参照するのは間違いの元なので型のチェックは厳格。
// だから 以下の様なヤバイことをする時は、型キャスト で
// だますことが定番。
int x = 0x41424344 ;
char* p = (char*)( &x ) ; // int型の場所をchar型にする
printf( "%c\n" , *p ) ;
// int型は4バイト、次のアドレスは?
int y[] = {
0x11223344 , 0x12345678 ,
} ;
printf( "%p %p\n" , y , y + 1 ) ;
int *r = y + 1 ;
printf( "%04d\n" , *r ) ; // 12345678 が表示
// intの1byteとなりをintとして読める?
int *q = (int*)((char*)( &y ) + 1) ;
printf( "%04x\n" , *q ) ; // 処理系によってはメモリエラー
// ポインタは番地を表す数値だよね?
// 0x100番地のデータは読める?
int* s = (int*)0x100 ;
printf( "%d\n" , *s ) ; // Segmentation Fault.
return 0 ;
}
さて、上記のプログラムをみてどう思った?
C言語って自由奔放で、やばくね? — ポインタなんか使えるからだよね、そう思うんなら Java 使え。ポインタなんか使えないから。
でも型宣言が面倒なんだよね — Python, Ruby などの動的型付けな言語使え。
でも変数参照でいちいち型情報しらべる言語って遅くね? — あるよ。「型推論」。型を明記しなくても、プログラムの文脈から型を推論してくれる静的型付け言語。Go , Swift , Kotlin…といった、今 流行りのプログラム言語がソレ。最新のJavaやC++も型推論機能が使えるようになってるよ。んで、今話題の中学生が作ったプログラム言語 Blawn も、型推論の言語!すげーな。
const char*s, char* const sの違い
専攻科実験のサンプルコードで、警告がでたことについて質問があったので説明。
(( サンプルコード sample.cxx ))
#include <stdio.h>
void foo( char* s ) {
printf( "%s¥n" , s ) ;
}
int main() {
foo( "ABC" ) ;
return 0 ;
}
(( コンパイル時の警告 ))
$ g++ sample.cxx
test.cxx:6:6: warning: conversion from string literal
to 'char *' is deprecated
[-Wc++11-compat-deprecated-writable-strings]
foo( "abcde" ) ;
^
1 warning generated.
警告を抑止する “-Wno-…” のオプションをつけて “g++ -Wno-c++11-compat-deprecated-writable-strings sample.cxx” でコンパイルすることもできるけど、ここは変数の型を厳格にするのが鉄則。
この例では、引数の “ABC” が書き換えのできない定数なので、const キーワードを付ければよい。ただし、宣言時の const の付け場所によって、意味が違うので注意が必要。
void foo( char const* s ) { // const char* s も同じ意味 *s = 'A' ; // NG ポインタの先を書き換えできない s++ ; // OK ポインタを動かすことはできる } void foo( char *const s ) { *s = 'A' ; // OK ポインタの先は書き込める s++ ; // NG ポインタは動かせない } void foo( char const*const s ) { *s = 'A' ; // NG ポインタの先を書き換えできない s++ ; // NG ポインタは動かせない }
const を書く場所は?
int const x = 123 , y = 234 ; の場合、yは定数だろうか?
(( おまけ ))
#include <stdio.h>
int main() {
int const x = 123 , y = 234 ; // x は定数だけど yは定数?
x++ ; // 予想通りエラー
y++ ; // yも定数なのでエラー
int const s = 345 , const t = 456 ; // sもtも明らかに定数っぽい
// ^ここで文法エラー
// おまけのおまけ
char* s , t ; // s は文字へのポインタ、t は文字
char *s , *t ; // s は文字へのポインタ、t も文字へのポインタ
return 0 ;
}
hogeはメタ構文変数
成績締め切りも近い中、レポートの出ない学生さんに確認したら、メールで送ったそうな。届いてないので確認してもらったら、前記事の福井高専のドメイン名の説明で、hoge@fukui-nct.ac.jp と書いてあったのを私の正式メールアドレスと勘違いしたらしい。
“hoge” は、正式にはメタ構文変数というけど、人に例として説明するときの適当につける名前(例えば太郎とか花子)。英語圏では、foo , bar , baz を使い、私もプログラム例では、foo() を使う。
んで hoge は、日本で使われるメタ構文変数で、hoge, fuga, piyo かな。
由来は、諸説色々あるけど個人的には、バラエティ番組の「ぴったしカンカン」で、司会者の久米宏が伏せ文字的に「◯◯は…」みたいなのを「hogehogeは…」みたいに話したのが元だと思ってる。
piyo は「めぞん一刻」の大家さんのエプロンだろうな。

CTF講座・K-SEC第3ブロック学生向け講習会に参加
高専機構の情報セキュリティ人材育成プロジェクトの一環として、岐阜大学サテライトキャンパス(岐阜高専主幹)にて8/28(水)に開催された、CTF講座・K-SEC第3ブロック学生向け講習会に3EI学生1名が参加しました。
CTFとは
CTFとは、Capture The Flags という、情報セキュリティの知識を使ってクイズを解く競技です。
例えば、簡単なものでは、
- PGS{fnzcyr} からフラグを見つけよ。# rot13暗号化
- SQLインジェクションでデータ漏洩が発生するWebシステムが用意されていて、SQLインジェクションが発生するようなデータを入力させて情報を見る。
といった問題があります。複雑な問題では、
- C言語で生成された機械語があって、通常では何も表示されないけど、逆アセンブルして条件判断の一部をバイパスさせて、データを表示させる。
といった、OSや機械語の知識が要求されるものもあります。
初心者には大変だったかな
今回、4年はインターンシップなどで参加者があつまらず、初心者の3年の学生さんに参加してもらいました。CTFの初心者向け講習会ということで、基礎的演習もあるかと思いましたが、いきなりの簡易版CTF大会となりました。知識が不足していて、苦労していましたが基礎的問題をいくつか解けていたようです。

最後に、講習会の修了証をもらいました。

簡単テストの解説
前に実施した簡単テストの答え。
キーワードの理解
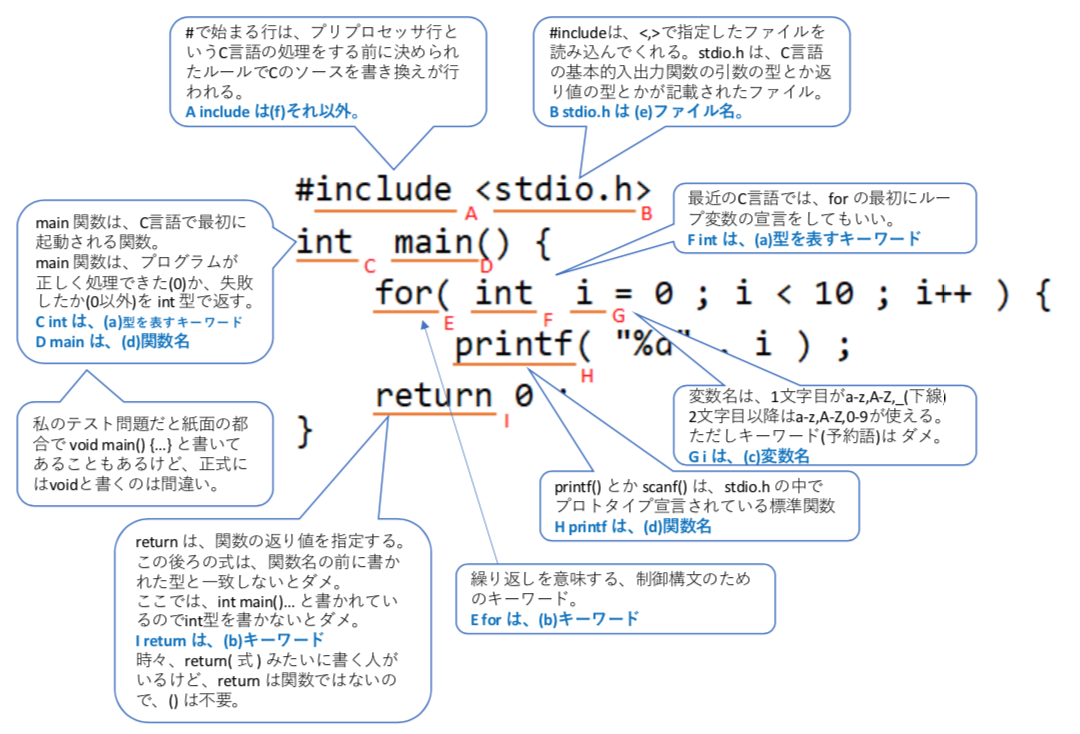
型の理解
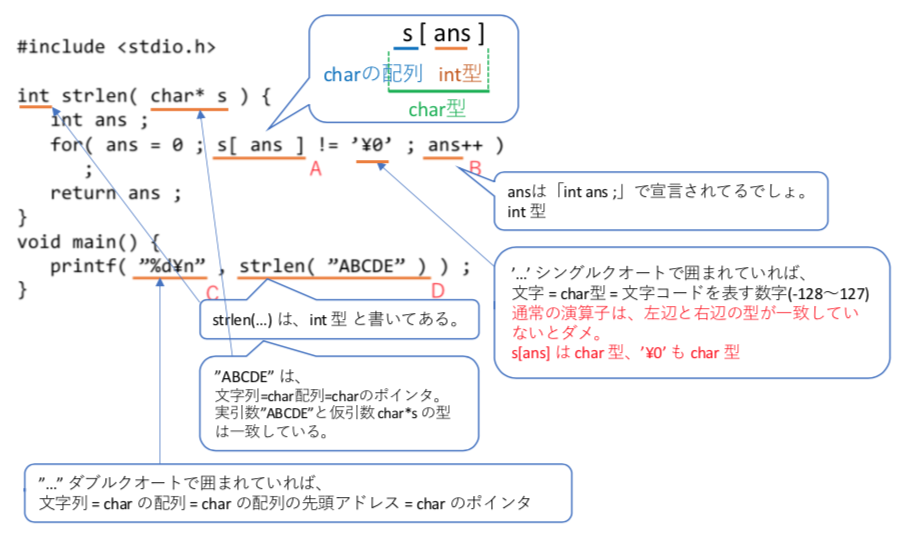
上記の問題だけでは、説明しきれないので、下図左のプログラムと、その printf() で表示するデータの型を示す。
型の意味を考えたうえで、何が表示されるか考えよう。

関数の理解
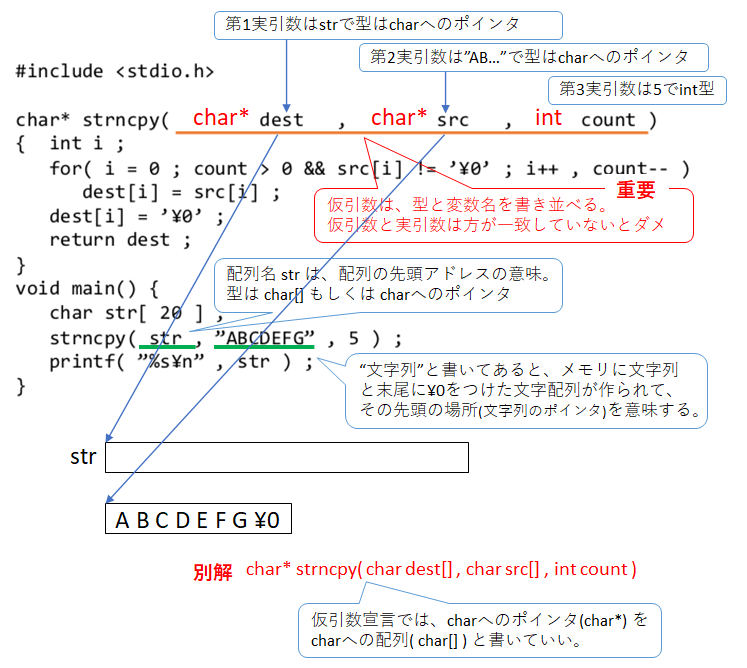
簡単テスト
情報構造論のテストにて結果は両極端な成績。苦手な人は基本理解が怪しいみたい。ということでC言語の理解の確認。
キーワードの理解
以下のプログラムの下線部 A-I の各単語を説明するのにふさわしいものを、(a)~(f)で選べ。キーワードは予約語と呼ばれることも多い。

(a) 型を表すキーワード、(b) キーワード、(c) 変数名、
(d) 関数名、(e) ファイル名、(f) それ以外
解答欄
A_____, B_____, C_____, D_____, E_____,
F_____, G_____, H_____, I_____
型の理解
以下のプログラムの下線部 A-D の型を答えよ。

(a) int , (b) int型へのポインタ, (c) char, (d) char型へのポインタ, (e) void
解答欄
A_____, B_____, C_____, D_____
関数の理解
以下のように、文字列を src から dest にコピーする(ただし最大文字数 countまで) strncpy を作った。
この関数の下線に示す仮引数部分を完成せよ。
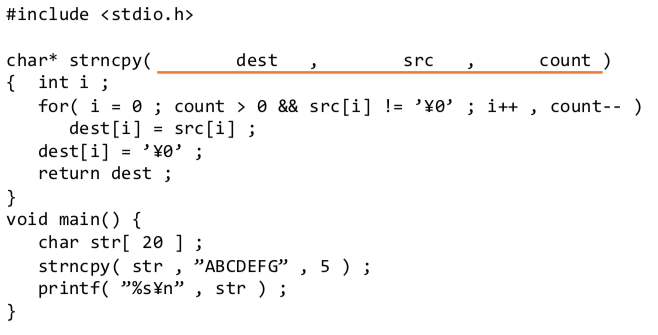
解答欄________________________________
構造体を使ったプログラム例
今日はテスト前で、構造体の全体的な説明も終わり、演習の時間。 以下のようなオブジェクト指向の考え方を取り入れた、 構造体ポインタ渡しのスタンダードなプログラムを示す。
#include <stdio.h>
#define SIZE 10
struct Person {
char name[ 20 ] ;
int age ;
} ;
int read_Person( struct Person* p ) {
return scanf( "%s%d" , p->name , &(p->age) ) == 2 ;
}
void print_Person( struct Person* p ) {
printf( "%s %d\n" , p->name , p->age ) ;
}
int main() {
int i , size ;
struct Person table[ SIZE ] ;
// データの入力処理
for( i = 0 ; i < SIZE ; i++ ) {
if ( !read_Person( &( table[i] ) ) )
break ;
}
size = i ;
// データの出力処理
for( i = 0 ; i < size ; i++ )
print_Person( &( table[i] ) ) ;
return 0 ;
}
ファイル入出力にも慣れてもらおう
#include <stdio.h>
#define SIZE 10
struct Person {
char name[ 20 ] ;
int age ;
} ;
int read_Person( struct Person* p , FILE* fp ) {
return fscanf( fp , "%s%d" , p->name , &( p->age ) ) == 2 ;
}
void print_Person( struct Person* p , FILE* fp ) {
fprintf( "%s %d\n" , p->name , p->age ) ;
}
int main() {
int i , size ;
struct Person table[ SIZE ] ;
FILE* fp_in ;
if ( (fp_in = fopen( "data.txt" , "rt" )) != NULL ) {
for( i = 0 ; i < SIZE ; i++ )
if ( ! read_Person( &( table[i] ) , fp_in ) ) {
size = i ;
break ;
}
for( i = 0 ; i < size ; i++ )
print_Person( &( table[i] ) , stdout ) ;
}
return 0 ;
}
オブジェクト指向っぽく
#include <stdio.h>
#define SIZE 10
class Person {
private:
char name[ 20 ] ;
int age ;
public:
int read() {
return scanf( "%s%d" , name , &age ) == 2 ;
}
void print() {
printf( "%s %d\n" , name , age ) ;
}
} ;
int main() {
int size ;
Person table[ SIZE ] ;
for( int i = 0 ; i < SIZE ; i++ )
if ( !table[i].read() ) {
size = i ;
break ;
}
for( int i = 0 ; i < size ; i++ )
table[i].print() ;
return 0 ;
}
今日のプログラミング応用のテスト問題
今日の、本科3年のプログラミング応用のテスト問題。
# テスト後、「先生、ポケモンGOやってるんですか?」
今から、明日の専攻科2年オブジェクト指向プログラミングの問題作るぞ。 当然、ポケモンの「進化」ネタだよな。

安全な入力とdefineマクロ
ファイル処理の最後の説明で、バッファ・オーバーフローと、安全な入力について説明。
安全な入力
一般的なC言語での文字列入力のプログラムは、以下の様なものがテキストにも書かれている。
// memory
// [局所変数str][戻り番地][..........]
void foo() {
char str[ 10 ] ;
scanf( "%s" , str ) ;
}
バッファオーバーフロー
しかし、こういった処理は極めて危険である。 入力の際に、10文字以上のデータが入力された場合、 一般的な処理系では、str[] の配列の近辺に 「関数foo()の実行後に戻る処理の番地」が格納されている場合が多く、 文字列をはみ出るような入力があった場合、処理番地を書き換えられる可能性がある。 悪意のあるプログラマーは、はみ出す領域に、戻り番地を書き換えるデータと、悪意のある処理を 書くことで、想定外の処理を動かすかもしれない。 このテクニックをバッファオーバーフローと呼ぶ。
このため、最大文字制限の機能を使い、以下のように記述すべきである。
char str[ 10 ] ; scanf( "%9s" , str ) ;
しかし、scanf() には、空白を読み飛ばす機能により「入力が無い場合…」といった 処理が書きにくい、%d入力で実数の"."や文字列を間違って入力したときの処理などの 問題があって、scanf() 単体で複雑な入力に対応することは極めて難しい。
fgets() + sscanf()
このような場合によく使われるのが、fgets()とsscanf()である。
fgets() は、文字配列に1行分のデータ(行末文字"¥n"まで)を、文字配列に読み込む関数である。 また、sscanf() は、文字配列のデータから、scanf() と同じようにデータを読み込む。
FILE* fp ;
if ( (fp = fopen( "data.txt" , "rt" )) != NULL ) {
char buff[ 100 ] ;
while( fgets( buff , sizeof( buff ) , fp ) != NULL ) {
int x ;
double y ;
char z[100] ;
if ( sscanf( buff , "%d%lf%s" , &x , &y , z ) != 3 )
break ;
// x , y , z を使った処理
}
fclose( fp ) ;
}
fgets() は、第一引数に、読み込み先の配列アドレス、第2引数に最大読み込みバイト数、第3引数に 読み元のファイルを指定する。文字配列への読み込み時には、第2引数のサイズを超えて 読み込むことはしないので、バッファオーバフローの心配はない。 また、入力データが無い場合には、NULL を返す。
sizeof()は、引数部分の変数のバイト数を返す演算子。
sscanf() は、データの入力が、第一引数の文字列から読み込む以外は、 scanf(),fscanf() と同じ使い方。
注意:fgets では、入力が最大バイト数以下の場合、行末文字まで読み込む。
Tips: 入力が無かったら(空行なら)、標準入力(通常キーボード入力)なら
char buff[ 1024 ] ;
while( fgets( buff , sizeof( buff ) , stdin ) != NULL ) ) {
// stdin は、標準入力(通常キーボード)
if ( buff[ 0 ] == '¥n' ) {
// 入力が空行だった場合
}
}
fscanf()にfprintfがあるように、sscanfに対してsprintfもある。
char buff[ 1024 ] ; sprintf( buff , "%d %5.1lf %s" , 12 , 34.5 , "abc" ) ; // buff = "12 34.5 abc"となる。
#defineマクロ
scanfで"%d"で数字を入力する際に、文字を入力されると、あとの処理が書きにくい場合が多い。 この場合、fgetsで入力し入力データが正しい文字を使っているかチェックしてから、 sscanf()を使うなどの対処をとることが多い。 ここで、#define マクロを使ってみる
#include <stdio.h>
#define isdigit(C) ((C)>='0' && (C)<='9')
void main() {
char buff[ 1024 ] ;
while( fgets( buff , sizeof( buff ) , stdin ) != NULL ) {
char* pc ;
for( pc = buff ; *pc != '¥0' && isdigit( *pc ) ; pc++ )
/*nothing*/ ;
if ( *pc == '¥n' || *pc == '¥0' ) {
int x ;
sscanf( buff , "%d" , &x ) ;
}
}
}
#define は、通常プログラム中の定数を分かりやすく使う場合に、使われる。
#define PI 3.14159265
ただし、#で始まる行は、C言語によって特殊で、C言語の解析の前に「プリプロセッサ」 でプログラムの内容を書き換える機能。
C言語のプログラムが機械語になるまで:
C言語(#行を含む) ↓ プリプロセッサ C言語(#行なし) ↓コンパイル 中間コード(printfなどの標準関数などが未解決) ↓ リンク処理 ← ライブラリ(標準関数などの中間コードをまとめたもの) ↓ 機械語
#define マクロでは、isdigit() の引数? C が、呼び出し部の *pc となり、 isdigit( *pc ) の部分は、以下のように書き換えられる。
((defineマクロ宣言)) #define isdigit(C) ((C)>='0' && (C)<='9') ((デファインマクロを使ったら)) isdigit(*pc) ↓ C ← *pc ((*pc)>='0' && (*pc)<='9')
ただし、#defineマクロは、プログラムのコンパイル前に、文字列として書き換えを行う。
// 例1
#define begin {
#define end }
void main() // まるでPASCALのような記述(^_^;
begin
printf( "Hello¥n" ) ;
end // 正しく動くよ
// 例2
#define ADD(X,Y) X + Y
#define MUL(X,Y) X * Y
void main() {
printf( "%d" , MUL( 3 , ADD( 4 , 5 ) ) ) ;
}
// 3 * 4 + 5 に書き換えられるので、17になる。
// 3 * (4+5) の27にはならない。
// 普通の関数のように27の結果が欲しいなら、
// #define ADD(X,Y) ((X)+(Y))
// #define MUL(X,Y) ((X)*(Y))
// と書くべき。
開いた関数と閉じた関数
#defineマクロは、定義しておいた命令への書き換えなので、関数と同じように思うかもしれない。 ただし、機械語を生成する処理の前に書き換えるので、#define マクロで書き換えられる処理が 長い場合は、生成される機械語が大きくなる場合がある。 一方で、#defineマクロを使うと引数の受け渡しが無いので、 isdigit()のような簡単な処理の場合、 生成される機械語の処理が少し速い。
// 開いた関数FOO
#define FOO(X) Xを使った処理
void main() {
int x ;
FOO(x) ; // xを使った処理
FOO(x) ; // xを使った処理
// FOOの中身が長い場合、FOOの機械語が2個作られる。
}
// 閉じた関数foo
int foo(int z) {
zを使った処理
:
:
}
void main() {
int x ;
foo(x) ; // z←x,fooを呼び出し
foo(x) ; // z←x,fooを呼び出し
// fooの機械語は1個だけ,引数の受け渡し処理が2個
}
#defineマクロのADD,MULの優先順位の問題が、"醜い"と思う人は、 C++で新しく導入された、"inline"関数を勉強すること。 #defineマクロを使わずに、開いた関数を簡単に記述できる。